Downloaded 16 times




![NonStop Advanced Technology Center
An introduction to Embedded SQL for NonStop SQL/MX -5-
The mxCompileUserModule program invokes the SQL/MX compiler and will now create a
module in the local directory due to the –g moduleLocal option. It is even possible to
specify a specific directory to place the modules. That is useful, however, it requires that this
directory needs to be defined in an environment variable when the program is executed or else
the module will not be found. The environment variable, called _MX_MODULE_SEARCH_PATH,
is used as a search path and needs to contain the names of the directories to search for
modules, similar to the PATH and CLASSPATH variables. This paper will use discuss co-
located modules, where program and module are placed in the same directory.
Controlling the module names
Automatically generated module names are easy for a developer, but it will burden a system
administrator with the task of removing stale modules2
. It may therefore be better to explicitly
name the modules and let SQL/MX add the catalog and schema names to the name, since it is
useful to know to which schema a module belongs.
With the simple 2-step example, the module name can be defined with a DECLARE MODULE
statement in the program source. The example also uses DECLARE statements to define the
catalog and schema that the program will use.
The name of the module is defined along with the other data fields, while the catalog and
schema are defined later in the PROCEDURE DIVISION of the program.
EXEC SQL BEGIN DECLARE SECTION END-EXEC.
* The MODULE statement will cause a module created
* named <cat>.<sch>.SAMPL in the module directory
EXEC SQL MODULE "SAMPL" END-EXEC.
….. data definitions
…..
PROCEDURE DIVISION.
…..
EXEC SQL DECLARE CATALOG 'frans' END-EXEC.
EXEC SQL DECLARE SCHEMA 'perf' END-EXEC.
When this code is compiled, a module called FRANS.PERF.SAMPL is created, either in the
default (global) directory, or in the local directory if the moduleLocal option is used. When
2 Note: The mxci command DISPLAY USE OF SOURCE [‘module name’] will show the source file
belonging to this module. In case of stale modules, multiple modules will be referring to the same source
file. See the SQL/MX Reference Manual for information about the DISPLAY USE OF …. Command.](https://image.slidesharecdn.com/introductiontoembeddedsqlfornonstopsql-191120141458/85/Introduction-to-embedded-sql-for-NonStop-SQL-5-320.jpg)

![NonStop Advanced Technology Center
An introduction to Embedded SQL for NonStop SQL/MX -7-
* Get the record layout of PARTS
EXEC SQL INVOKE PARTS END-EXEC.
….. data definitions
…..
PROCEDURE DIVISION.
…..
* In reality, these lines are not present in the source.
* EXEC SQL DECLARE CATALOG 'frans' END-EXEC.
* EXEC SQL DECLARE SCHEMA 'perf' END-EXEC.
…..
To compile the program we use three steps, the preprocessor, the language processor and the
SQL compiler. The precompiler for COBOL, mxsqlco, uses value of moduleSchema to
create the name of the module and the –Q invokeSchema value to retrieve the record
definition of the PARTS table. And produces the generated COBOL source in sampl3.cbl. This
is input to the language compiler.
mxsqlco -g moduleSchema=frans.perf -Q invokeSchema=frans.perf
sampl3.ecob
xcobol -Wsqlmx -o sampl3 sampl3.cbl
mxCompileUserModule -g moduleLocal –d schema=frans.perf sampl3
The final step, mxCompileUserModule, creates the modules locally (this means they are
not created I the SQL/MX USERMODULES directory), and uses the schema name to get the
information it needs to compile an execution plan.
The next sequence of events show how the program can be targeted to use a new schema. In
this example, a row will be inserted in the PERF.PARTS table, but it will fail on a duplicate key
exception. The program shows the full name of the table, which includes the schema it
accesses. Then the only the module is recompiled to use the HR schema and the program
outpur shows that the same business code in sampl3 will access the HR.PARTS table.
~/compile> ./sampl3
This example uses a static cursor.
Enter lowest part number to be retrieved:
11
sqlerrors: 23000, -000008102
Table : FRANS.PERF.PARTS
Column :
SQLSTATE: 23000
Message : *** ERROR[8102] The operation is prevented by a
primary key PARTS_564349585_9263 on table FRANS.PERF.PARTS.](https://image.slidesharecdn.com/introductiontoembeddedsqlfornonstopsql-191120141458/85/Introduction-to-embedded-sql-for-NonStop-SQL-7-320.jpg)
![NonStop Advanced Technology Center
An introduction to Embedded SQL for NonStop SQL/MX -8-
Create a module to use the frans.HR schema.
~/compile> mxCompileUserModule -g moduleLocal -d schema=frans.HR
sampl3
Run the same executable
~/compile> ./sampl3
This example uses a static cursor.
Enter lowest part number to be retrieved:
11
sqlerrors: 23000, -000008102
Table : FRANS.HR.PARTS
Column :
SQLSTATE: 23000
Message : *** ERROR[8102] The operation is prevented by a
primary key PARTS_118992335_3782 on table FRANS.HR.PARTS.
~/compile>
This example shows the method to move binary programs from one system to another and only
the module files need to be recompiled on the target database.
Note however, that this example uses a module called FRANS.PERF.SAMPL even though it
can access the PARTS table in schema PERF or HR. The first two parts of the module name
represent a catalog and schema, however, this is only a convention. The next example shows
how to control the complete module name.
Example 4, combined module control and schema flexibility
In this example, modules have names that do not include a catalog or schema, since the
application business code can run in different environments (for example development, test,
integration and production). Instead, in this example, the catalog and schema parts of the
module name are used for application name and version5
.
Important note: Do not use special characters (especially period) in the module name. While
the program may execute fine with such a module, the mxci DISPLAY USE OF commands
expect a three part name, with a “.” as separation character.
5 Including the version number in a module is used as an example of how one might organize modules.
Lifecycle version information might also be kept in source control systems such as git.](https://image.slidesharecdn.com/introductiontoembeddedsqlfornonstopsql-191120141458/85/Introduction-to-embedded-sql-for-NonStop-SQL-8-320.jpg)




![NonStop Advanced Technology Center
An introduction to Embedded SQL for NonStop SQL/MX -14-
/tmp/AAAqaabWa197661ACICCH
(/usr/tandem/sqlmx/USERMODULES/FRANS.PERF.SQLMX_DEFAULT_MODULE_2597235
31183946022)
0 errors, 0 warnings, 0 statements affected; 17 statements total
1 modules found, 1 modules extracted.
1 mxcmp invocations: 1 succeeded, 0 failed.
xcobol: /usr/tandem/sqlmx/bin/mxCompileUserModule exited, returning 0.
xcobol: Exiting with status 0; 0 error(s).
~/compile>
Example 1 COBOL source code
This sample program is a slightly changed copy of the example from the SQL/MX 3.6
Programming Manual for C and COBOL. The change is the addition of the INSERT statement
right before the cursor is opened. Note that duplicate keys will cause an error, this error is used
to show that the examples can run the same code on different schemas.
* ---------------------------------------------------------------
* compile this program simply in OSS with:
* [x|e]cobol -Wsqlmx -Wmxcmp sampl.ecob -o sampl –Wverbose
*
* Description: Using a Static SQL Cursor
* Statements: Static DECLARE CURSOR
* BEGIN WORK
* OPEN
* FETCH
* Positioned UPDATE
* CLOSE
* COMMIT WORK
* WHENEVER
* GET DIAGNOSTICS
*---------------------------------------------------------------
* Table definition
* CREATE TABLE PARTS
* (
* PARTNUM NUMERIC(4, 0) UNSIGNED NO DEFAULT HEADING
* 'Part/Num' NOT NULL
* , PARTDESC CHAR(18) CHARACTER SET ISO88591 NO
* DEFAULT HEADING 'Part Description' NOT NULL
* , PRICE NUMERIC(8, 2) NO DEFAULT HEADING 'Price'
* NOT NULL
* , QTY_AVAILABLE NUMERIC(5, 0) DEFAULT 0 HEADING
* 'Qty/Avail' NOT NULL
* , ORDER_DATE DATE DEFAULT CURRENT_DATE
* , PRIMARY KEY (PARTNUM ASC)
* )
* ;
* --- SQL operation complete.
*](https://image.slidesharecdn.com/introductiontoembeddedsqlfornonstopsql-191120141458/85/Introduction-to-embedded-sql-for-NonStop-SQL-14-320.jpg)




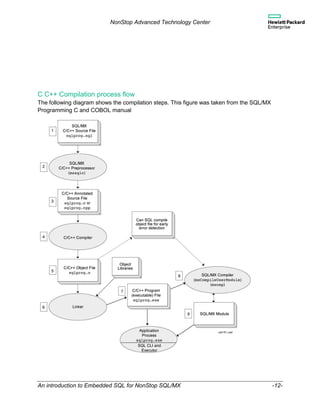
This document provides an introduction to using embedded SQL for NonStop SQL/MX. It discusses the compilation process which involves preprocessing SQL statements, compiling the host language code, and compiling the SQL to generate an execution plan stored in a module file. It provides examples of simple compilation and controlling the module names and locations. The goal is to help new SQL/MX users get started quickly with embedded SQL.






















![[Www.pkbulk.blogspot.com]dbms07](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms07-130615034615-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





































