Download as PDF, PPTX












![SQL/MX 3.5: Database Services
17
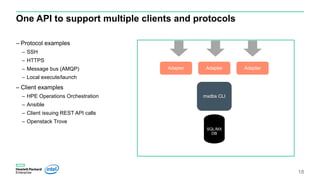
DBS thin provisioning interface
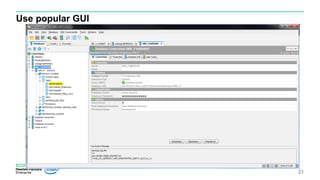
mxdbs CLI
Create a database
Share a database
Delete a database
Add more storage
Add additional users
Change user’s access level
Change user’s password
Delete a user
Show databases
usage: mxdbs [-h] [-V]
{ db-create | db-alter-share | db-delete | db-add-user |
db-remove-user | db-add-storage | db-user-change-access |
user-change-password | show-databases } ...
The API should be kept simple, database agnostic
The goal is to cover the life cycle management scope
from long term projects to ad-hoc projects.](https://image.slidesharecdn.com/ebitug2017sqlmxdbs-171005101430/85/NonStop-SQL-MX-DBS-Explained-16-320.jpg)





The document discusses the capabilities and features of NonStop SQL/MX databases, highlighting their cloud integration, multi-tenancy, and easy database provisioning. It explains how these databases enable user isolation and automation while addressing complexities such as database sharding and management. Additionally, it outlines the database lifecycle and API functionality for user and resource management in cloud environments.

































![[Lec#4]databases and database management systems.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lec4databasesanddatabasemanagementsystems-240416150618-ad1f5ab7-thumbnail.jpg?width=640&height=640&fit=bounds)




















