Download as PDF, PPTX




































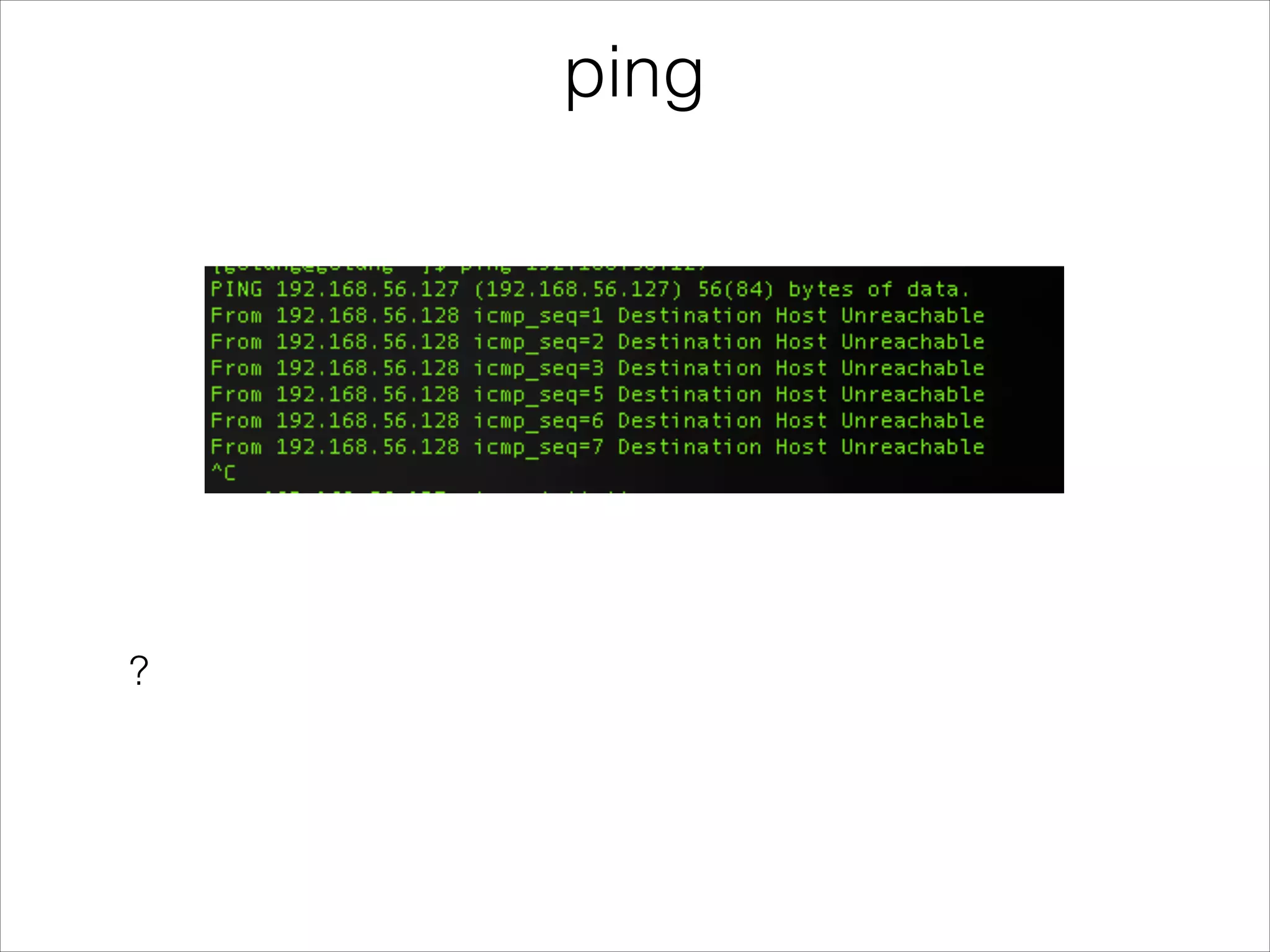

















The document discusses Linux performance analysis, emphasizing the importance of understanding what 'slow' means in terms of latency, throughput, and resource utilization. It outlines different types of performance issues such as utilization, saturation, and errors, while stressing the need for suitable tools and methods for effective analysis. The author shares various methods and tools for performance examination, advocating for a methodical approach over reliance on tools alone.



















































































