Download as PDF, PPTX























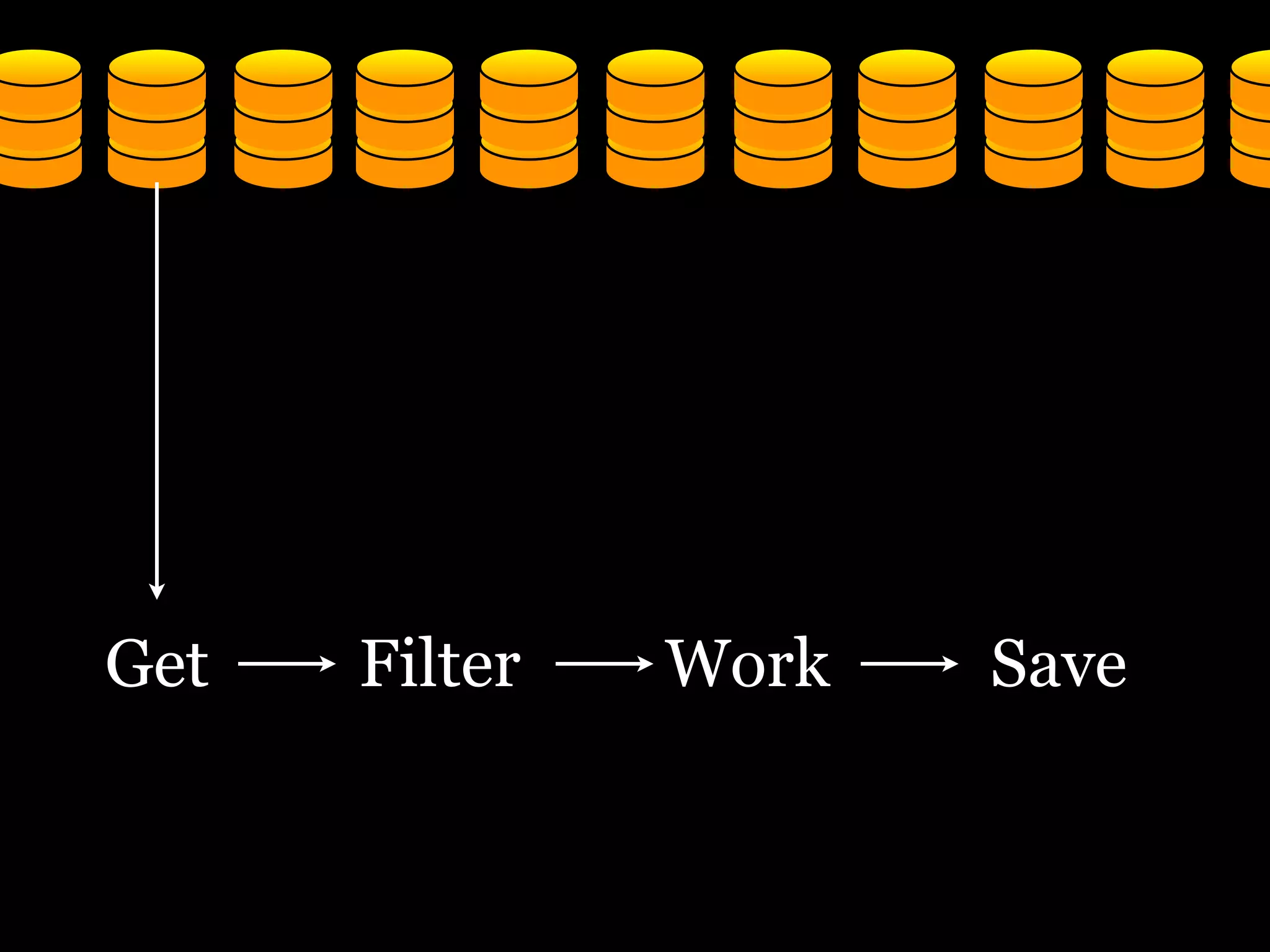


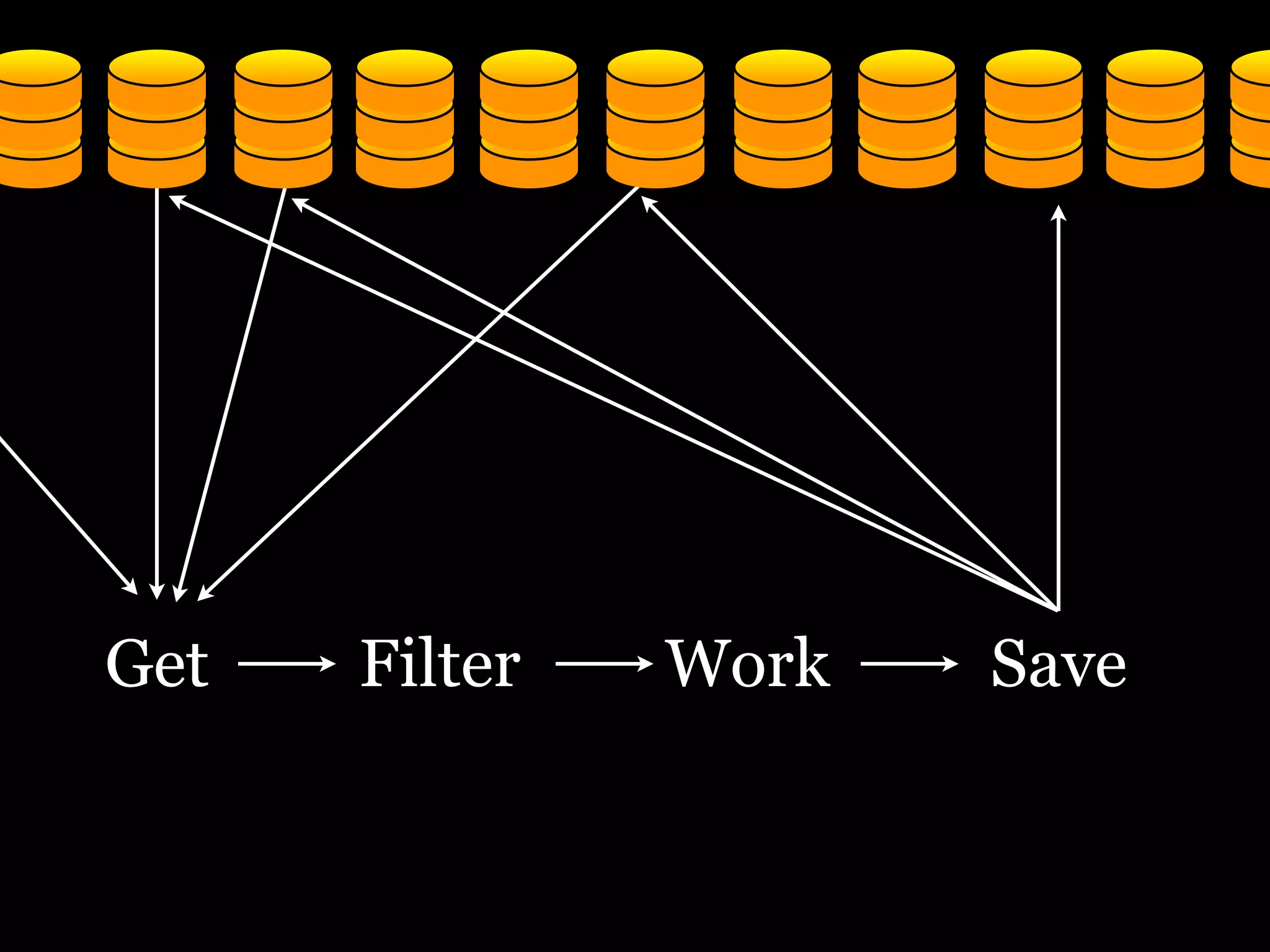


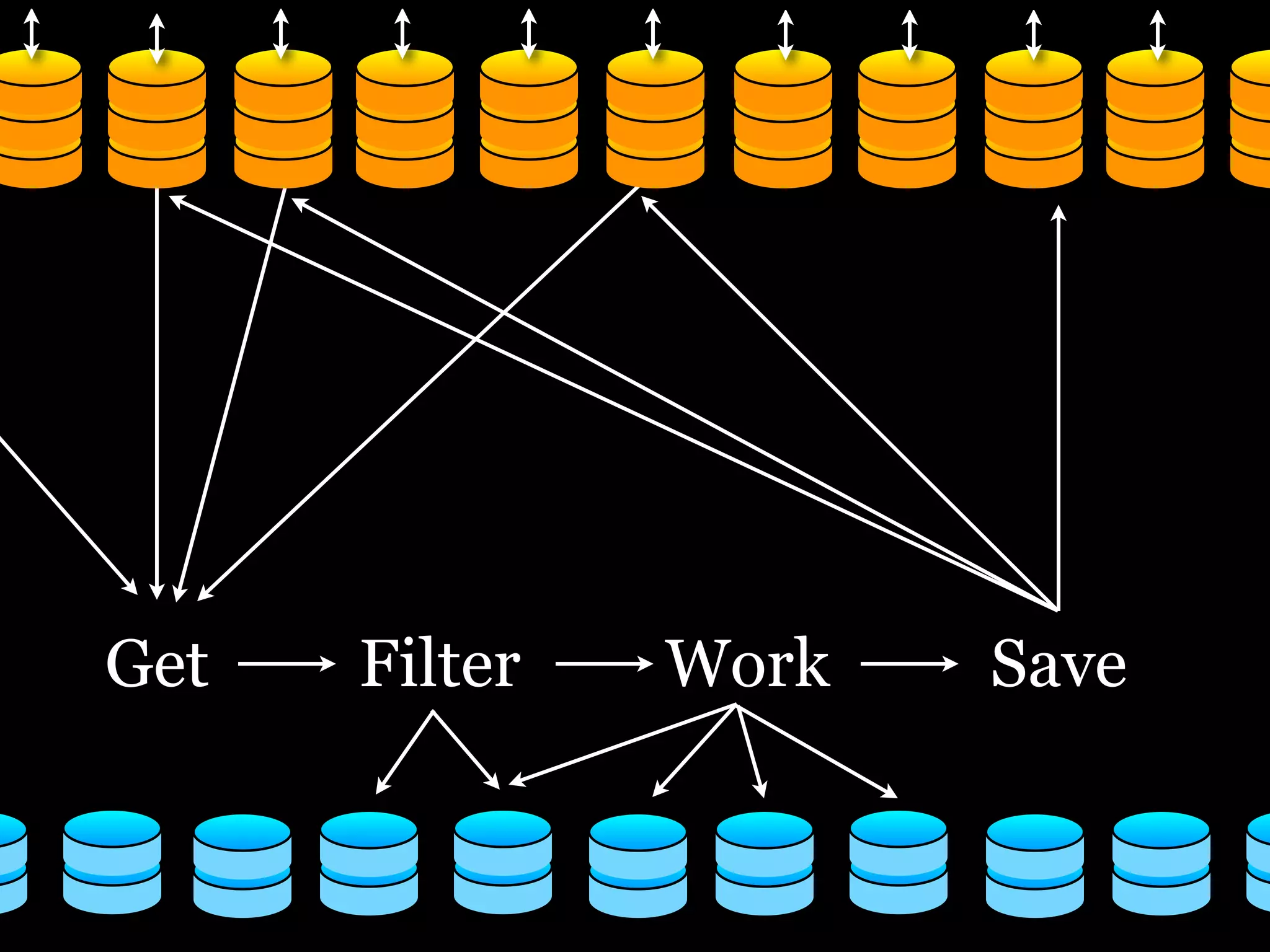
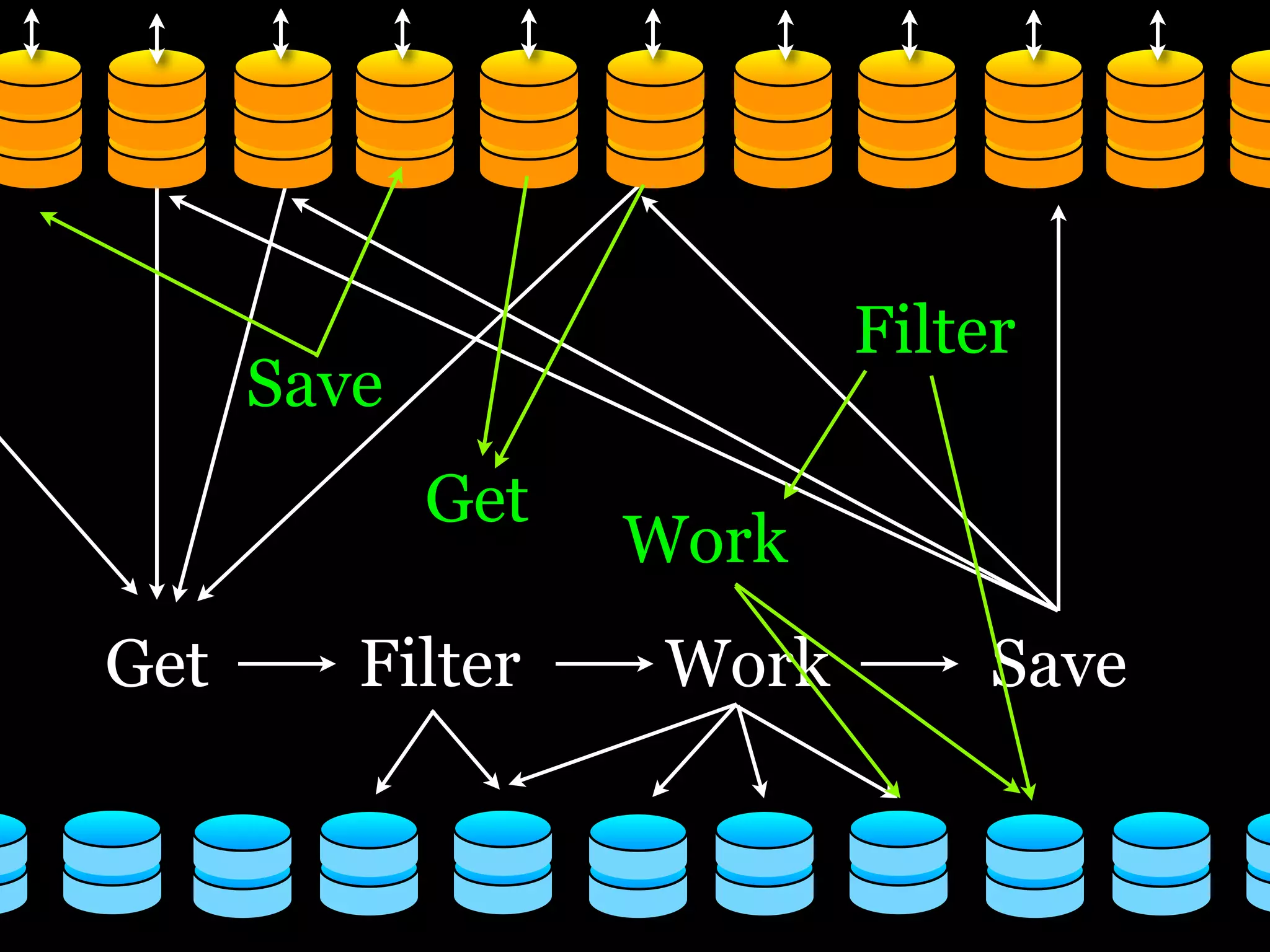




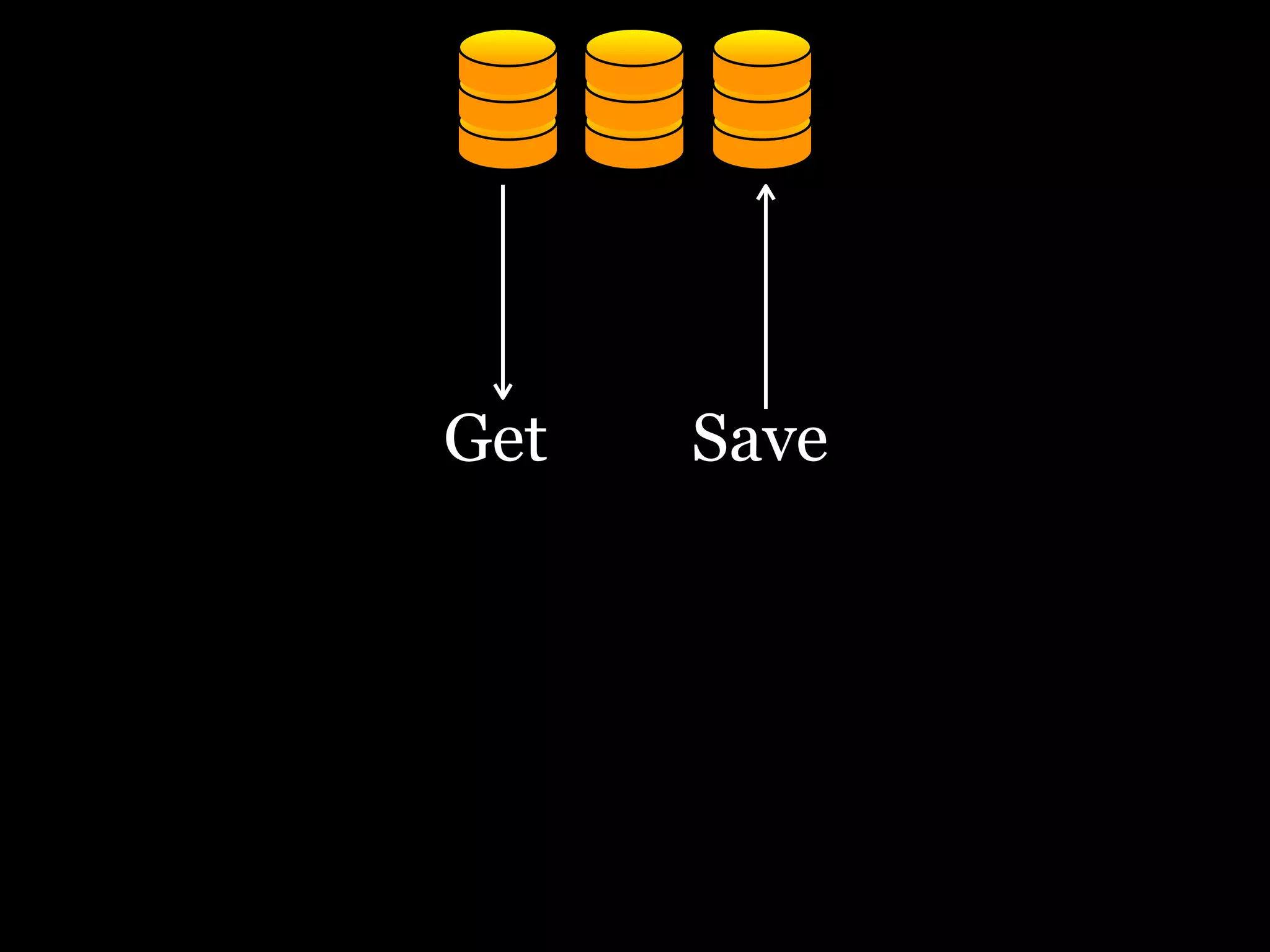
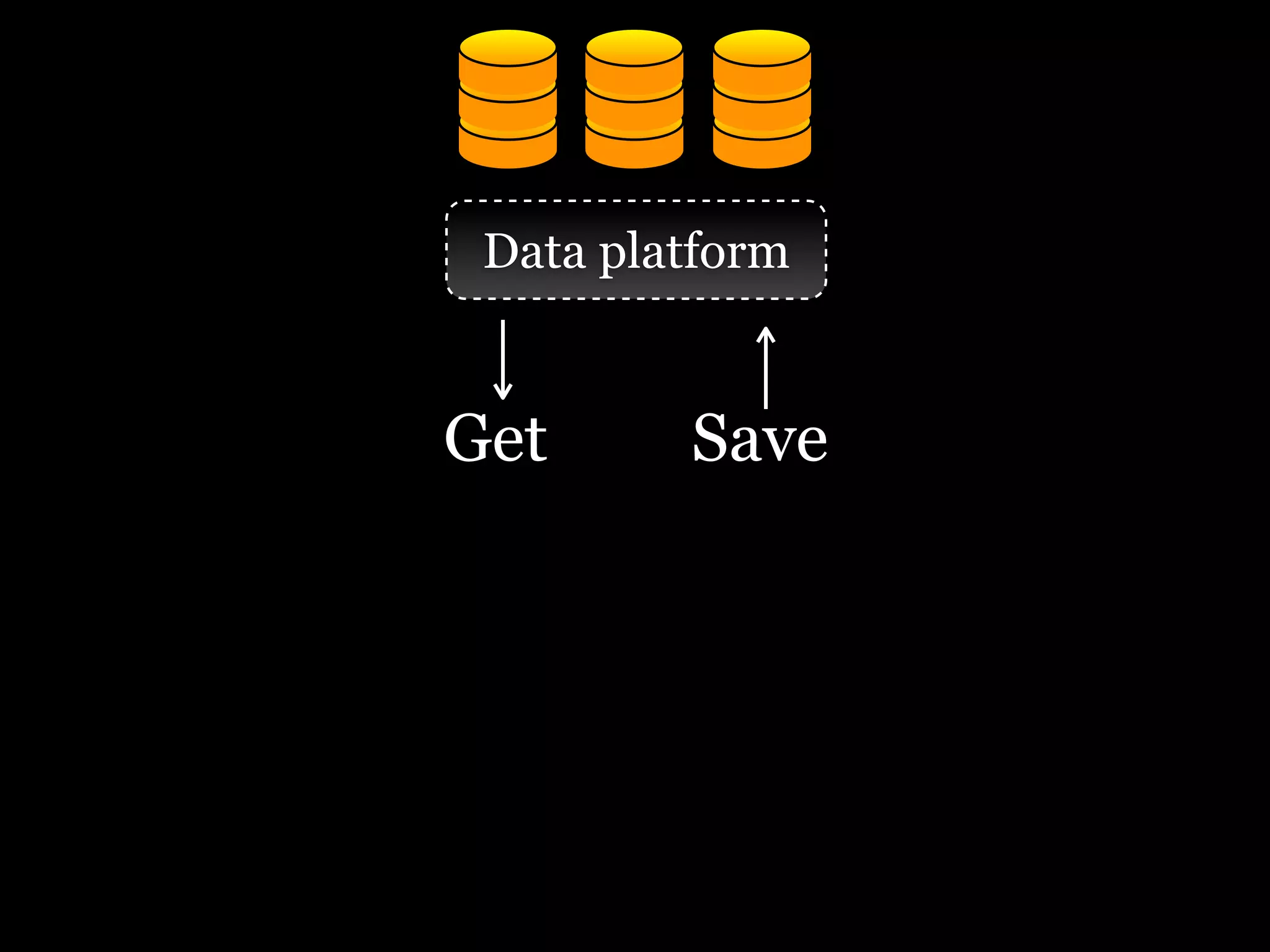




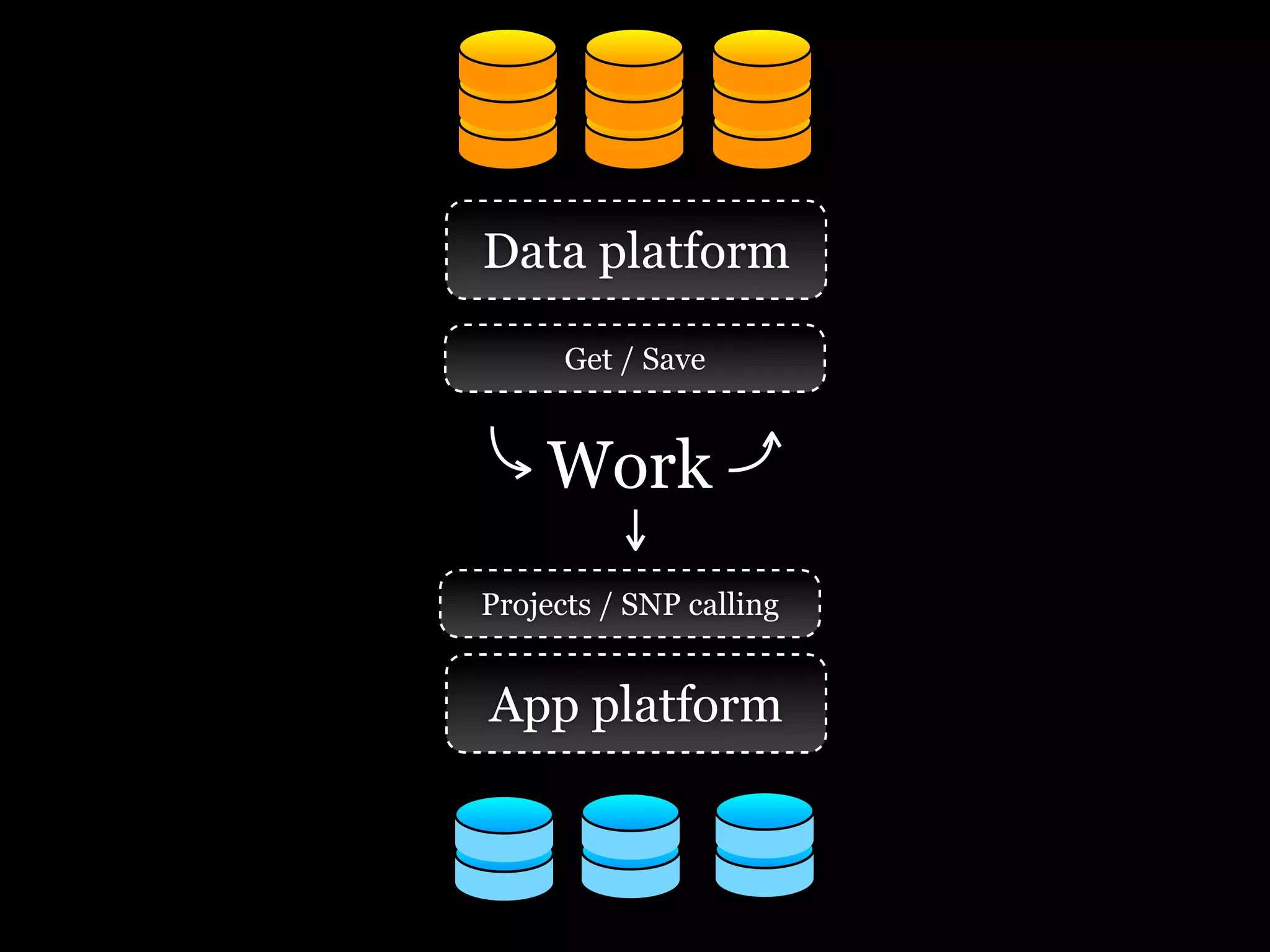







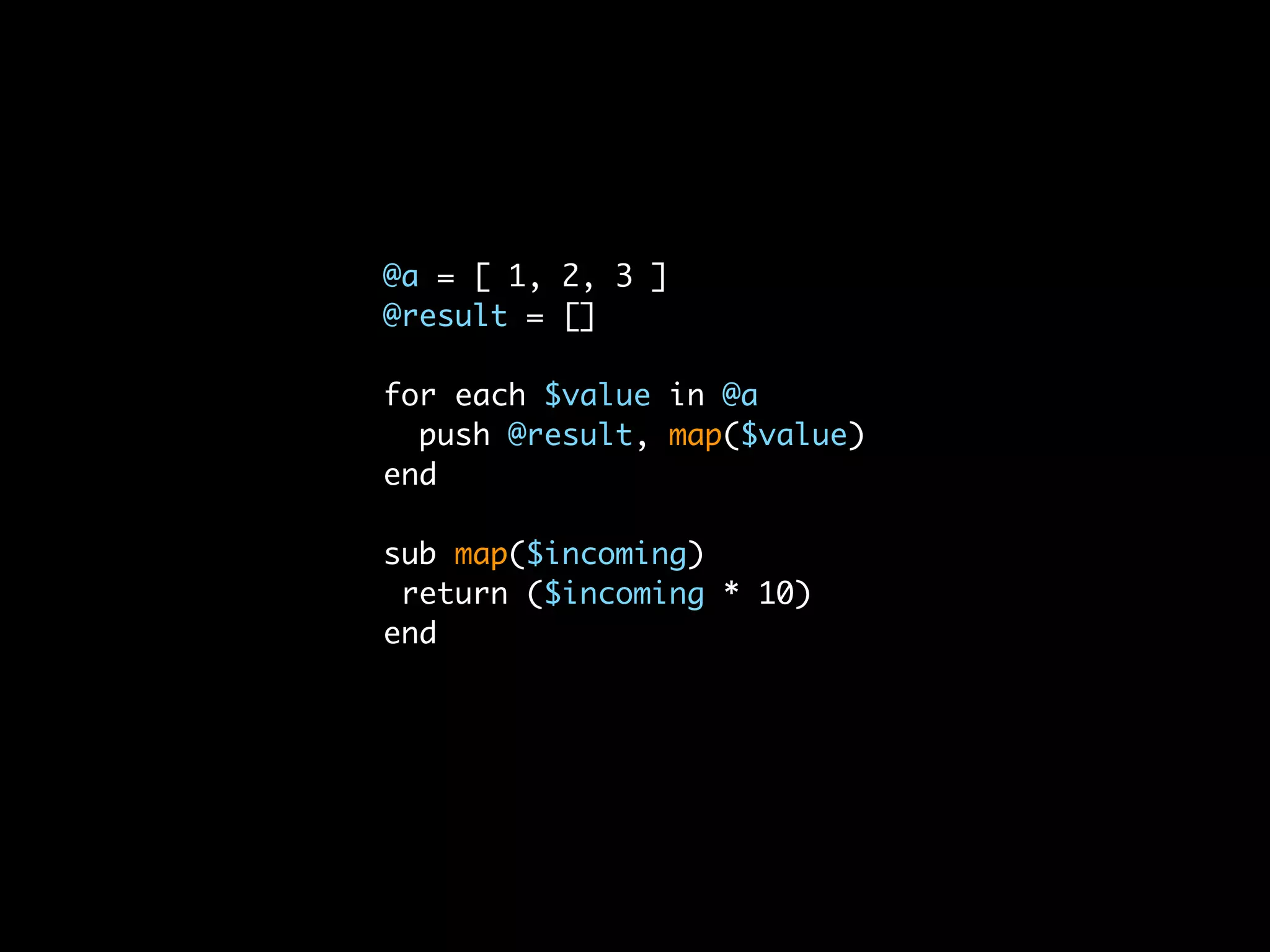

































The document discusses the need for a distributed platform and virtual institute to handle large amounts of data, people, compute, and uses. It proposes a platform called Trillionics that would allow users to get data from various sources, select scripts and directories, work on the data through interesting work, and save results back out. The platform would utilize distributed storage, virtualized services, and APIs to get, filter, work on, and save data in a distributed manner across various locations. It emphasizes building systems that can scale enormously to handle petabytes of data per week through a distributed mindset and approach.




































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)









