Download to read offline











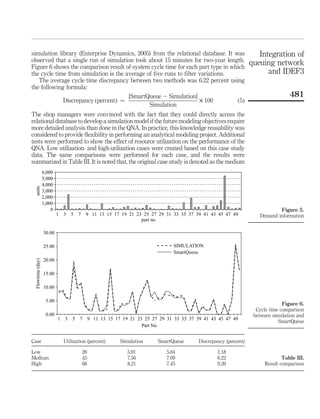



This document discusses integrating IDEF3 process modeling with queuing network analysis to provide quantitative performance measures without simulation. IDEF3 captures process knowledge visually but provides no metrics. Queuing network analysis can estimate metrics like utilization and wait times but requires a different modeling view. The authors develop a framework to convert IDEF3 models to queuing networks by extracting resource information from activities. A database stores all information to facilitate conversion and analysis. Results from the queuing network analyzer are compared to simulation, finding reasonable accuracy at low system utilization. This integration allows domain experts to obtain performance insights without complex simulation modeling.




















































