Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
tatsuya 264
PPTX, PDF
705 views
AWS朝会2022/1 セッション① 数年間、レイクハウスを設計運用してみた
AWS朝会2022/1 セッション① 数年間、レイクハウスを設計運用してみた
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 12
2
/ 12
3
/ 12
4
/ 12
5
/ 12
6
/ 12
7
/ 12
8
/ 12
9
/ 12
10
/ 12
11
/ 12
12
/ 12
More Related Content
PDF
BigData-JAWS#16 Lake House Architecture
by
Satoru Ishikawa
PDF
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
PDF
データ分析基盤について
by
Yuta Inamura
PDF
初めてのデータ分析基盤構築をまかされた、その時何を考えておくと良いのか
by
Techon Organization
PDF
Azure Purview Linage for Dataflow/Spark
by
Ryoma Nagata
PPTX
データサイエンティストが力を発揮できるアジャイルデータ活用基盤
by
Recruit Lifestyle Co., Ltd.
PDF
データ基盤の従来~最新の考え方とSynapse Analyticsでの実現
by
Ryoma Nagata
PPTX
AI/ML開発・運用ワークフロー検討案(日本ソフトウェア科学会 機械学習工学研究会 本番適用のためのインフラと運用WG主催 討論会)
by
NTT DATA Technology & Innovation
BigData-JAWS#16 Lake House Architecture
by
Satoru Ishikawa
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
データ分析基盤について
by
Yuta Inamura
初めてのデータ分析基盤構築をまかされた、その時何を考えておくと良いのか
by
Techon Organization
Azure Purview Linage for Dataflow/Spark
by
Ryoma Nagata
データサイエンティストが力を発揮できるアジャイルデータ活用基盤
by
Recruit Lifestyle Co., Ltd.
データ基盤の従来~最新の考え方とSynapse Analyticsでの実現
by
Ryoma Nagata
AI/ML開発・運用ワークフロー検討案(日本ソフトウェア科学会 機械学習工学研究会 本番適用のためのインフラと運用WG主催 討論会)
by
NTT DATA Technology & Innovation
What's hot
PPTX
Delta lakesummary
by
Ryoma Nagata
PDF
20190517 Spark+AI Summit2019最新レポート
by
Ryoma Nagata
PPTX
BigData Architecture for Azure
by
Ryoma Nagata
PDF
データ分析基盤、どう作る?システム設計のポイント、教えます - Developers.IO 2019 (20191101)
by
Yosuke Katsuki
PDF
データ分析を支える技術 DWH再入門
by
Satoru Ishikawa
PPTX
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
PDF
Data platformdesign
by
Ryoma Nagata
PDF
Power Query Online
by
Ryoma Nagata
PDF
DX認定制度システム開発裏話:技術編
by
Arichika TANIGUCHI
PDF
データ分析基盤運⽤チームの 運⽤業務を改善してみた話
by
Recruit Lifestyle Co., Ltd.
PDF
ビックデータ分析基盤の成⻑の軌跡
by
Recruit Lifestyle Co., Ltd.
PDF
Databricks の始め方
by
Ryoma Nagata
PDF
データ分析を支える技術 データ分析基盤再入門
by
Satoru Ishikawa
PPTX
Data Factory V2 新機能徹底活用入門
by
Keisuke Fujikawa
PDF
Ignite update databricks_stream_analytics
by
Ryoma Nagata
PPTX
Glue DataBrewでデータをクリーニング、加工してみよう
by
takeshi suto
PDF
性能問題を起こしにくい信頼されるクラウド RDB のつくりかた
by
Tomoyuki Oota
PDF
Azure Antenna はじめての Azure Data Lake
by
Hideo Takagi
PPTX
データウェアハウス・BI の再構築から見る情報系基盤の再構築ポイント
by
UNIRITA Incorporated
PDF
[data analytics showcase] B16: Live Demo! データ分析基盤を支えるデータレプリケーション技術とデータワークロード分...
by
Insight Technology, Inc.
Delta lakesummary
by
Ryoma Nagata
20190517 Spark+AI Summit2019最新レポート
by
Ryoma Nagata
BigData Architecture for Azure
by
Ryoma Nagata
データ分析基盤、どう作る?システム設計のポイント、教えます - Developers.IO 2019 (20191101)
by
Yosuke Katsuki
データ分析を支える技術 DWH再入門
by
Satoru Ishikawa
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
Data platformdesign
by
Ryoma Nagata
Power Query Online
by
Ryoma Nagata
DX認定制度システム開発裏話:技術編
by
Arichika TANIGUCHI
データ分析基盤運⽤チームの 運⽤業務を改善してみた話
by
Recruit Lifestyle Co., Ltd.
ビックデータ分析基盤の成⻑の軌跡
by
Recruit Lifestyle Co., Ltd.
Databricks の始め方
by
Ryoma Nagata
データ分析を支える技術 データ分析基盤再入門
by
Satoru Ishikawa
Data Factory V2 新機能徹底活用入門
by
Keisuke Fujikawa
Ignite update databricks_stream_analytics
by
Ryoma Nagata
Glue DataBrewでデータをクリーニング、加工してみよう
by
takeshi suto
性能問題を起こしにくい信頼されるクラウド RDB のつくりかた
by
Tomoyuki Oota
Azure Antenna はじめての Azure Data Lake
by
Hideo Takagi
データウェアハウス・BI の再構築から見る情報系基盤の再構築ポイント
by
UNIRITA Incorporated
[data analytics showcase] B16: Live Demo! データ分析基盤を支えるデータレプリケーション技術とデータワークロード分...
by
Insight Technology, Inc.
Similar to AWS朝会2022/1 セッション① 数年間、レイクハウスを設計運用してみた
PDF
[CTO Night & Day 2019] AWS で構築するデータレイク基盤と amazon.com での導入事例 #ctonight
by
Amazon Web Services Japan
PDF
データレイクを基盤としたAWS上での機械学習サービス構築
by
Amazon Web Services Japan
PDF
データ活用を加速するAWS分析サービスのご紹介
by
Amazon Web Services Japan
PDF
Amazon S3を中心とするデータ分析のベストプラクティス
by
Amazon Web Services Japan
PDF
Effective Data Lakes - ユースケースとデザインパターン
by
Noritaka Sekiyama
PDF
実案件で見る データ分析用AWS基盤の構築方法 - Developers.IO 2017 (20170701)
by
Yosuke Katsuki
PDF
Amazon Game Tech Night #22 AWSで実現するデータレイクとアナリティクス
by
Amazon Web Services Japan
PDF
20180619 AWS Black Belt Online Seminar データレイク入門: AWSで様々な規模のデータレイクを分析する効率的な方法
by
Amazon Web Services Japan
PDF
Amazon Redshiftへの移行方法と設計のポイント(db tech showcase 2016)
by
Amazon Web Services Japan
PDF
Developers.IO 2019 Effective Datalake
by
Satoru Ishikawa
PDF
1000人規模で使う分析基盤構築 〜redshiftを活用したeuc
by
Kazuhiro Miyajima
PDF
Amazon Redshift 概要 (20分版)
by
Amazon Web Services Japan
PPTX
Game Architecture Trends in Tokyo Kansai Social Game Study#5
by
Yasuhiro Matsuo
[CTO Night & Day 2019] AWS で構築するデータレイク基盤と amazon.com での導入事例 #ctonight
by
Amazon Web Services Japan
データレイクを基盤としたAWS上での機械学習サービス構築
by
Amazon Web Services Japan
データ活用を加速するAWS分析サービスのご紹介
by
Amazon Web Services Japan
Amazon S3を中心とするデータ分析のベストプラクティス
by
Amazon Web Services Japan
Effective Data Lakes - ユースケースとデザインパターン
by
Noritaka Sekiyama
実案件で見る データ分析用AWS基盤の構築方法 - Developers.IO 2017 (20170701)
by
Yosuke Katsuki
Amazon Game Tech Night #22 AWSで実現するデータレイクとアナリティクス
by
Amazon Web Services Japan
20180619 AWS Black Belt Online Seminar データレイク入門: AWSで様々な規模のデータレイクを分析する効率的な方法
by
Amazon Web Services Japan
Amazon Redshiftへの移行方法と設計のポイント(db tech showcase 2016)
by
Amazon Web Services Japan
Developers.IO 2019 Effective Datalake
by
Satoru Ishikawa
1000人規模で使う分析基盤構築 〜redshiftを活用したeuc
by
Kazuhiro Miyajima
Amazon Redshift 概要 (20分版)
by
Amazon Web Services Japan
Game Architecture Trends in Tokyo Kansai Social Game Study#5
by
Yasuhiro Matsuo
AWS朝会2022/1 セッション① 数年間、レイクハウスを設計運用してみた
1.
AWS朝会2022/1 セッション① 数年間、レイクハウスを設計運用してみた
2.
2 本日の内容と目的 • 数年間、データ分析基盤の設計・運用・コンサルティングをしてきました。 • 技術としてかなりこなれてきた部分もありますが、ノウハウを共有したいと思っています。
3.
3 そもそも、データ分析基盤、データレイクって?(座学)
4.
4 そもそもデータ分析基盤とは? • 社内外の様々なデータを一元的に保管され、データ加工ツールや分析ツール(AI/BI) が統合 されている基盤 •
代表的なデータ分析基盤のアーキテクチャ Enterprise System/ Services データ分析基盤 収集 蓄積 集計 活用 データ ウェアハウス (Redshift, EMR, S3etc) 分析・学習/推論 (Quick Sight, SageMaker etc) 構造 Data 準構造 Data 非構造 Data データレイク (S3,EMR etc) Data Send tool (DMS, Data Sync, Cloud watch logs, Kinesis, Storage Gateway, EFS, IoT Core,etc) Enterprise System WEB services Client device IoT device 準構造 Data 分析 データ マート (RDS、 Redshift, S3 etc) Glue Glue
5.
5 レイクハウスアーキテクチャとは? • データレイク+DWH(データウェアハウス)のアーキテクチャ。AWSの狭義では、Redshift +S3やLake Formation。 •
ローデータ、加工済みデータを広大な空間(S3)に様々な形 にて保管 • BI,AI等多様なアプリケーションから接続(専用でない) • ローデータを広大な空間(S3)に様々な形にて保管 • BI,AI等多様なアプリケーションの用途に合わせた形に加工し たのをDWH(Redshift)に保存 • データレイクの概念 • レイクハウスの概念 データレイク解説シリーズ 第 3 回: AWS でデータレイクを作ってみよう - builders.flash☆ - 変化を求めるデベロッパーを応援するウェブマガジン | AWS (amazon.com) データレイクとは (amazon.com)
6.
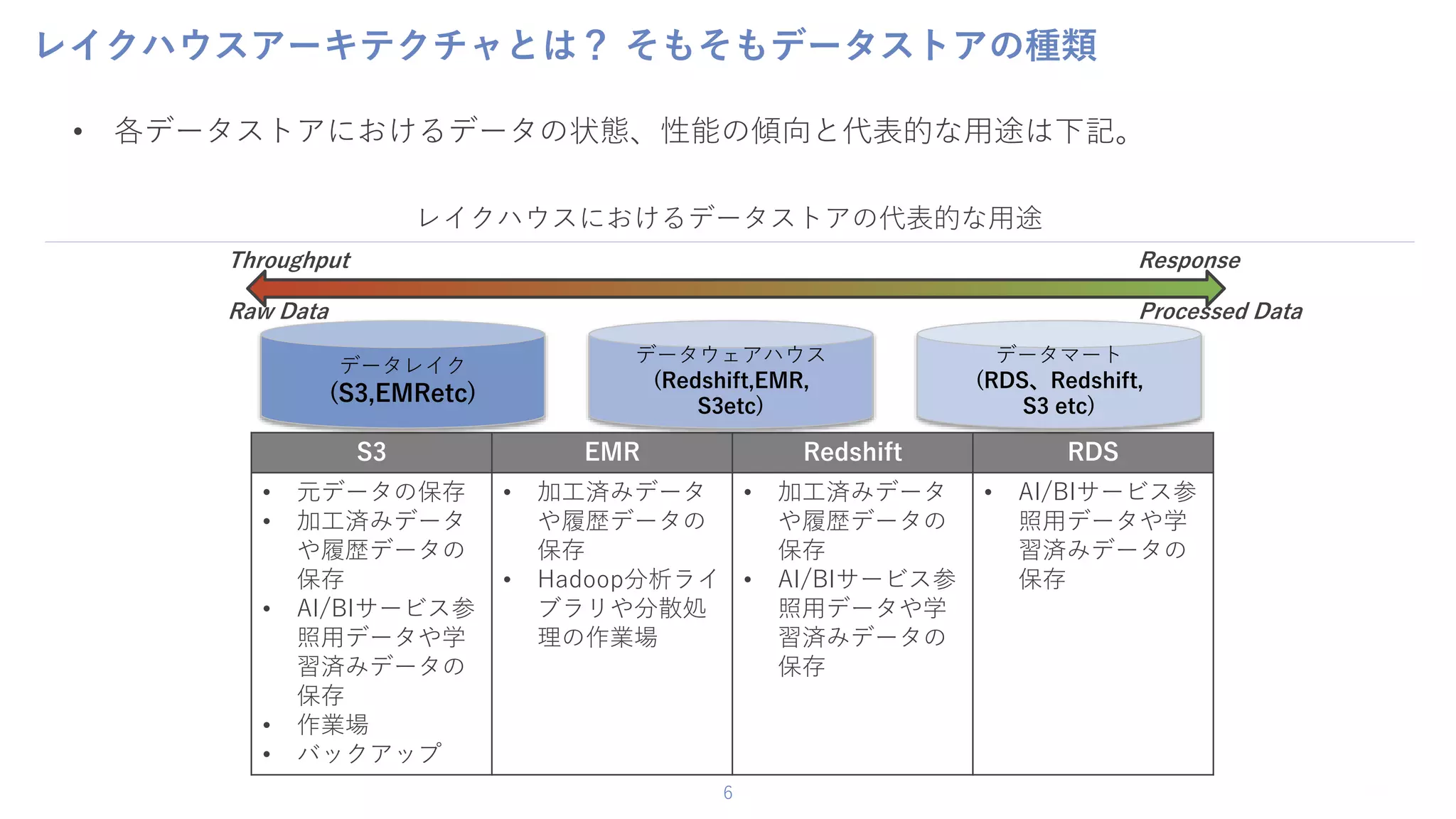
6 レイクハウスアーキテクチャとは? そもそもデータストアの種類 • 各データストアにおけるデータの状態、性能の傾向と代表的な用途は下記。 レイクハウスにおけるデータストアの代表的な用途 S3
EMR Redshift RDS • 元データの保存 • 加工済みデータ や履歴データの 保存 • AI/BIサービス参 照用データや学 習済みデータの 保存 • 作業場 • バックアップ • 加工済みデータ や履歴データの 保存 • Hadoop分析ライ ブラリや分散処 理の作業場 • 加工済みデータ や履歴データの 保存 • AI/BIサービス参 照用データや学 習済みデータの 保存 • AI/BIサービス参 照用データや学 習済みデータの 保存 データウェアハウス (Redshift,EMR, S3etc) データレイク (S3,EMRetc) データマート (RDS、Redshift, S3 etc) Throughput Response Raw Data Processed Data
7.
7 よくある課題
8.
8 超えるべきよくある課題 1. せっかく構築したが誰にも利用されない 2. 性能追求・データストア乱立で「統合基盤」のはずが サイロ化
9.
9 せっかく構築したが誰にも利用されない • 分析基盤を構築する前にヒアリングを行い、機能要件/非機能要件を明らかにする • 運用後でも、活用候補の方にヒアリングし、課題と分析基盤の合致点を探り、併走支援する •
分析業務 ヒアリングの例 # カテゴリ 質問 1 分析業務の概要 貴殿の主たる業務の概要をお聞かせください。 2 分析業務の概要 貴殿の分析業務の概要をお聞かせください。 ・分析の目的 ・分析の形(定型レポーティング(月次レポート等)、非定型分析(アドホック分析)、予測等のシュミレーション) ・分析に係る作業時間 ・報告先と分析結果確認者の行動 4 分析業務の概要データ・環境 分析業務に係る可視化、集計、加工、蓄積の作業は、内省と外部委託のどちらでしょうか?内省の場合、どのようなアプリケーション、環境を利用し ておりますでしょうか? 例:・アプリケーション 可視化集計はTableau、加工はExcel、蓄積はAccess 5 分析業務の概要データ・環境 分析業務で利用するデータをご教示ください。 例:・社内データ(社内システムの提供するデータ)の対象とデータ量 ・社外データ(オープンデータや調査会社発行のデータ等)の利用 6 分析業務の課題 分析計画・目的、分析データ(データそのものやマスタの統一軸等)に対する課題があればお聞かせください。 例:・もっと鮮度の高いレポーティングをしたいが、データ取得や更新に時間を要する ・各国間のマスタが異なり、横ぐし・統一軸でのレポート作成や評価ができない ・データの粒度鮮度精度が分析担当者によりばらばらで、恣意的なデータ選択・加工等、データが怪しい ・予測精度を向上させたいが、適切な分析をデザインできない 7 分析業務の課題 分析ツール・環境やそのサポートに対する課題があればお聞かせください。 例:・分析しているPCのスペックやネットワーク、ファイルサーバが貧弱。 ・加工がExcel手動の為に、品質や効率が人依存 ・アプリケーションは部の個別調達の為、高性能な分析ツールを利しづらい ・ヘルプデスクではSW動作のサポートにとどまる 8 分析業務の課題 利用・定着面での課題があればお聞かせください。 例:・そもそも作成したレポートが、想定読者に読まれていない ・全て非定型分析の分析が求められる ・高度な分析を行いたいが、分析担当者の分析スキルが高くない ・ベテランのデータ分析者はいるが、独自のExcelマクロを組んでいるため、他人 の利用や再利用が困難。その方は職人気質であり、使い慣れたExcel・Access以外を利用する気がない
10.
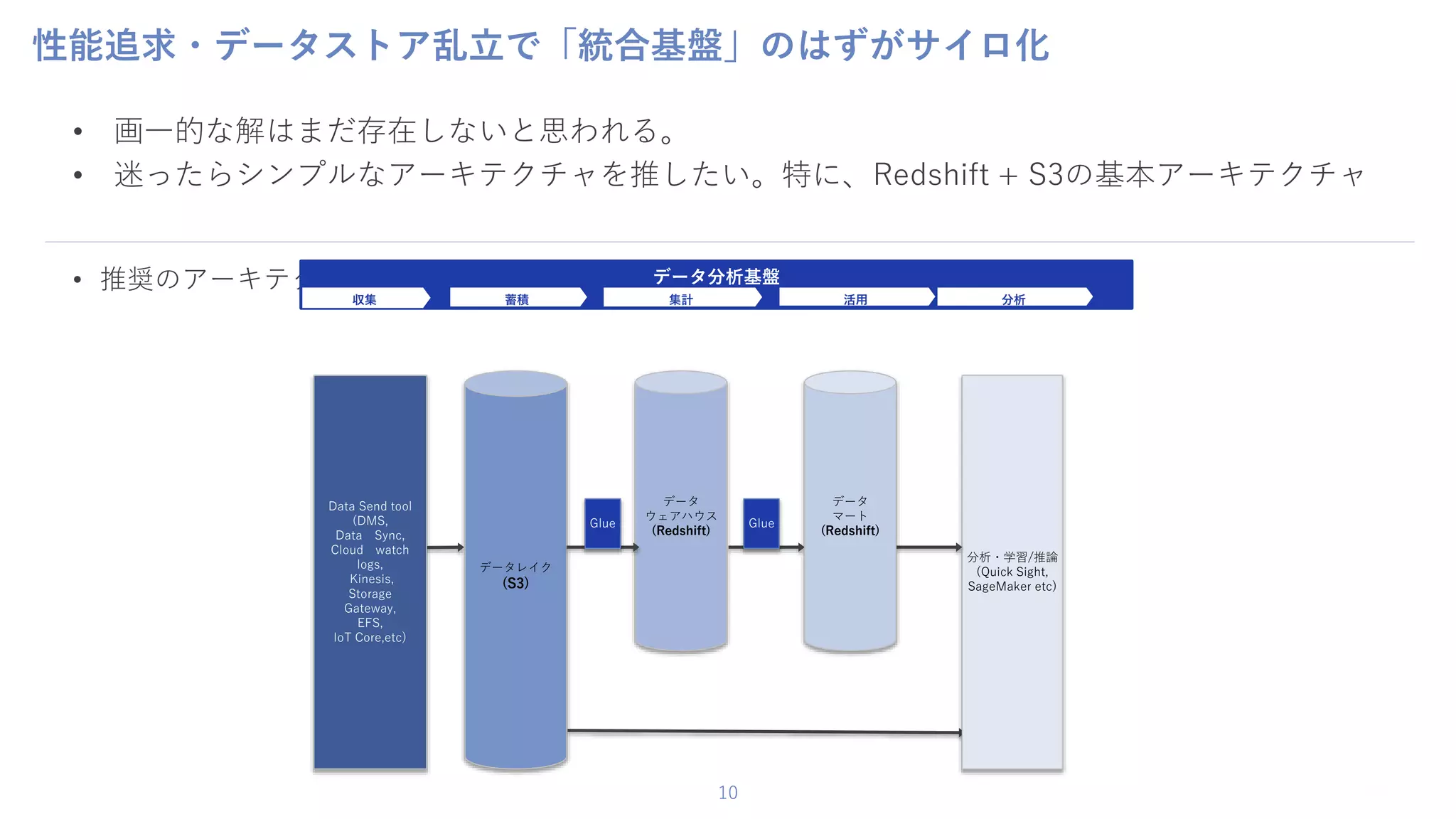
10 性能追求・データストア乱立で「統合基盤」のはずがサイロ化 • 画一的な解はまだ存在しないと思われる。 • 迷ったらシンプルなアーキテクチャを推したい。特に、Redshift
+ S3の基本アーキテクチャ • 推奨のアーキテクチャ データ分析基盤 収集 蓄積 集計 活用 データ ウェアハウス (Redshift) 分析・学習/推論 (Quick Sight, SageMaker etc) データレイク (S3) Data Send tool (DMS, Data Sync, Cloud watch logs, Kinesis, Storage Gateway, EFS, IoT Core,etc) 分析 データ マート (Redshift) Glue Glue
11.
11 性能追求・データストア乱立で「統合基盤」のはずがサイロ化 • Redshiftは高機能化が著しく、より一層のユースケースに対応できる。 • Redshiftの進化 #
あるある 1昔前(2017)くらいの対処方法 2021の対処方法 1 Redshiftを一時停止したい 一時停止ができないので、スナップショット+ クラスタ削除(あるいは、このバッチ) 一時停止が可能(バックアップ中は失敗する) 2 materialized viewを使いたい 物理テーブルで作成する materialized view機能が利用可能 3 ストアドプロシージャを使いたい あきらめる ストアドプロシージャ機能が利用可能 4 Redshift以外のデータも使い分析し たい Redshiftにすべてのデータを移行。あるいはS3 にエクスポートしてSpectrum RedshiftでFederated Queryが可能。あるいは AthenaからFederated queryを発行 5 Redshiftのデータを機械学習したい Redshiftへの学習、推論プッシュダウンができな いので、機械学習AP側でデータをFetchして処理 Redshift MLがプレビュー→GAしました 6 ソートキー、分散キーの設定になじ みがない(INDEXはわかるけど) 分散キーの設定が必要だけどよくわからないか ら、とりあえずEVEN AUTO設定が利用可能 7 同時実行数は静的かつリソースも分 割固定であり、低く設定すると、処 理待ちキューが発生 WLM設計を緻密に行う、割り切る Concurrency Scailingで自動スケール 8 ディスクの料金が高い。かといって Spectrumは使いずらい DSノードを利用する RA3ノードによるS3とRedshift内ディスクの自動 最適化を利用する Redshift Serverlessが登場
12.
12 (参考)Redshift MLを使ってみました • Redshift中のデータから予測モデルを使いたい場合、簡易で非常に便利。 •
CREATE TABLEのように、説明変数と目的変数 を定義したモデルを定義。(SQL実行により学習) • 学習モデルをストアドプロシジャのように利用 可能。 学習モデルの作成 推論の実行 アカウント数字 Redshiftクラスタに必要な設定: • Elasitc ipアドレスの付与 • クラスタバージョン「sql_preview」の 指定
Download





































![[data analytics showcase] B16: Live Demo! データ分析基盤を支えるデータレプリケーション技術とデータワークロード分...](https://cdn.slidesharecdn.com/ss_thumbnails/waf1saonq7kghgwbprmc-signature-25a0ea6711cd6aa4d4a08a1137bfd90f9f8e7850cd850623d7101ef7c30a9b4c-poli-161007061148-thumbnail.jpg?width=640&height=640&fit=bounds)
![[CTO Night & Day 2019] AWS で構築するデータレイク基盤と amazon.com での導入事例 #ctonight](https://cdn.slidesharecdn.com/ss_thumbnails/ctond2019morningsessiondatalake-191027185852-thumbnail.jpg?width=640&height=640&fit=bounds)











