Download to read offline





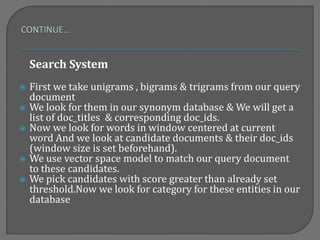
![ They are used to disambiguate between the senses, but
since they are not part of the Extracting entity name, we
must first strip them from the title. Next we strip all wi
which are found in S, which is a list of stop words.
1. C=1 if any li ∊ [A::Z], 0 otherwise
2. D=1 if |Q| >= 2 where Q = ∑ C(li), 0 otherwise
3. D returns 1 if the parameter has multiple capital
letters, 0 otherwise C is a function that returns 1 if the
parameter is capitalized, and 0 otherwise, while D is a
function that that returns 1 if the parameter has
multiple capital letters, and 0 otherwise. a is a variable
used as a threshold for the third condition.](https://image.slidesharecdn.com/informationretrievalandextraction-140417101520-phpapp01/85/Information_retrieval_and_extraction_IIIT-6-320.jpg)





This document describes a project to mine named entities from Wikipedia. It discusses using Wikipedia's internal links, redirect links, external links, and categories to identify named entities and their synonyms with high accuracy. It presents an algorithm for generic named entity recognition that classifies Wikipedia entries based on capitalization, title formatting, and other features. The project aims to build a search system that matches queries to candidates using vector space modeling and considers contextual windows around search terms.






























![[EN] Capture Indexing & Auto-Classification | DLM Forum Industry Whitepaper 0...](https://cdn.slidesharecdn.com/ss_thumbnails/dlmforumindustrywhitepaper01captureindexingauto-classificationser20020618-150824091618-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)























































