Downloaded 16 times



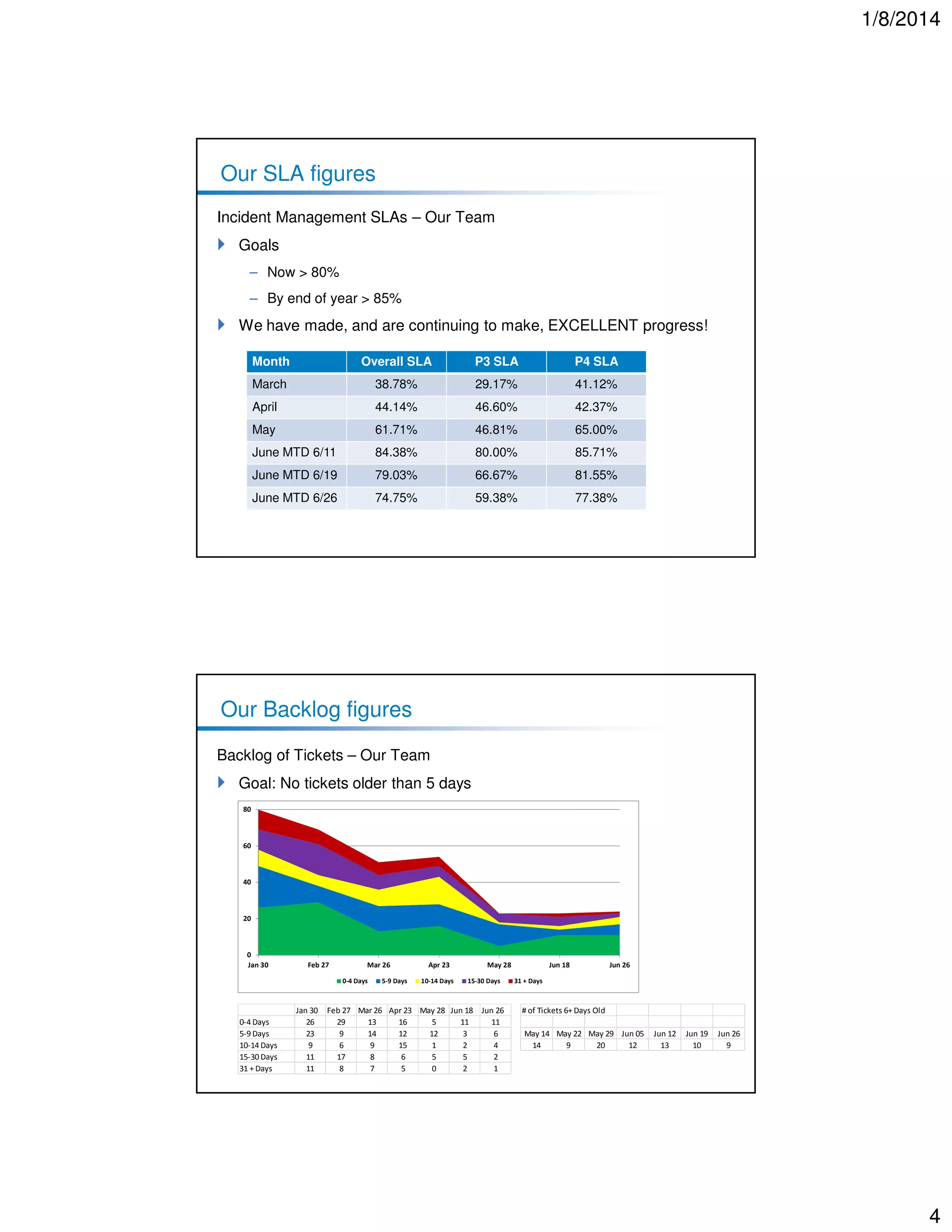




1. The document discusses improving incident management performance by focusing on resolving incidents faster and reducing the number of old tickets. 2. It notes that current incident resolution performance is over 80% but aims to improve it to over 85% by year-end. It also aims to have no tickets older than 5 days. 3. The document provides guidance on properly categorizing and prioritizing tickets to ensure metrics accurately reflect performance and tickets are resolved promptly. This includes assigning tickets, differentiating incidents from other requests, and escalating issues that cannot be resolved internally.






































































