Download to read offline
























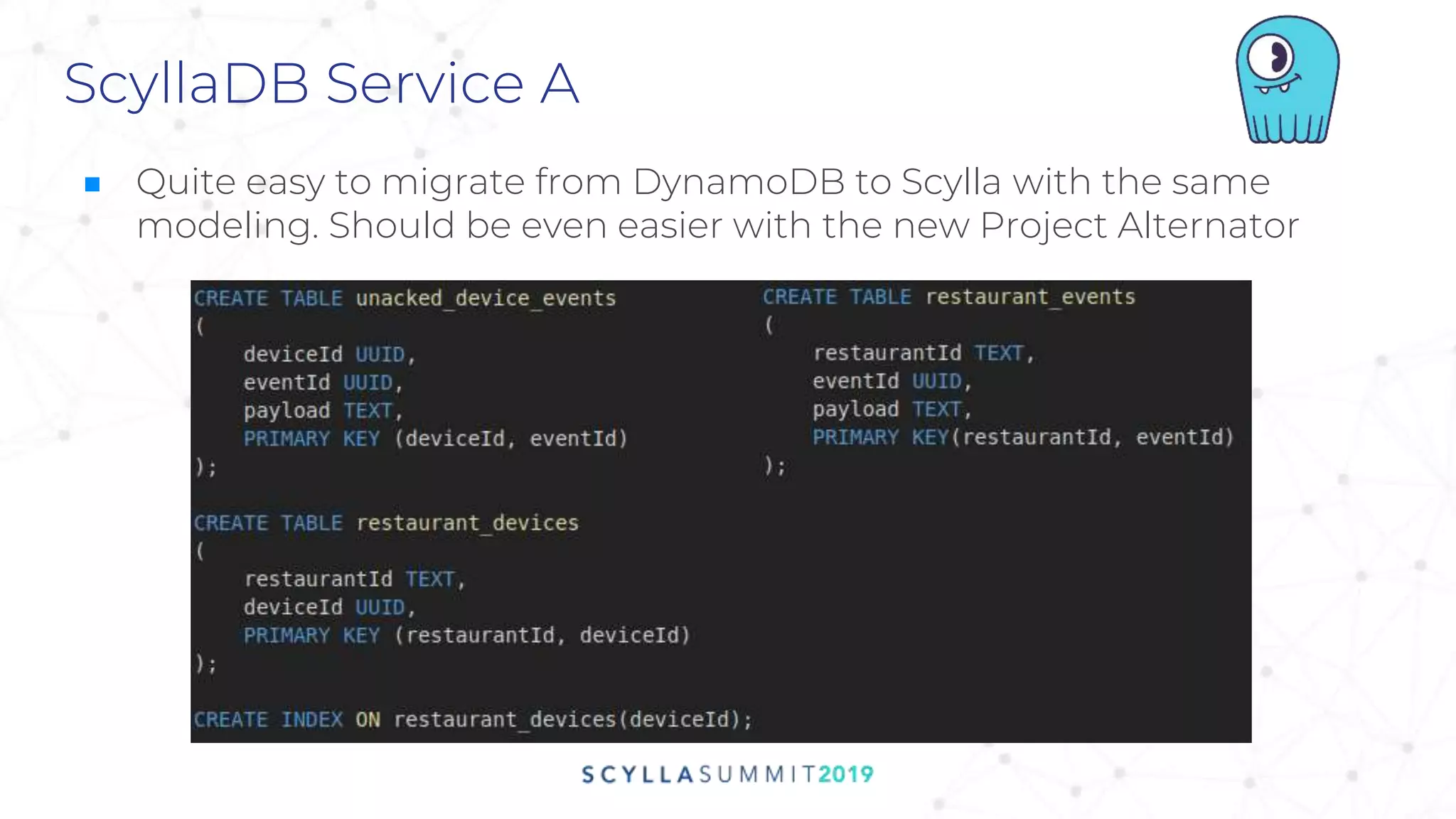













Thales Biancalana, a senior backend developer at iFood, discusses migrating the company's infrastructure to a microservice event-driven architecture to improve polling services for 500k merchants. The case study outlines challenges and successes in transitioning from various database systems to ScyllaDB, highlighting significant cost reductions and performance enhancements. Key learnings include the importance of understanding database features and managing complexity in solutions.




































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















