




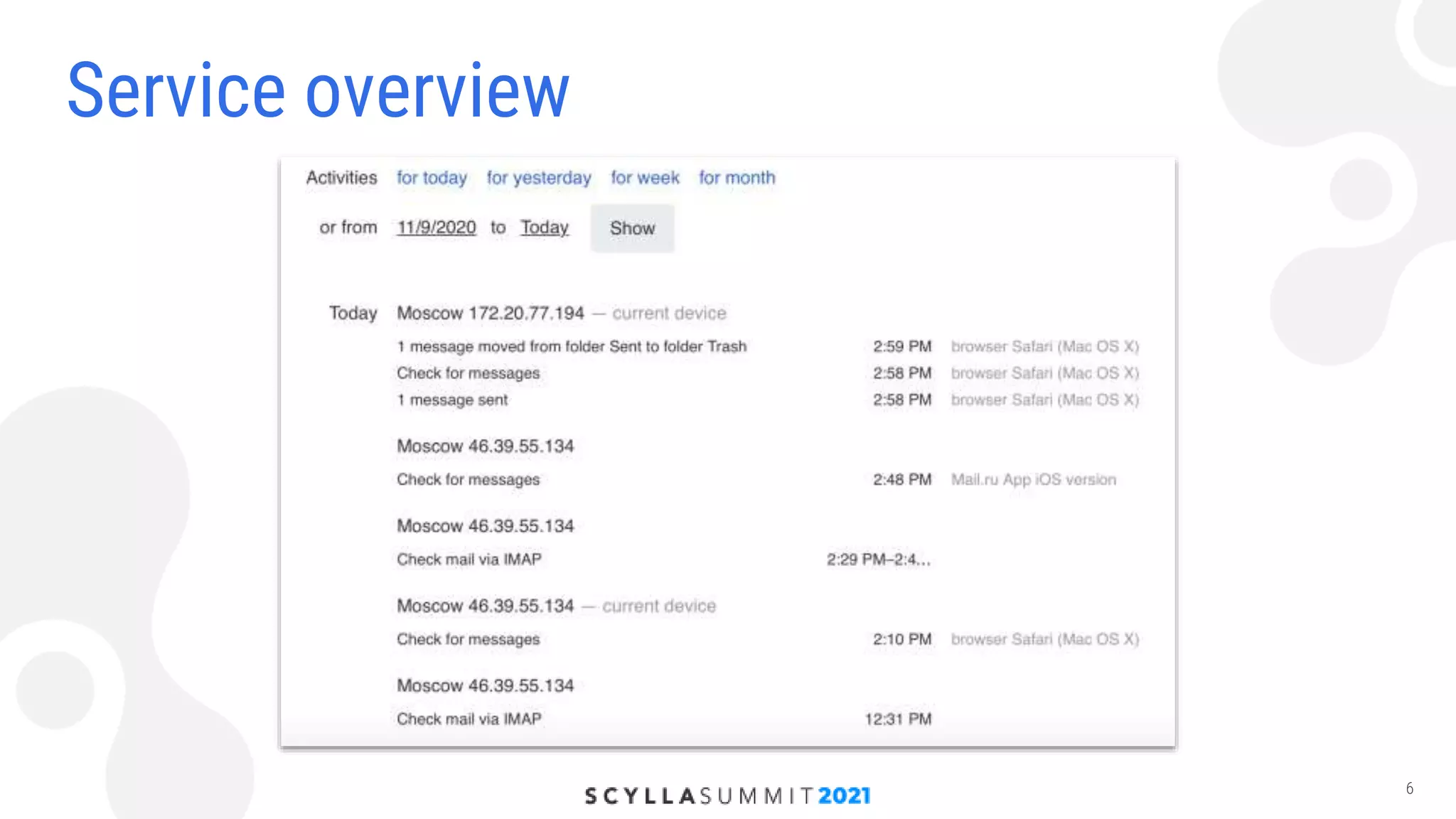

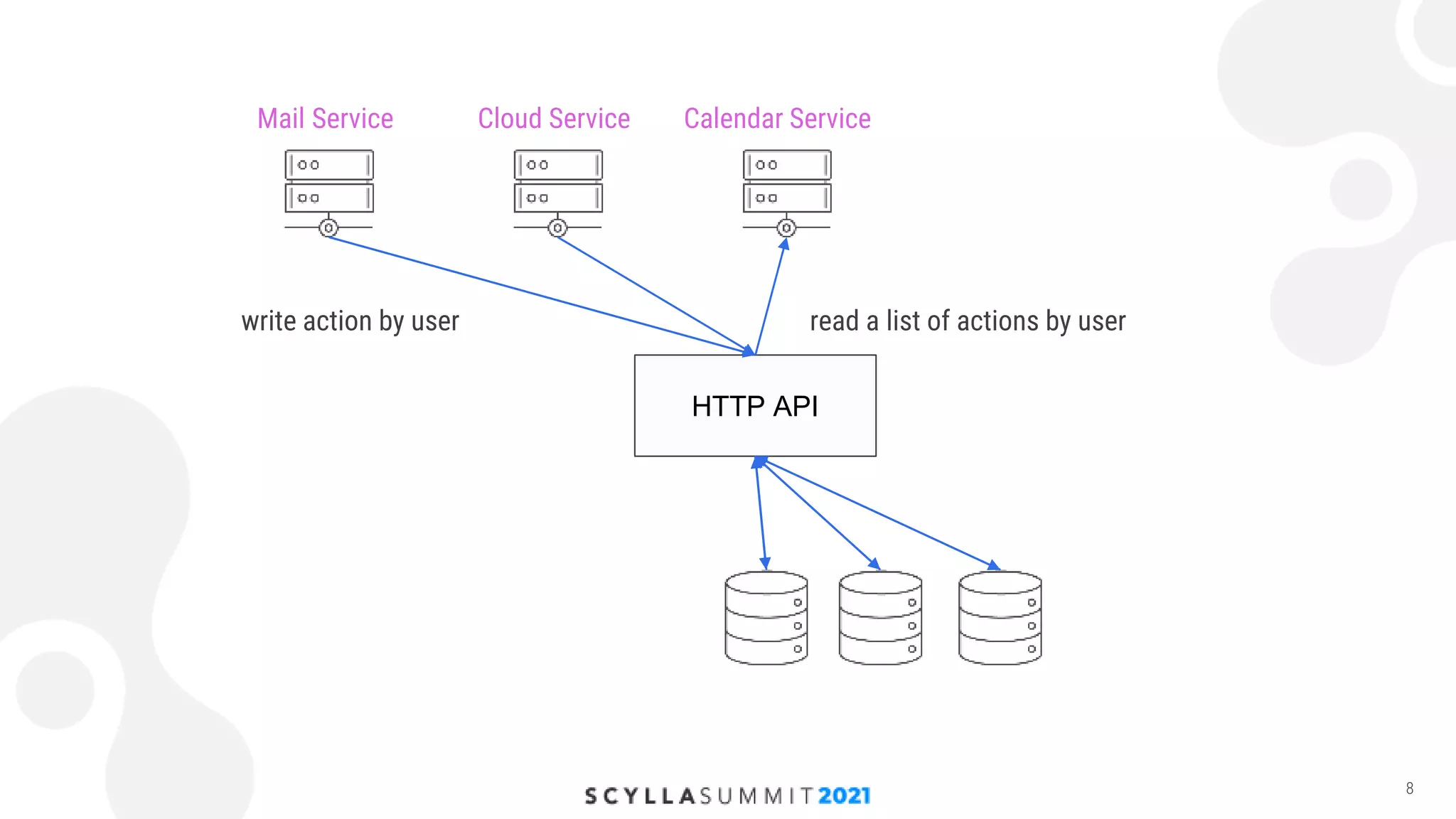



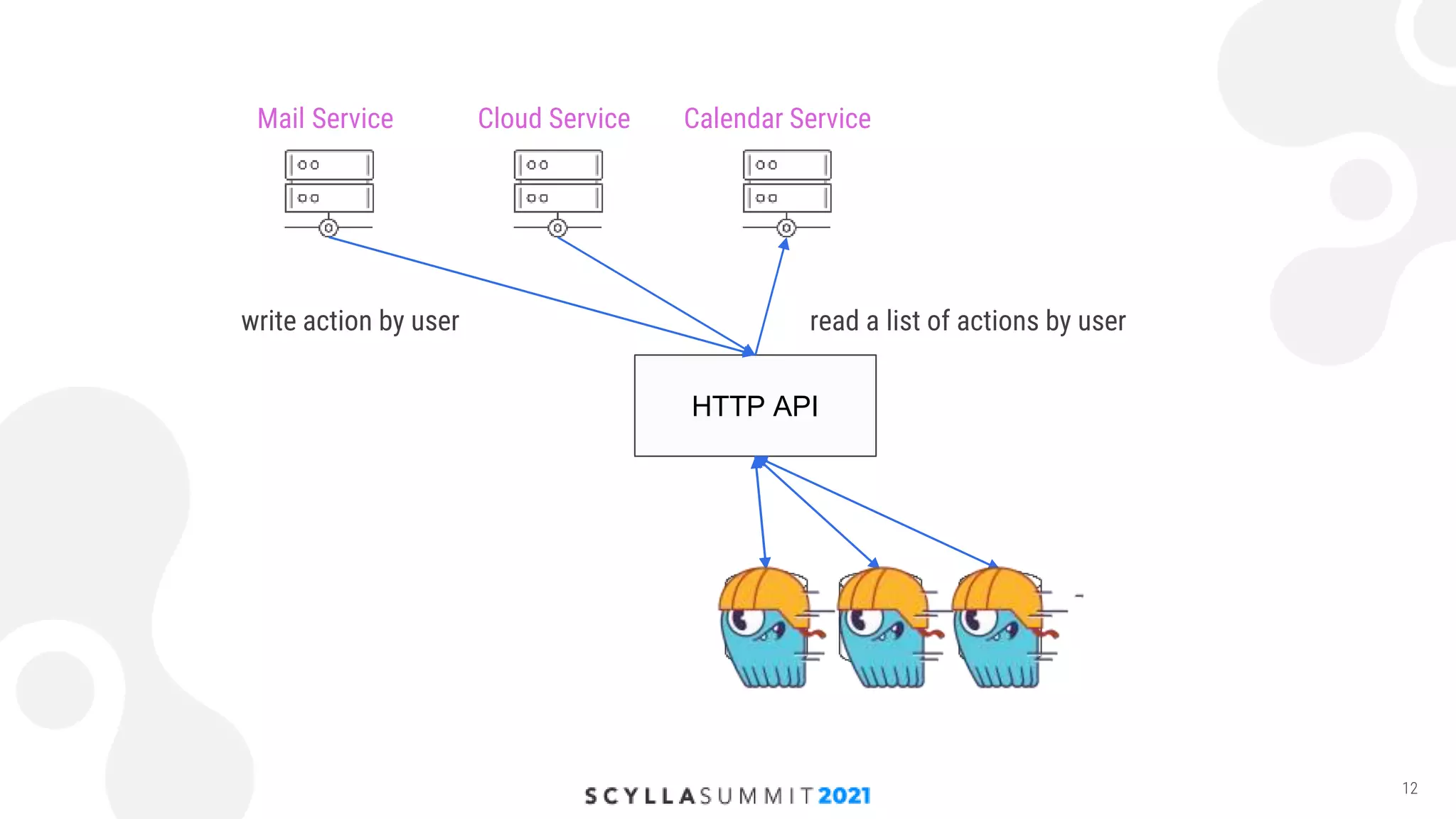










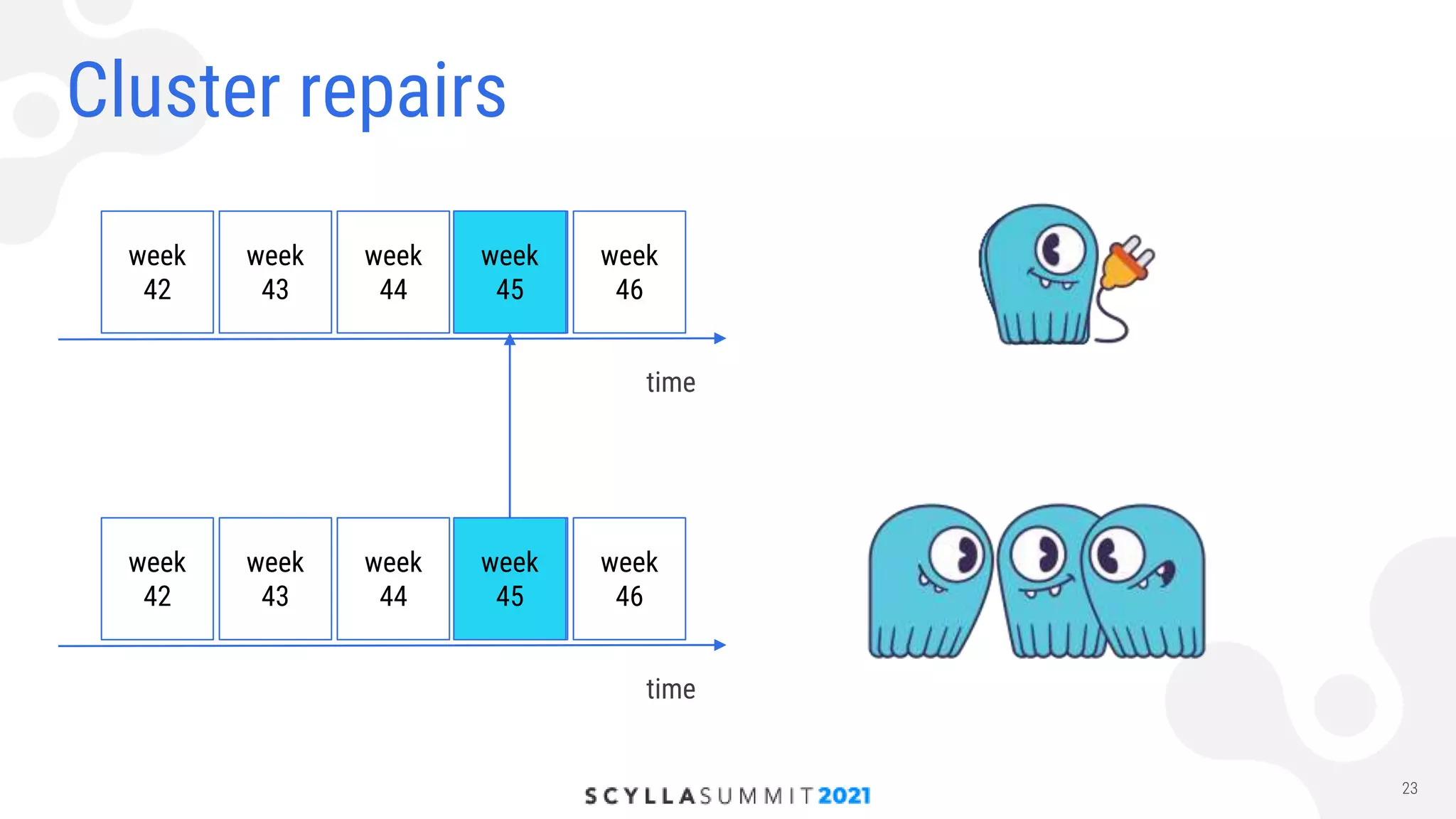









The document discusses the implementation of a high-load storage service for user actions using Scylla and HDDs, achieving 240,000 writes per second with low latency. It highlights the transition from a previous storage solution that faced issues like poor scalability and maintenance difficulty, to a more efficient system featuring a specific data model and architecture. The future work includes further optimizations and integration of Scylla into more projects.























































































