agenda
• 講義要約
– LargeMargin Classification
• Optimization Objective
• Large Margin Intuition
• Mathematics Behind Large Margin Classification
– Kernels
• Kernels I
• Kernels II
– SVMs in Practice
• Using An SVM
– Quiz
• 課題
2
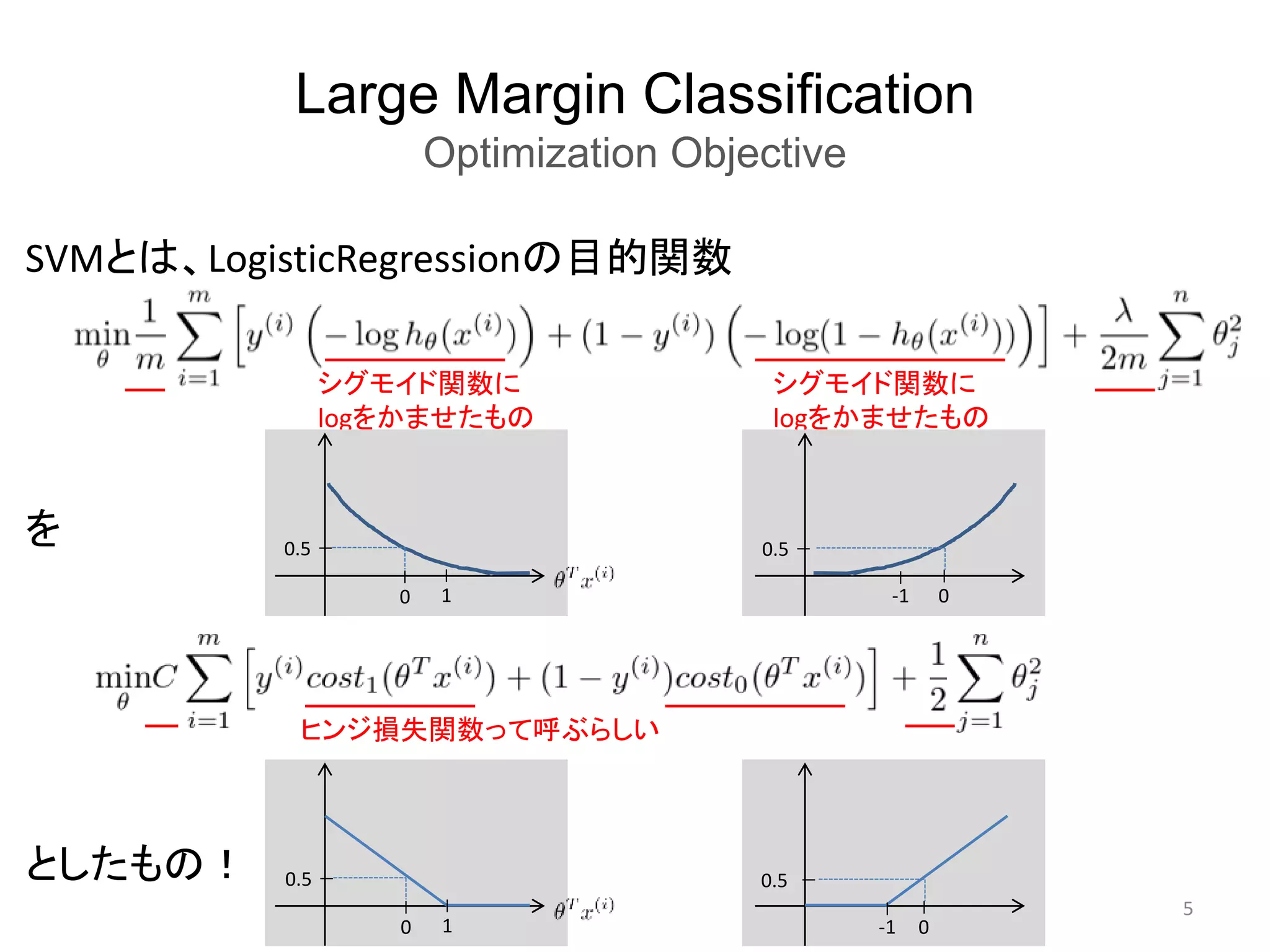
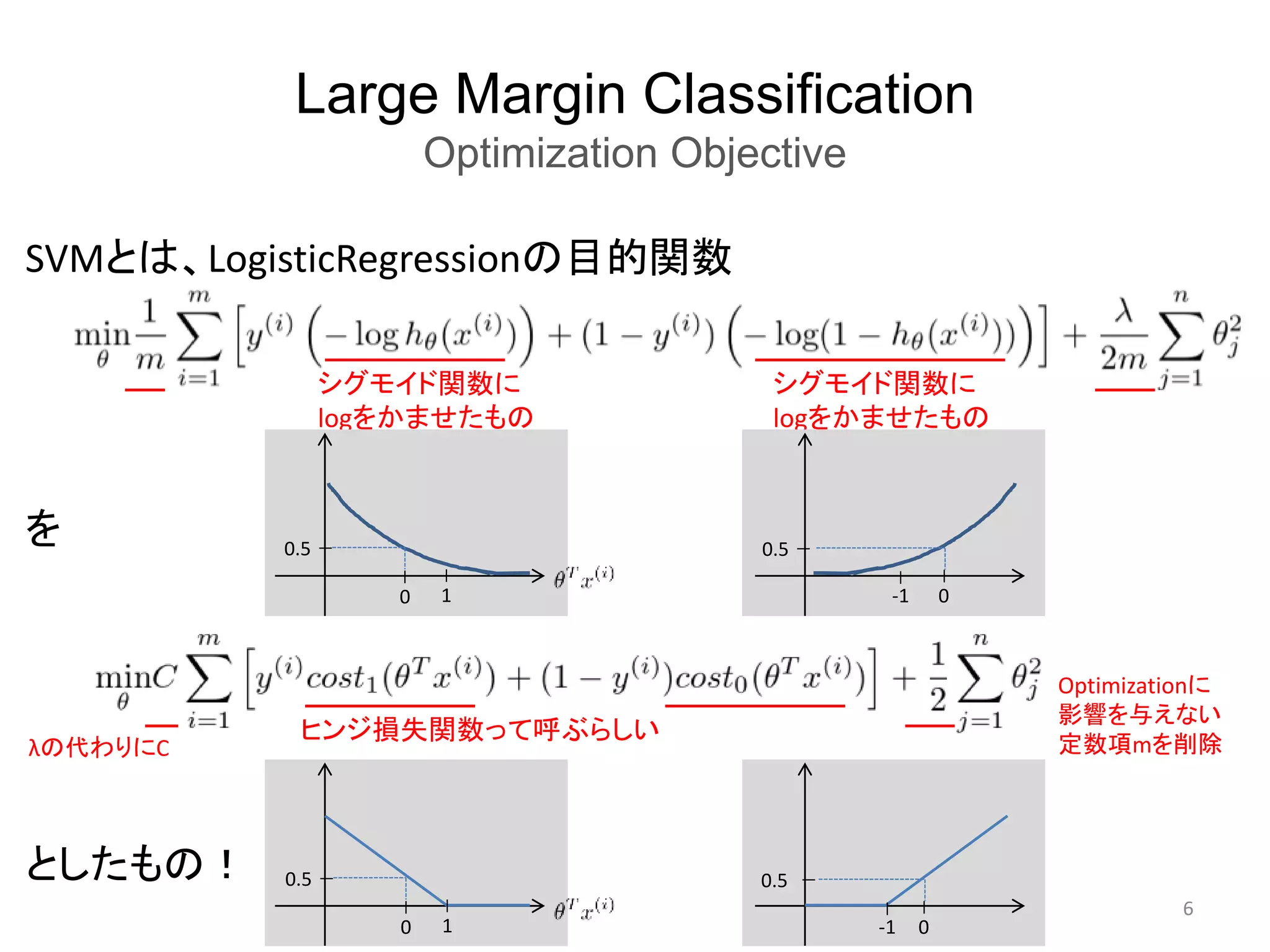
Large Margin Classification
MathematicsBehind Large Margin Classification
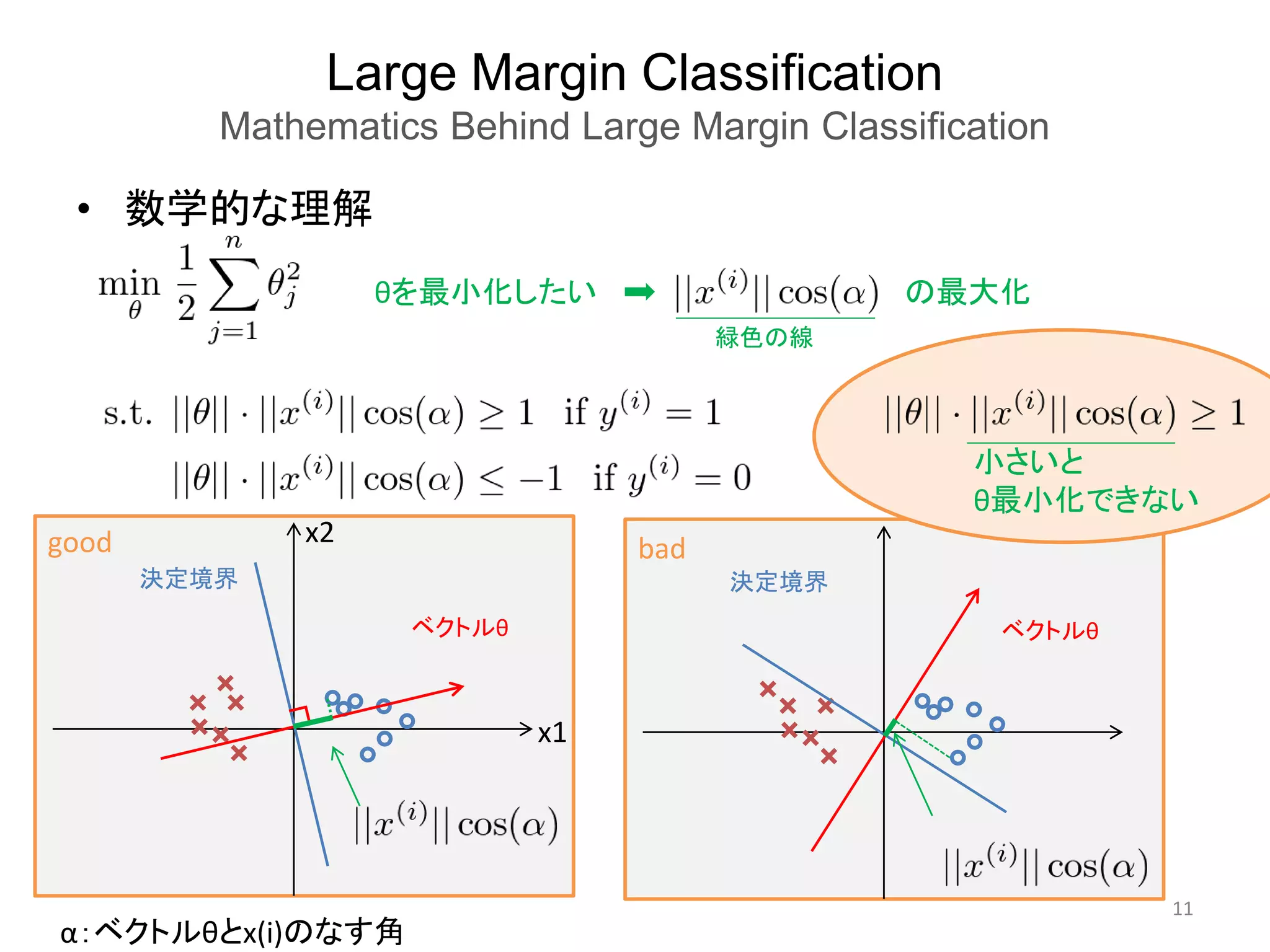
• 数学的な理解
11
ベクトルθ
決定境界
ベクトルθ
決定境界
小さいと
θ最小化できない
θを最小化したい
good bad
x1
x2
の最大化
α:ベクトルθとx(i)のなす角
緑色の線
12.
agenda
• 講義要約
– LargeMargin Classification
• Optimization Objective
• Large Margin Intuition
• Mathematics Behind Large Margin Classification
– Kernels
• Kernels I
• Kernels II
– SVMs in Practice
• Using An SVM
– Quiz
• 課題
12
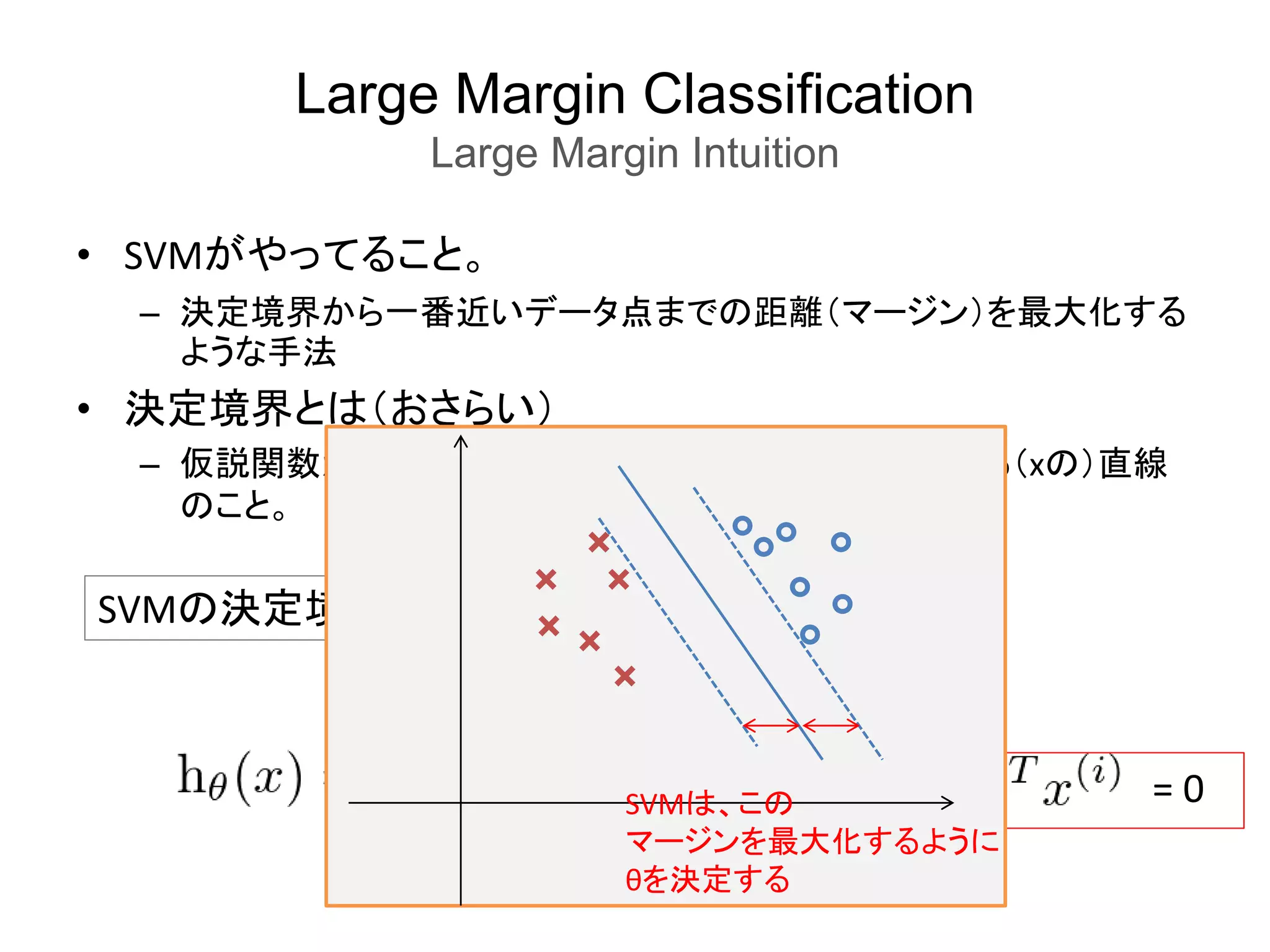
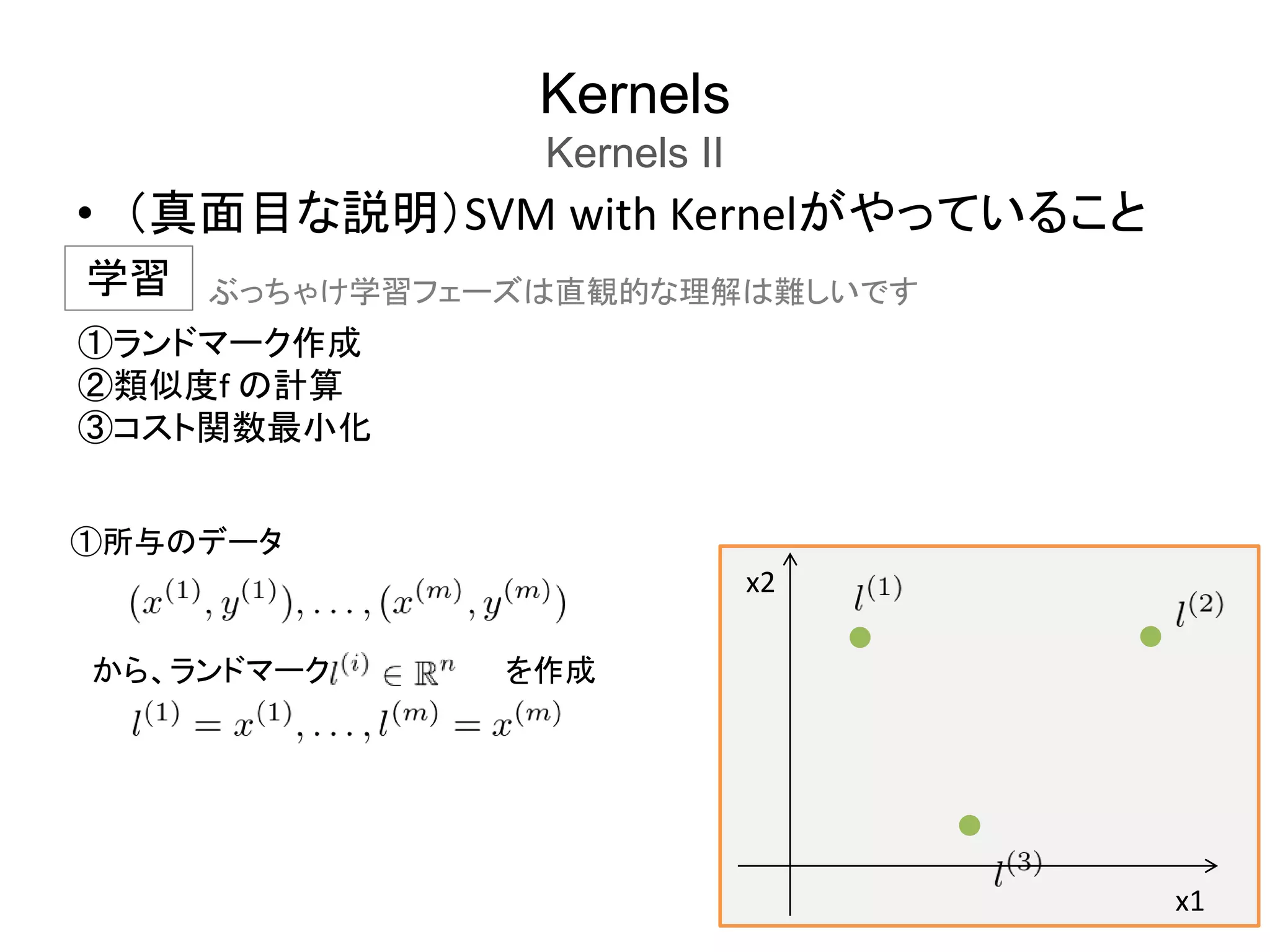
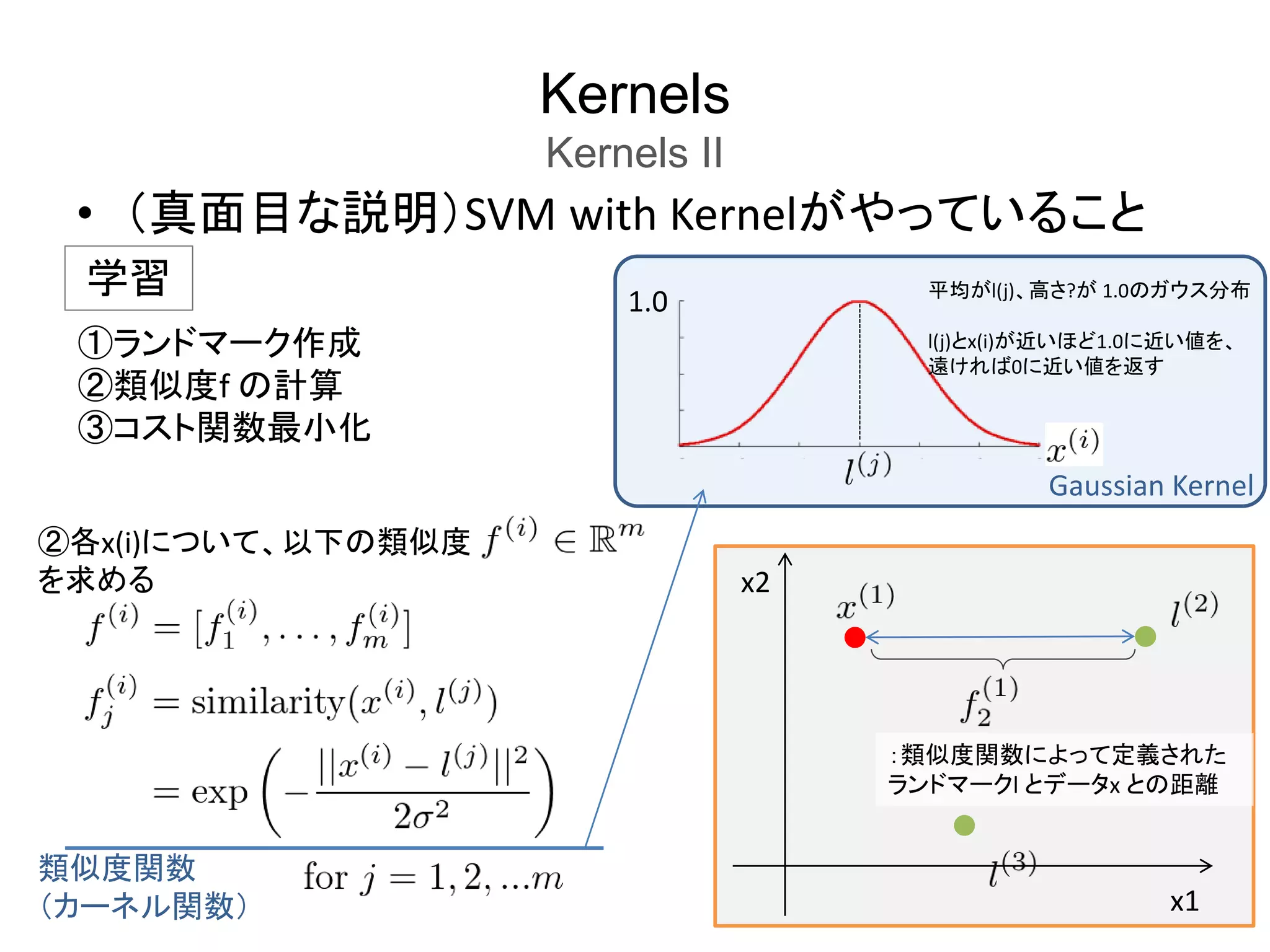
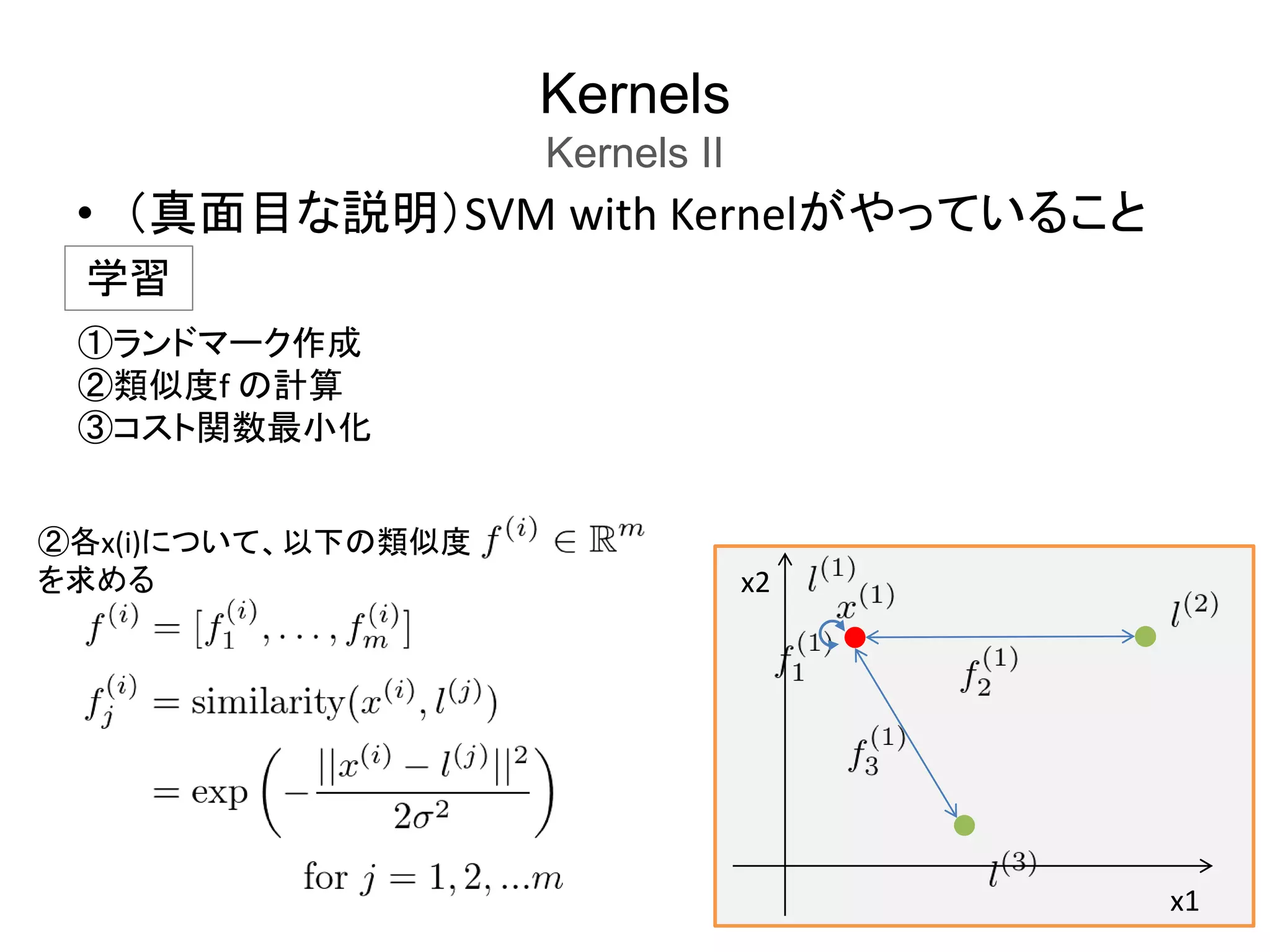
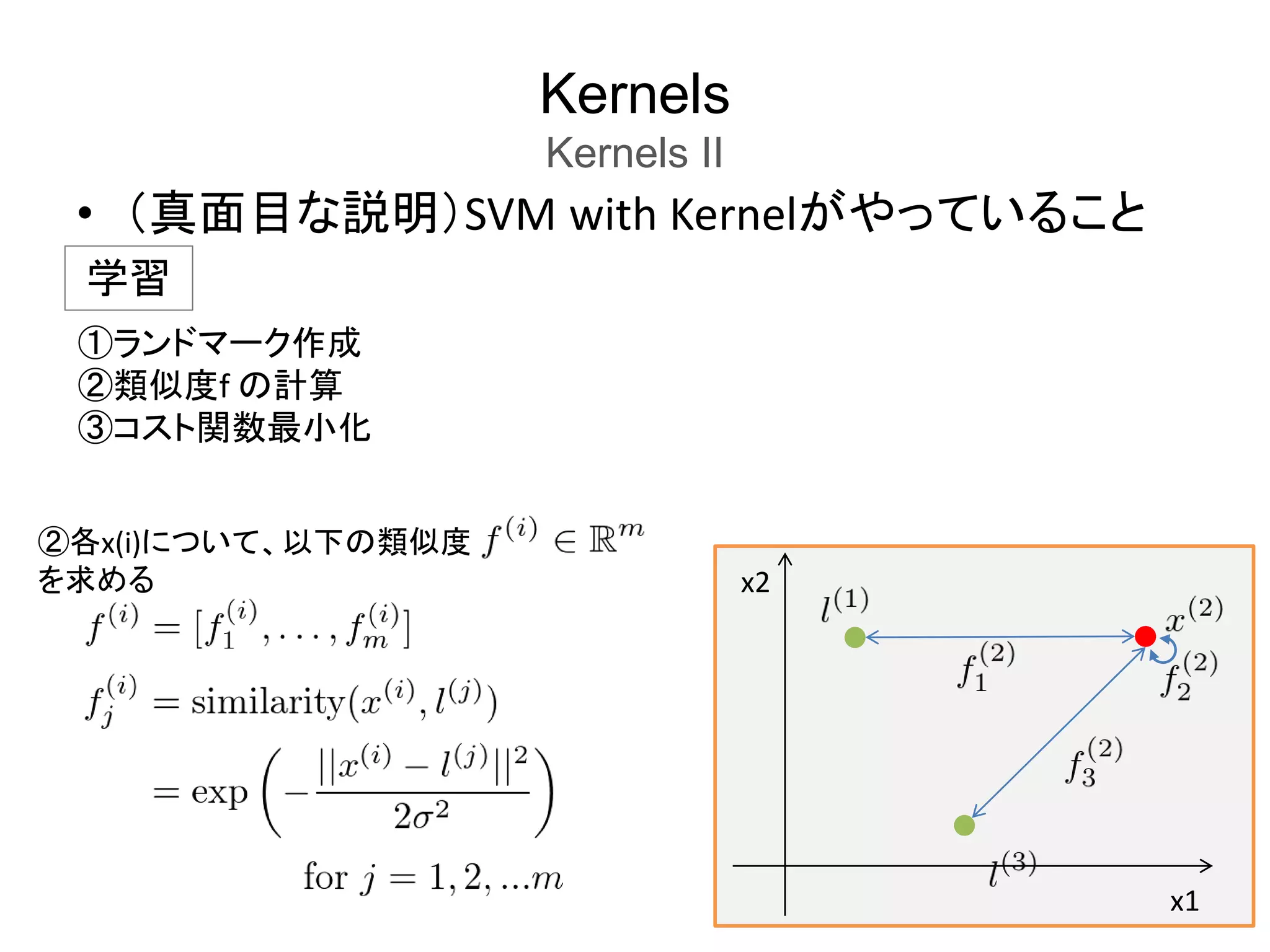
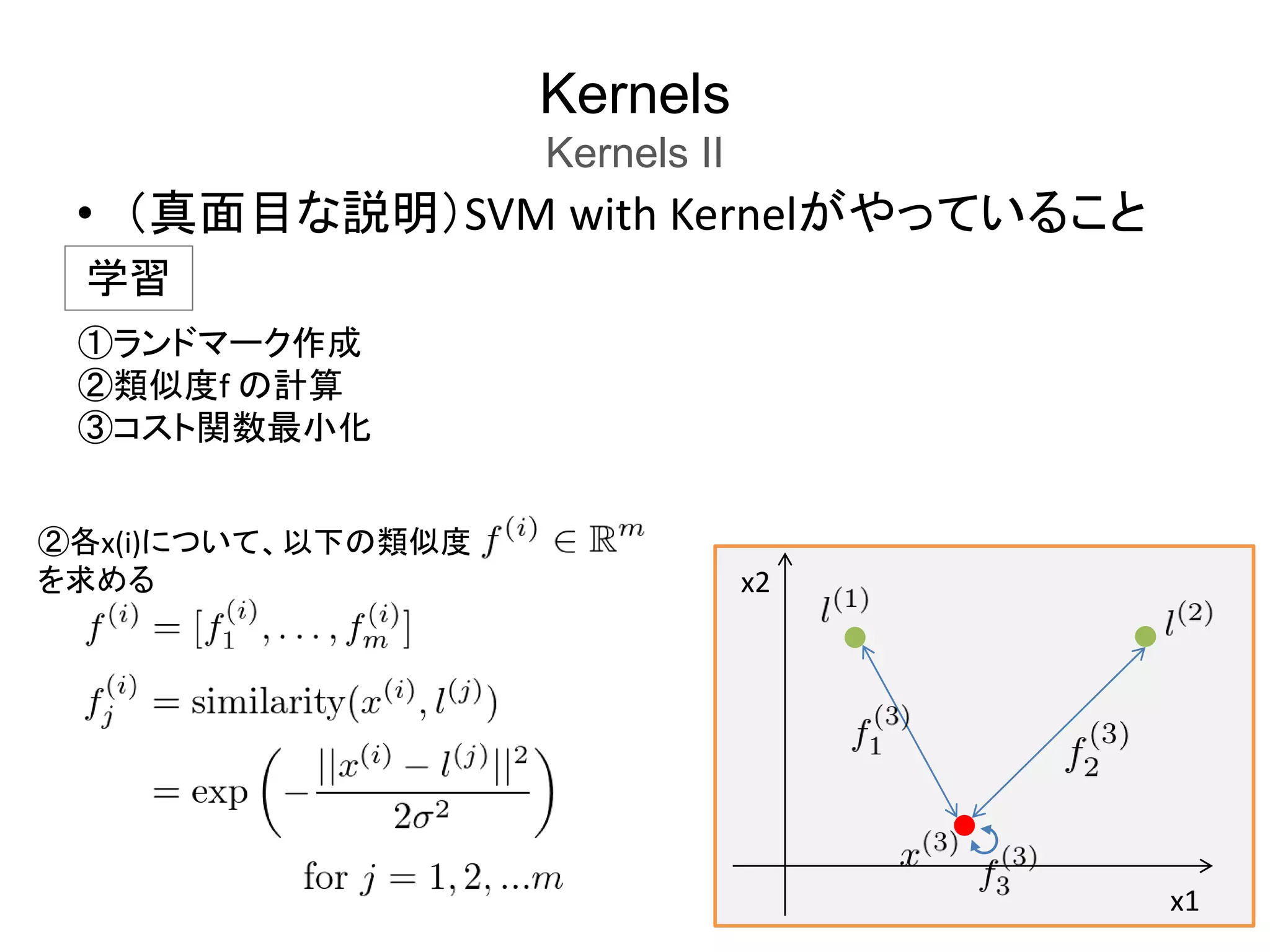
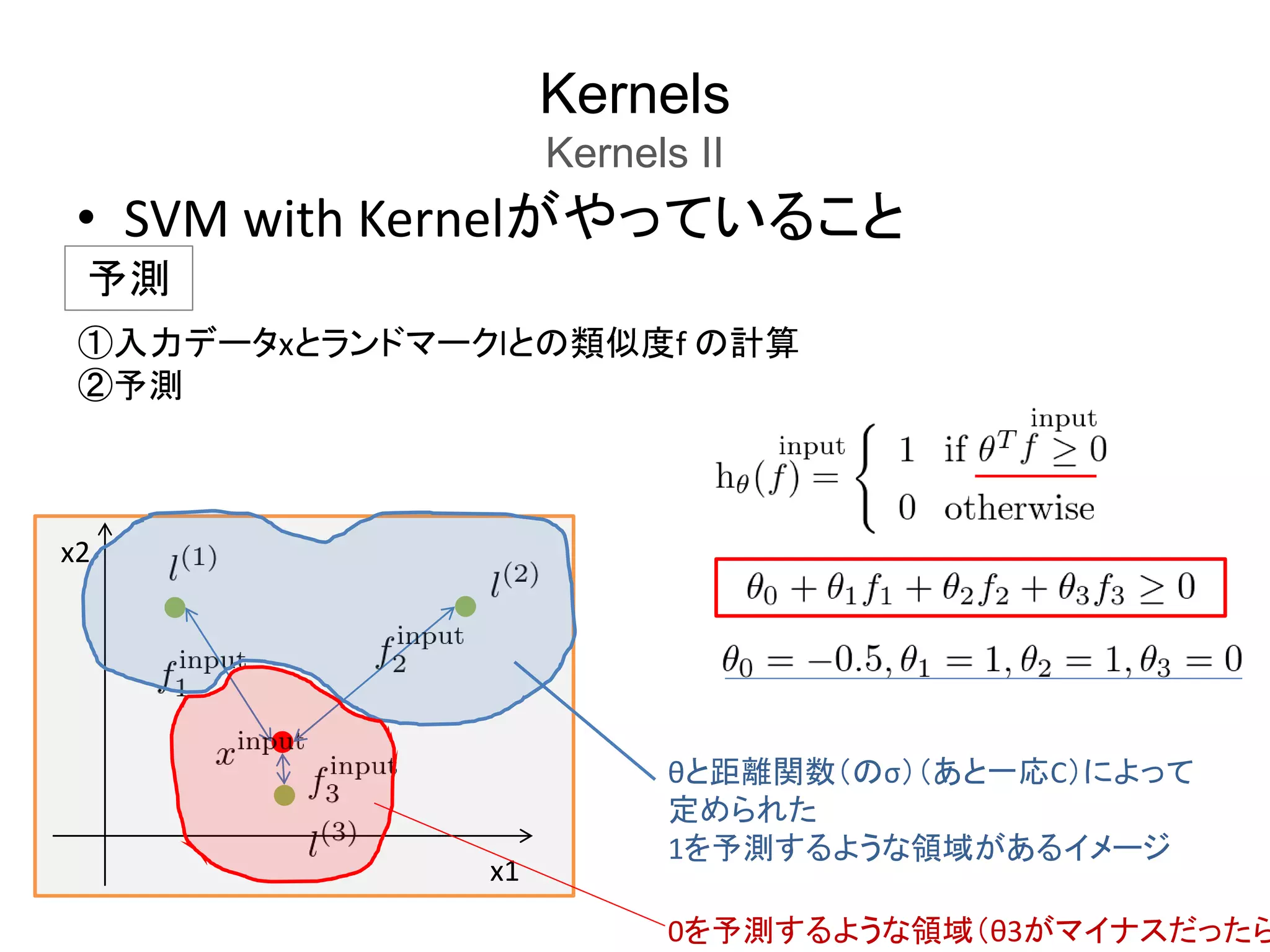
Kernels
Kernels II
SVM
with
Kernel
SVM (withKernel)が持つパラメータは、以下の2つ
• C (= 1/λ)
– 大きい:Lower bias, High variance
– 小さい:Higher bias, Low variance
– ロジスティクス回帰の正規化パラメータが
コスト側についただけ
• σ^2
– 大きい:Lower bias, High variance
– 小さい:Higher bias, Low variance
– ランドマーク周りの1 or 0を予測する領域が
広くなる / 狭くなる感じ
l l
1.0
σ大きい
1.0
σ小さい
32.
agenda
• 講義要約
– LargeMargin Classification
• Optimization Objective
• Large Margin Intuition
• Mathematics Behind Large Margin Classification
– Kernels
• Kernels I
• Kernels II
– SVMs in Practice
• Using An SVM
– Quiz
• 課題
33
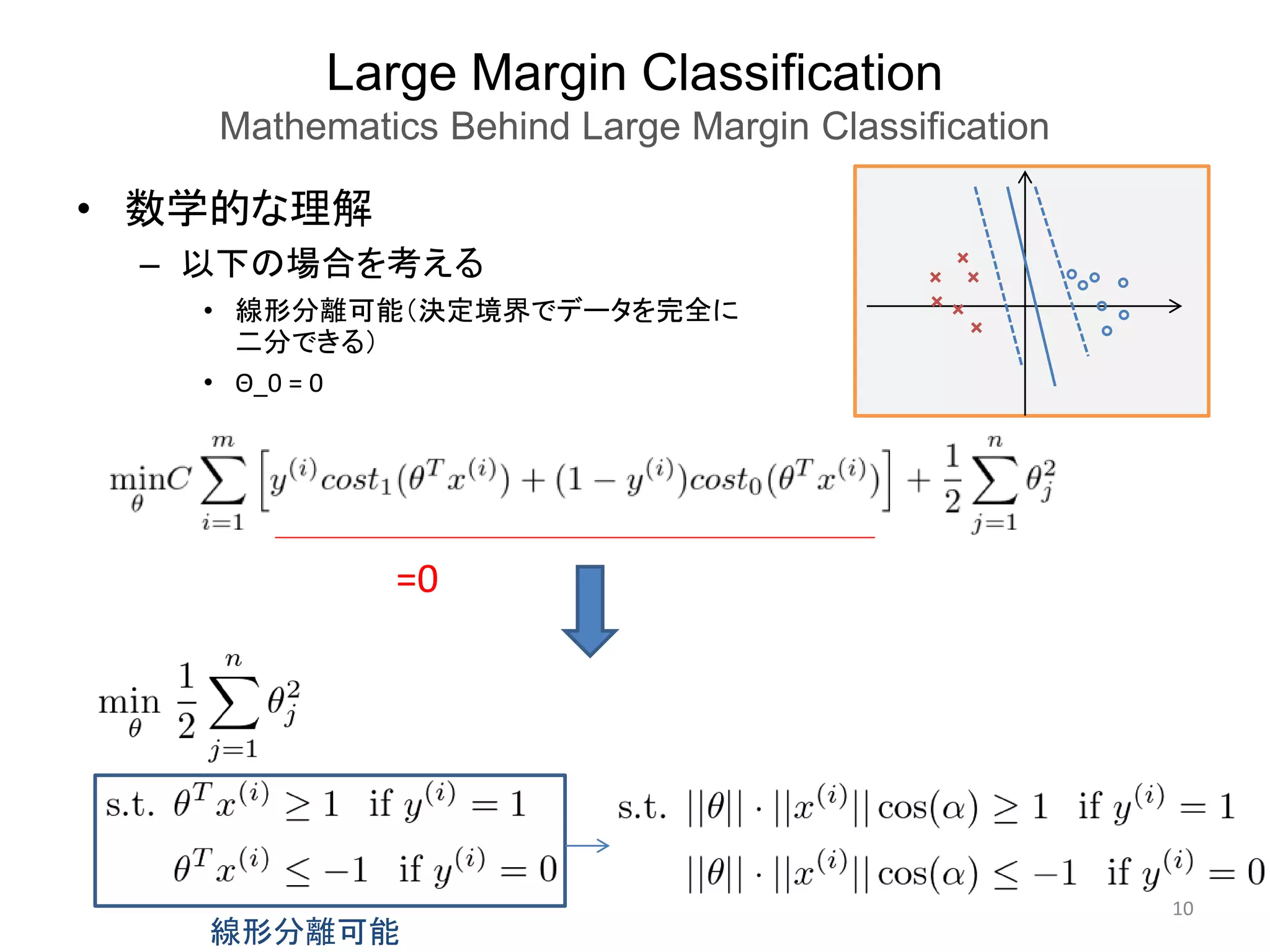
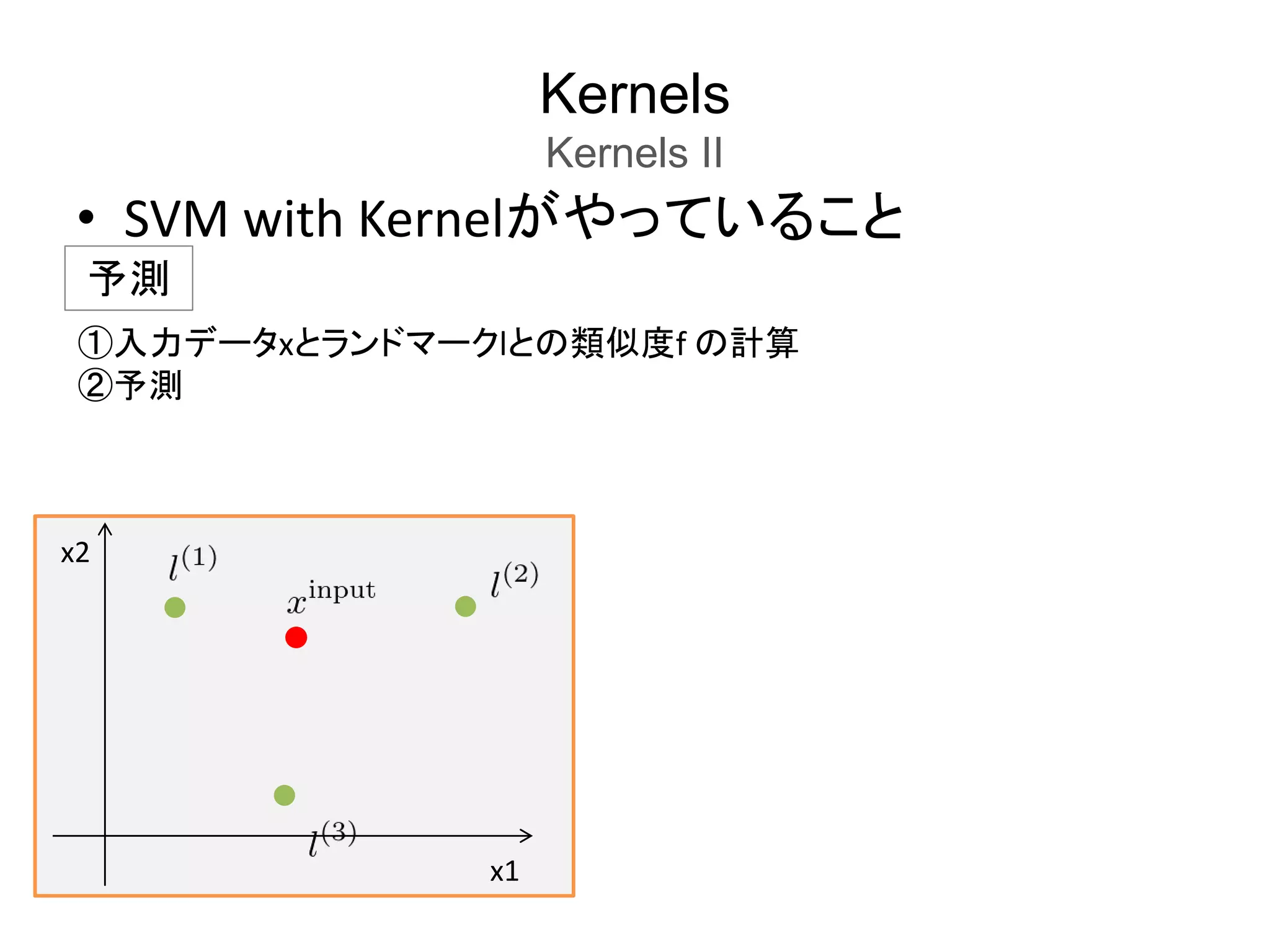
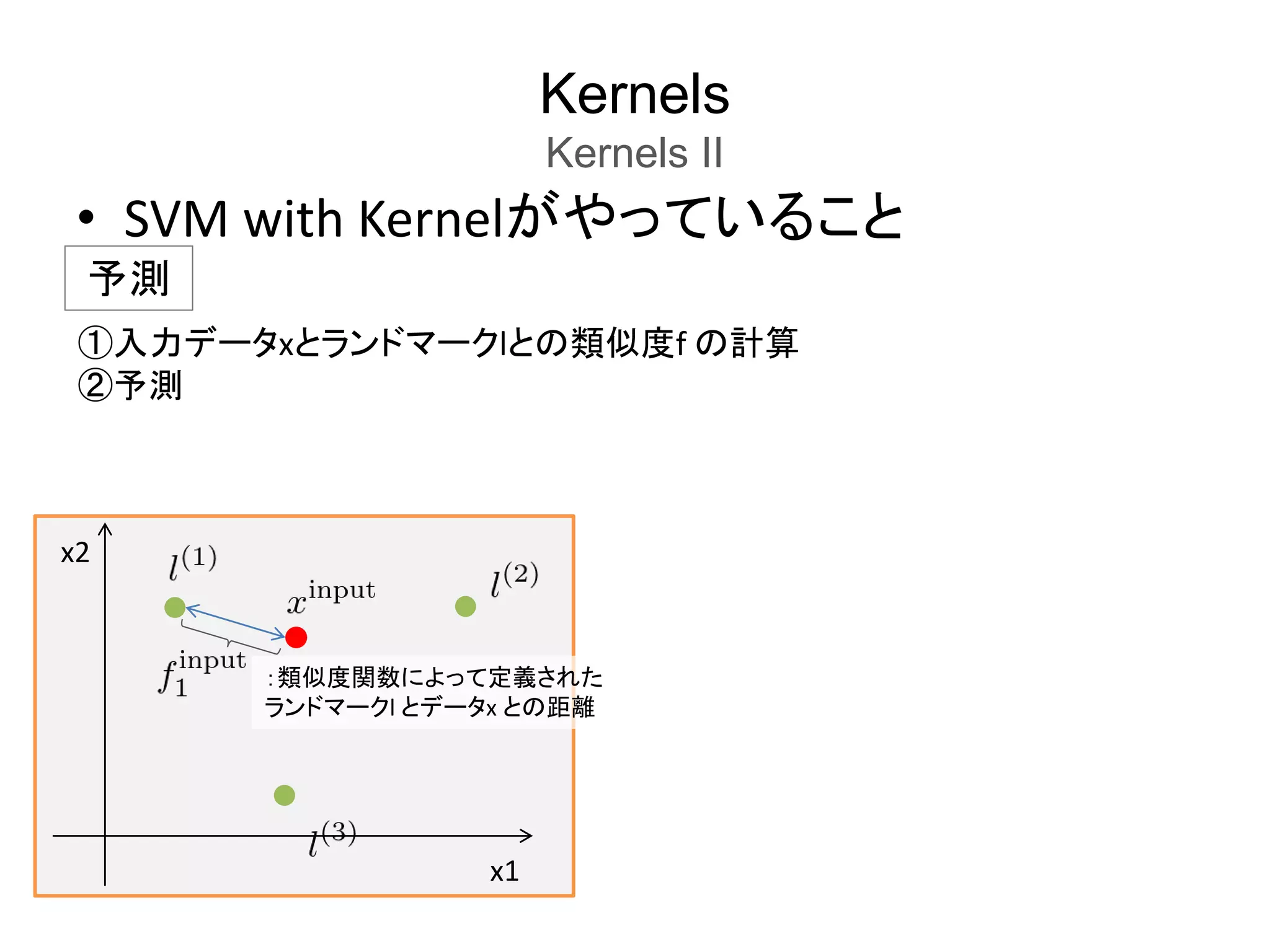
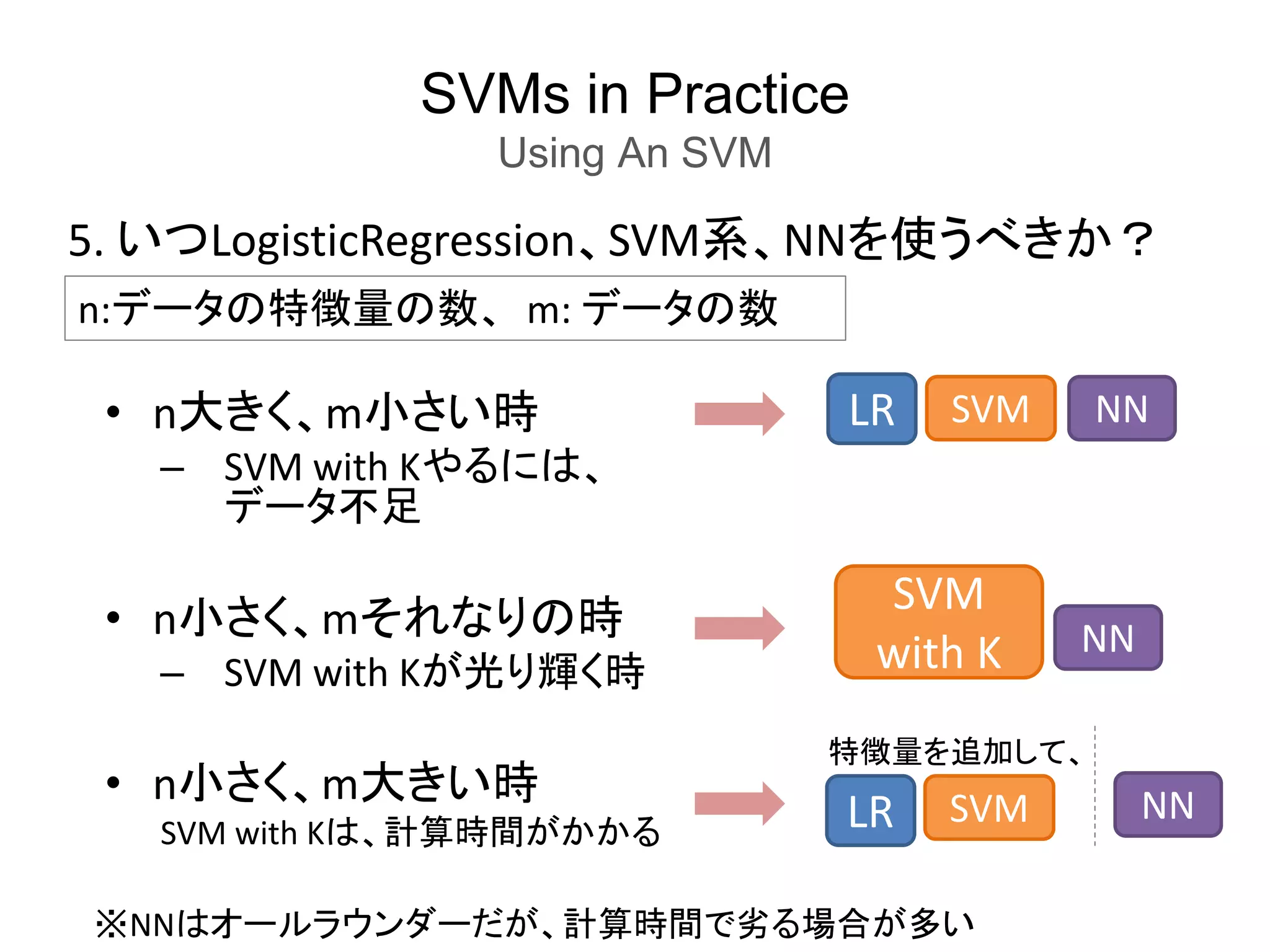
SVMs in Practice
UsingAn SVM
5. いつLogisticRegression、SVM系、NNを使うべきか?
n:データの特徴量の数、 m: データの数
• n大きく、m小さい時
– SVM with Kやるには、
データ不足
• n小さく、mそれなりの時
– SVM with Kが光り輝く時
• n小さく、m大きい時
SVM with Kは、計算時間がかかる
LR SVM
SVM
with K
特徴量を追加して、
NN
LR SVM NN
NN
※NNはオールラウンダーだが、計算時間で劣る場合が多い






















![[DL輪読会]“Submodular Field Grammars Representation” and “Deep Submodular Functi...](https://cdn.slidesharecdn.com/ss_thumbnails/190329dlver2-190329005549-thumbnail.jpg?width=640&height=640&fit=bounds)












































![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






