Download to read offline






















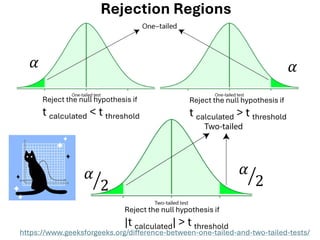
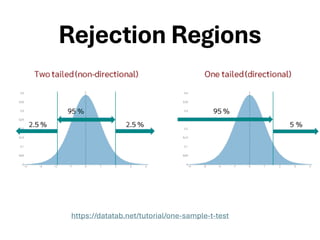
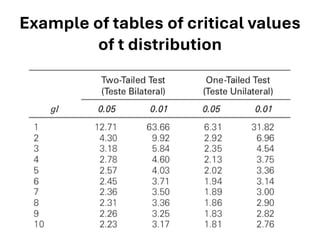
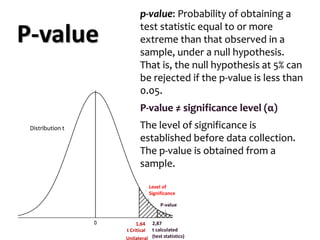





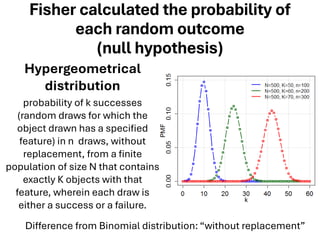

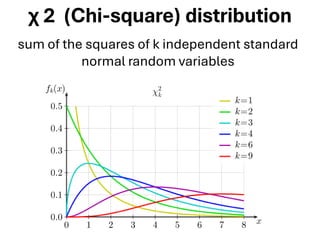
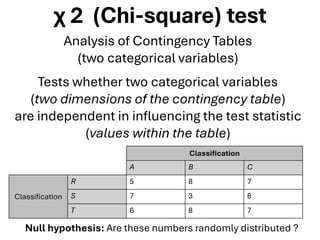



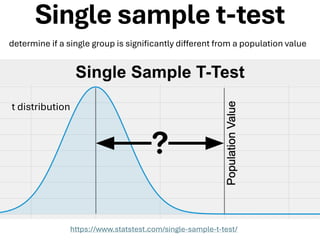
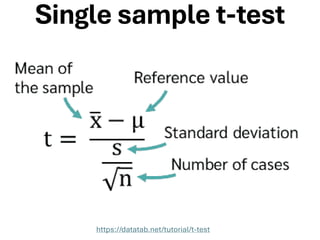
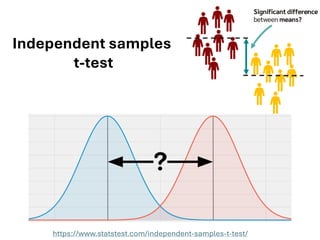

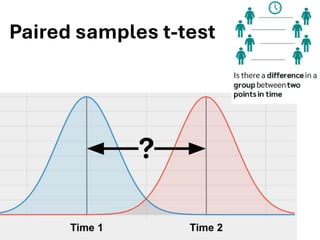
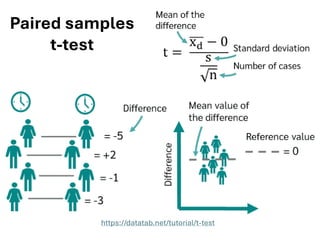




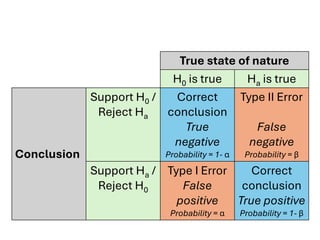

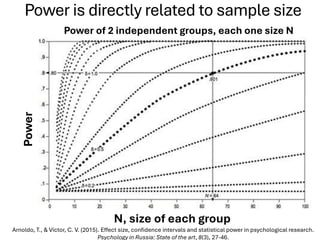
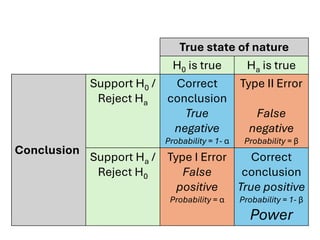
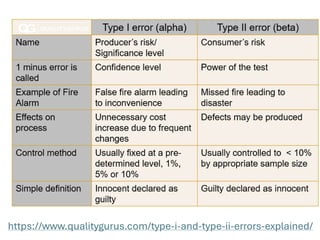
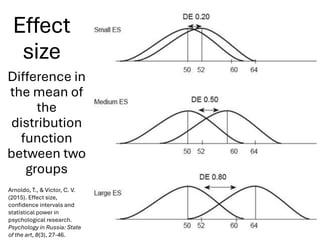

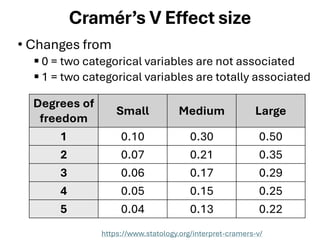

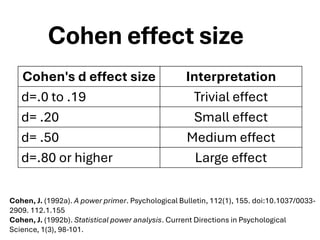
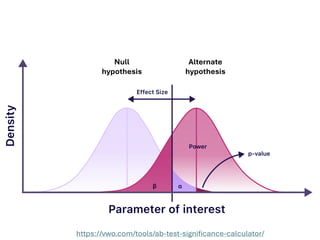

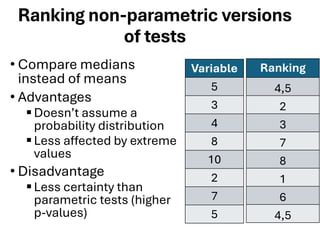

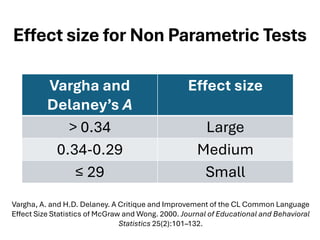

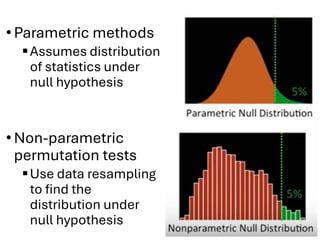


The document explores various statistical methodologies for hypothesis testing, focusing on different paradigms including frequentist, Bayesian, and machine learning approaches. It covers the construction and testing of null and alternative hypotheses, types of statistical errors, p-values, effect sizes, and how to interpret results in environmental data analysis. Additionally, the content includes practical applications of statistical tests using R programming to analyze various data scenarios.



































































