Download to read offline






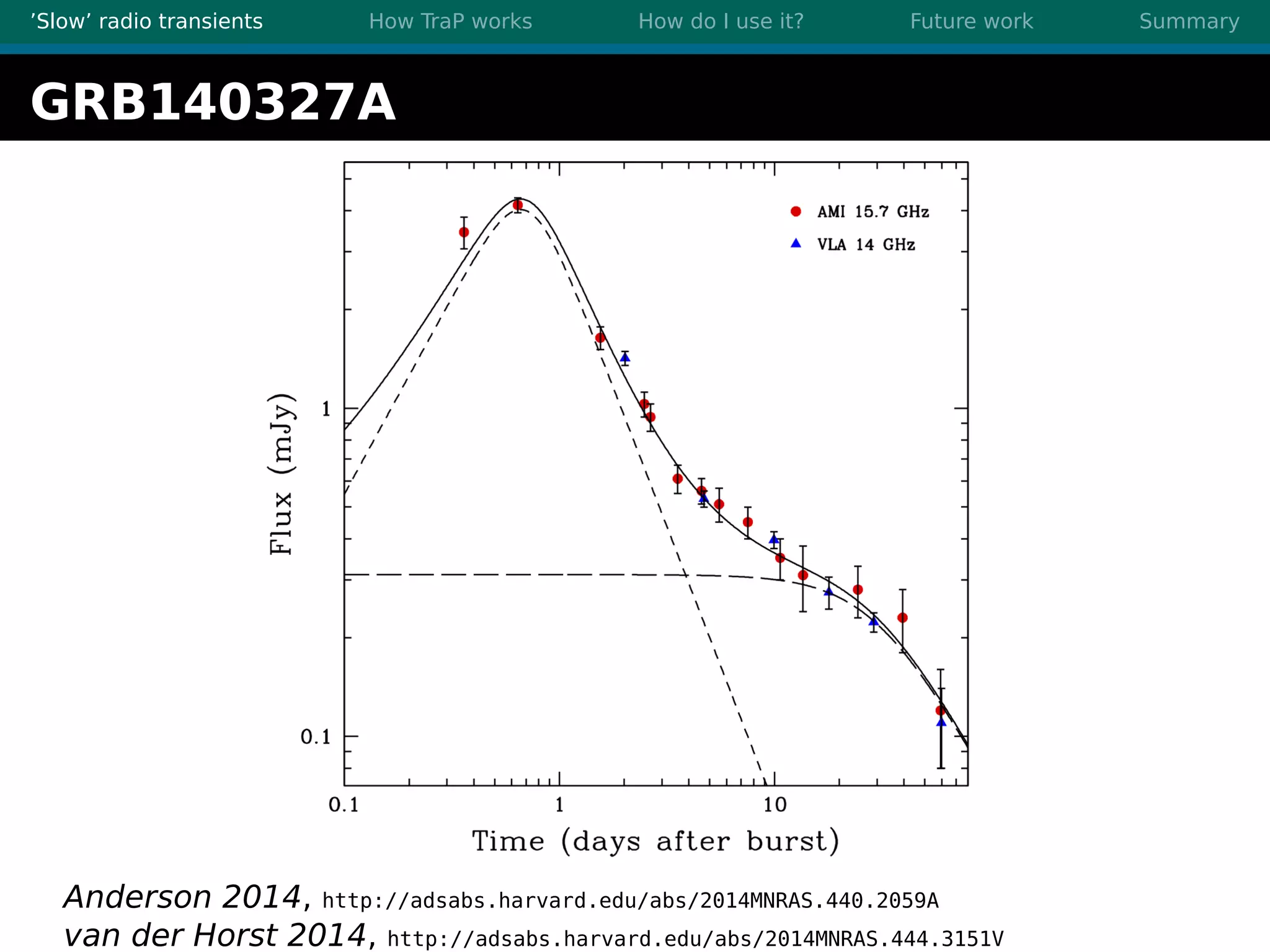
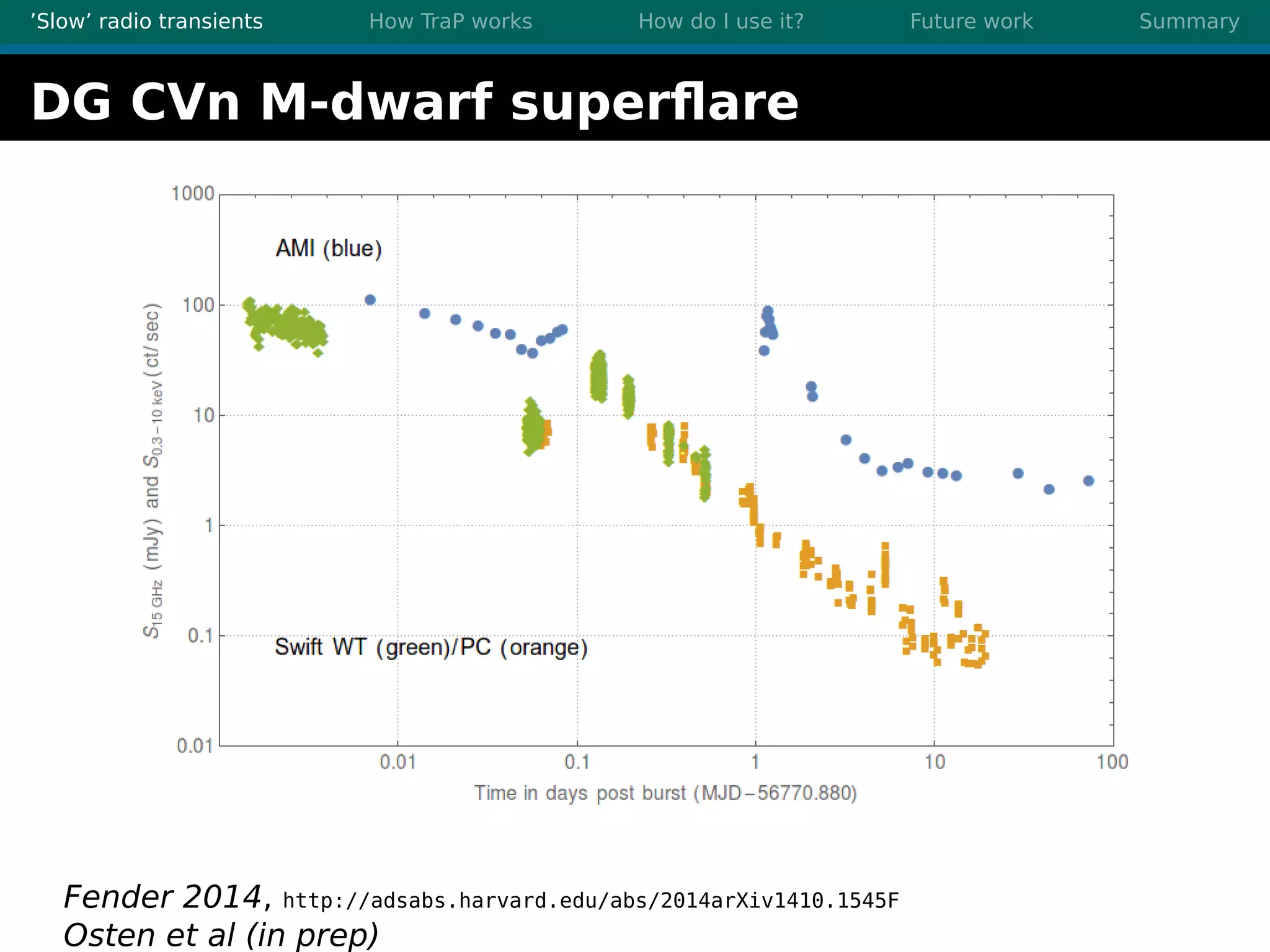

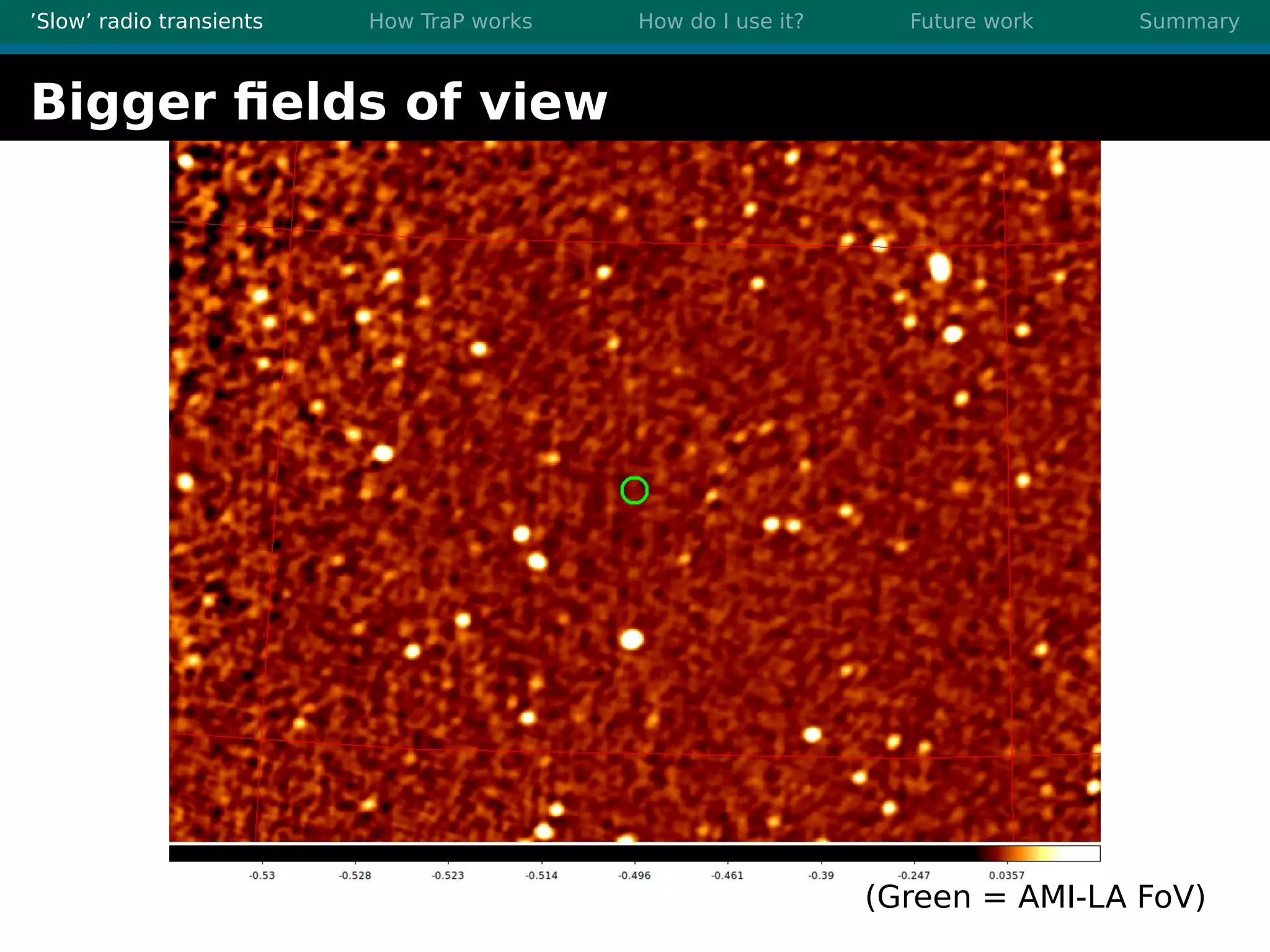
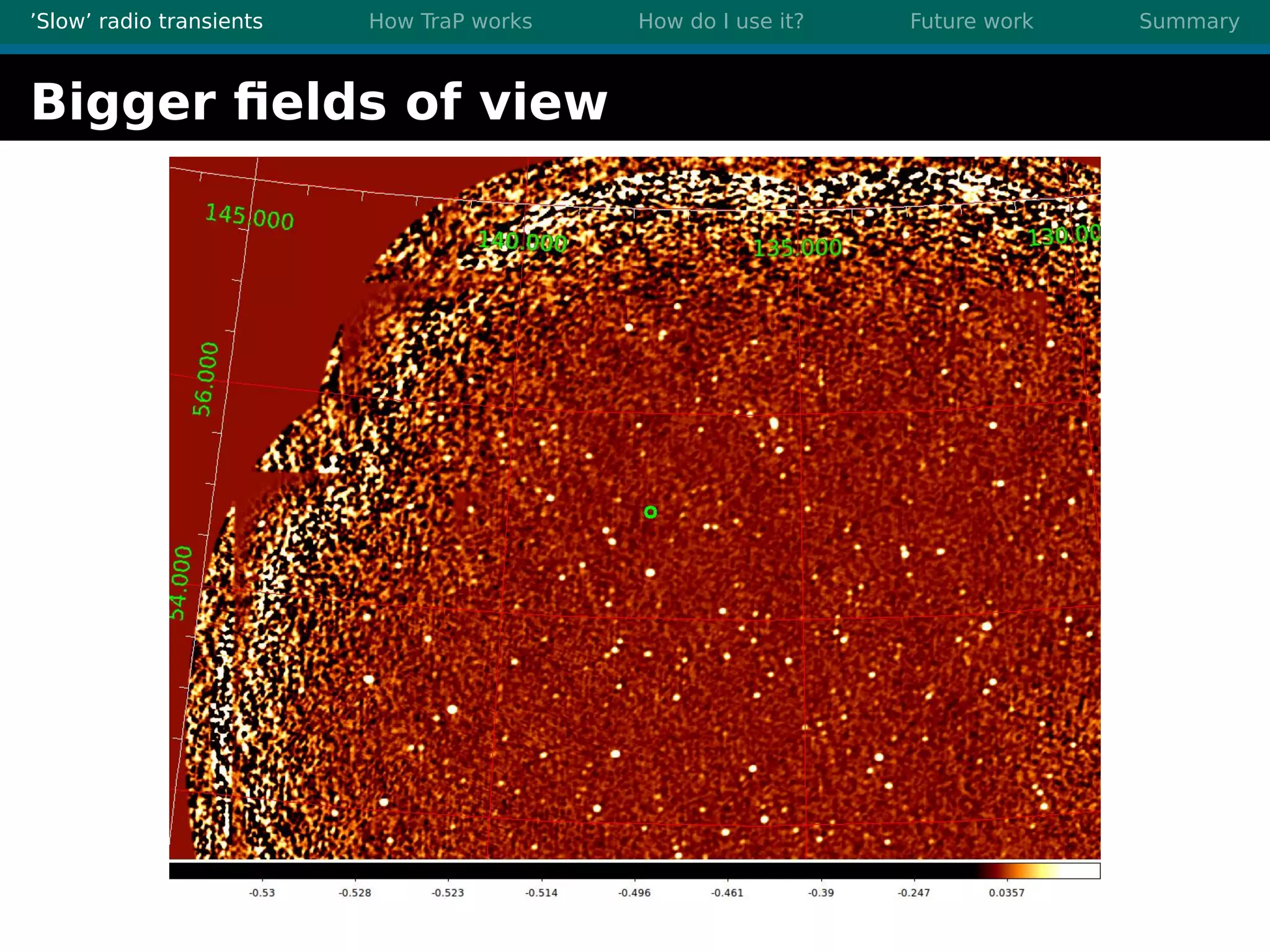
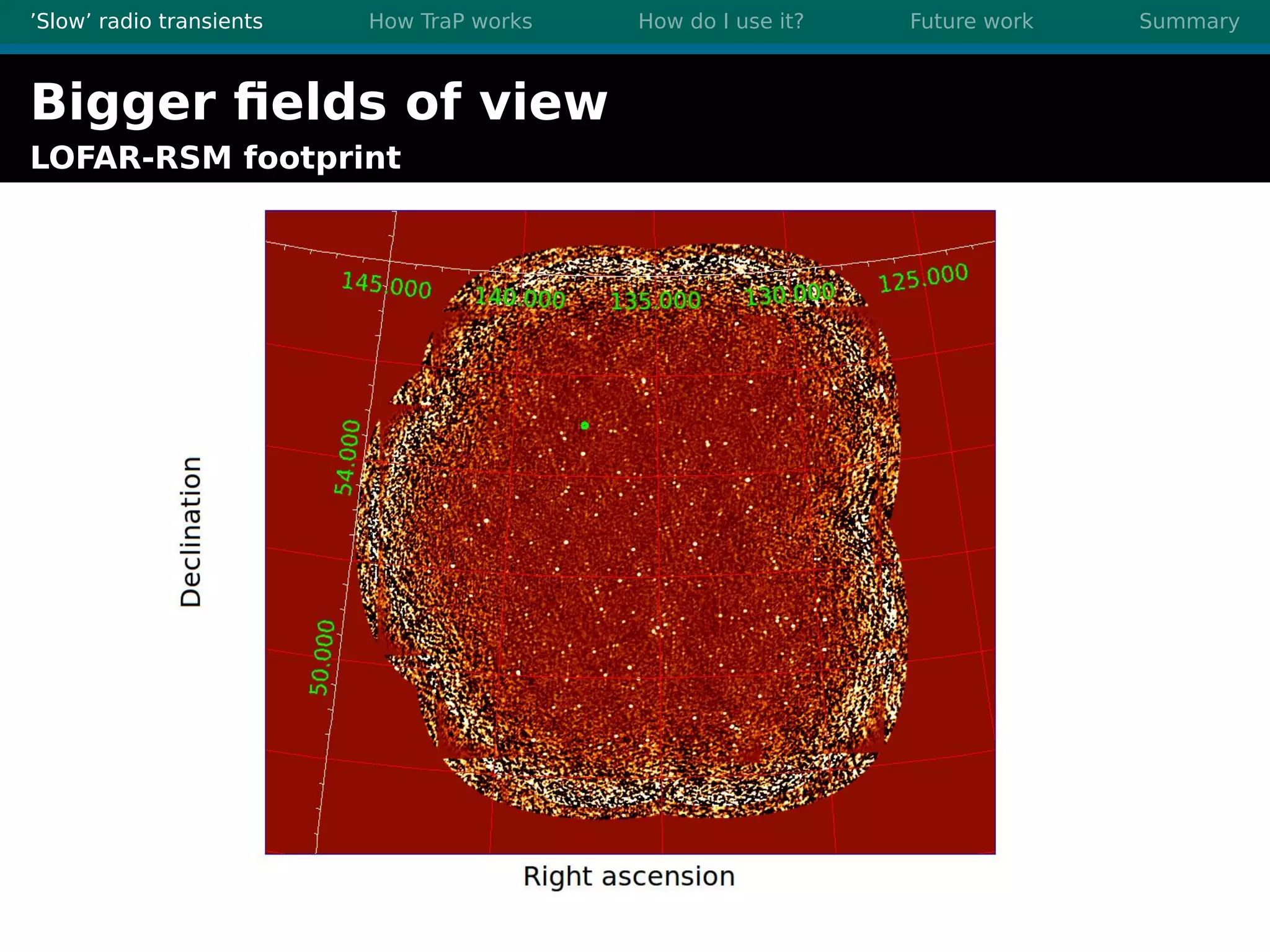









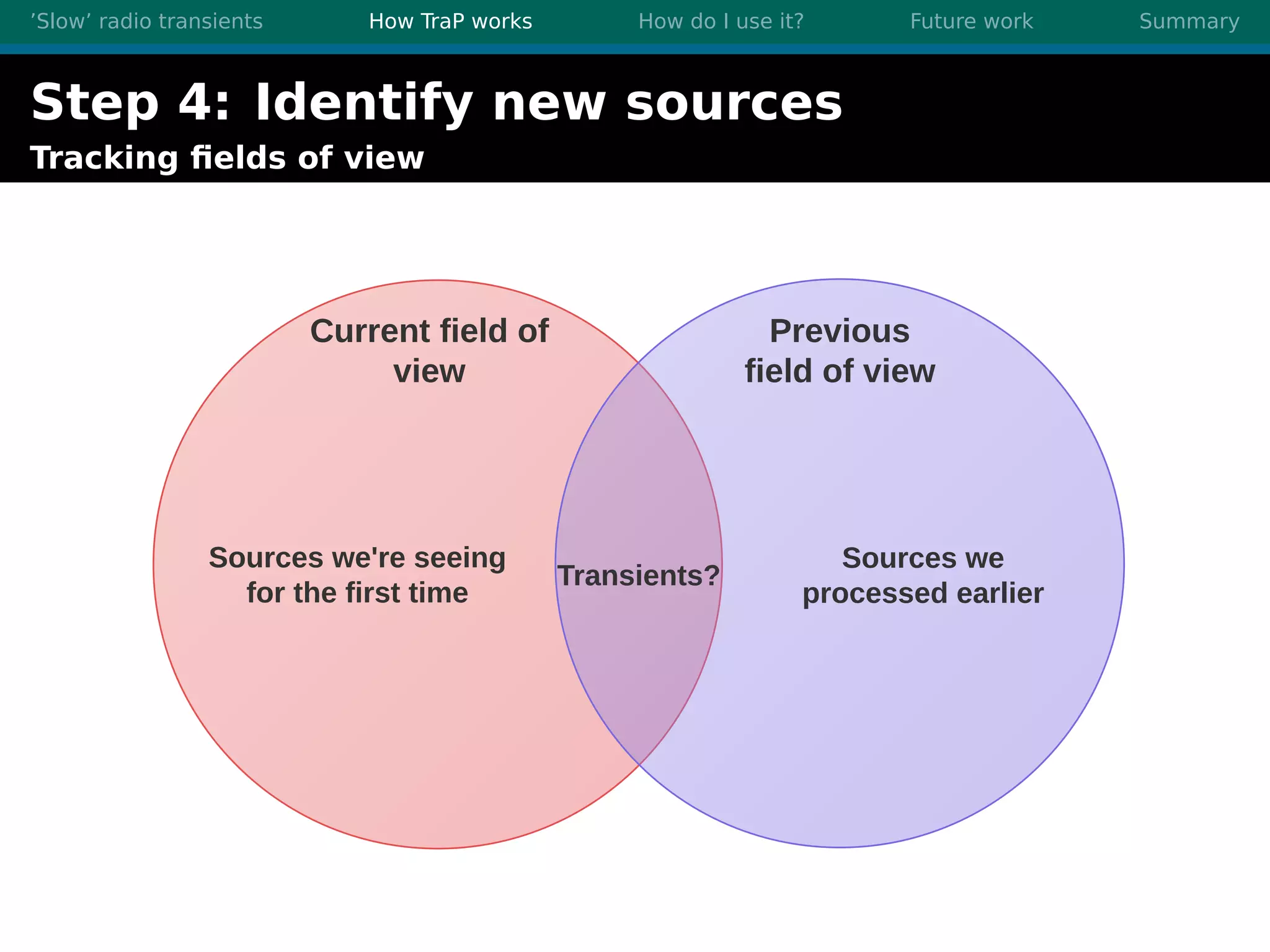
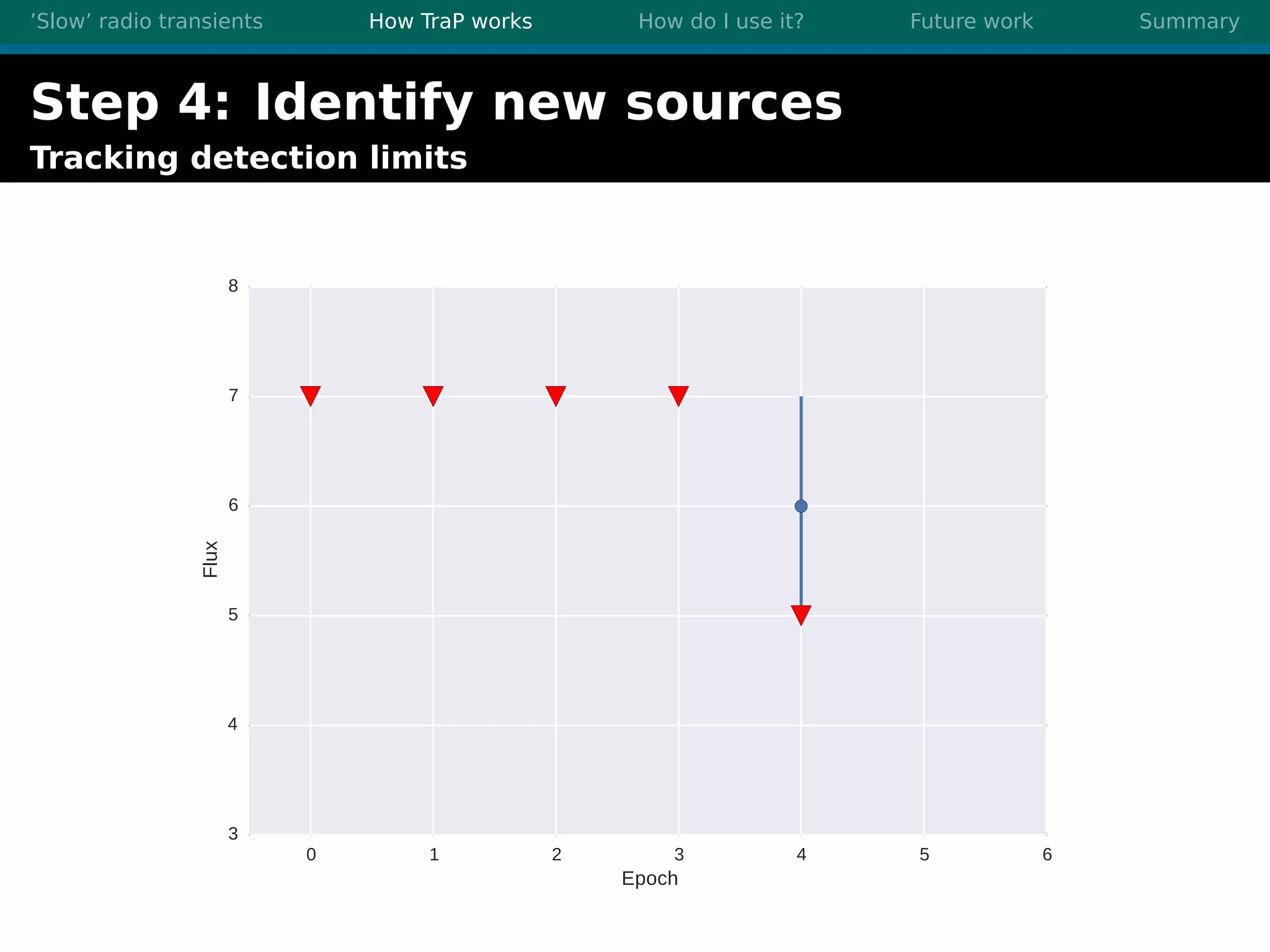
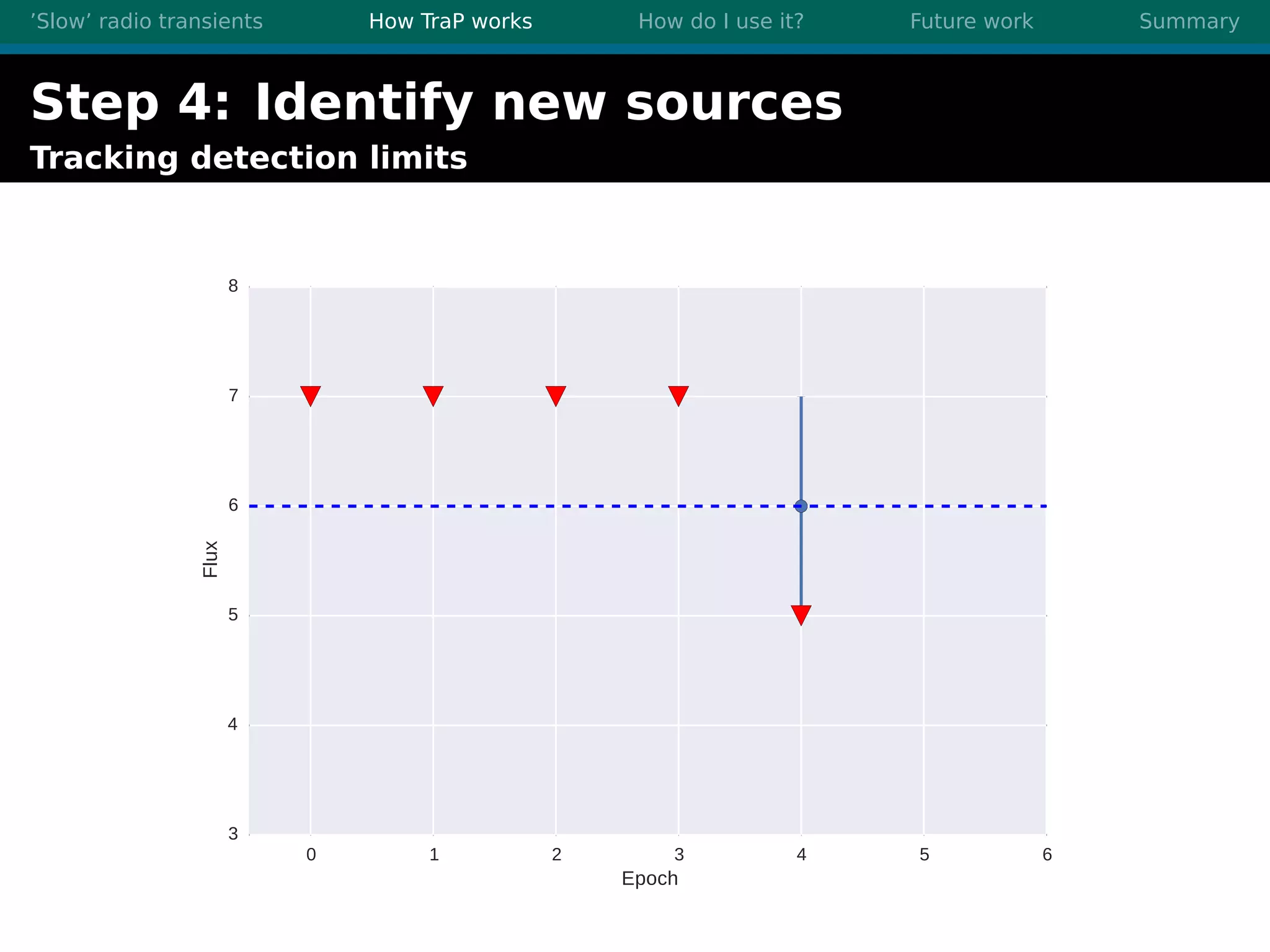
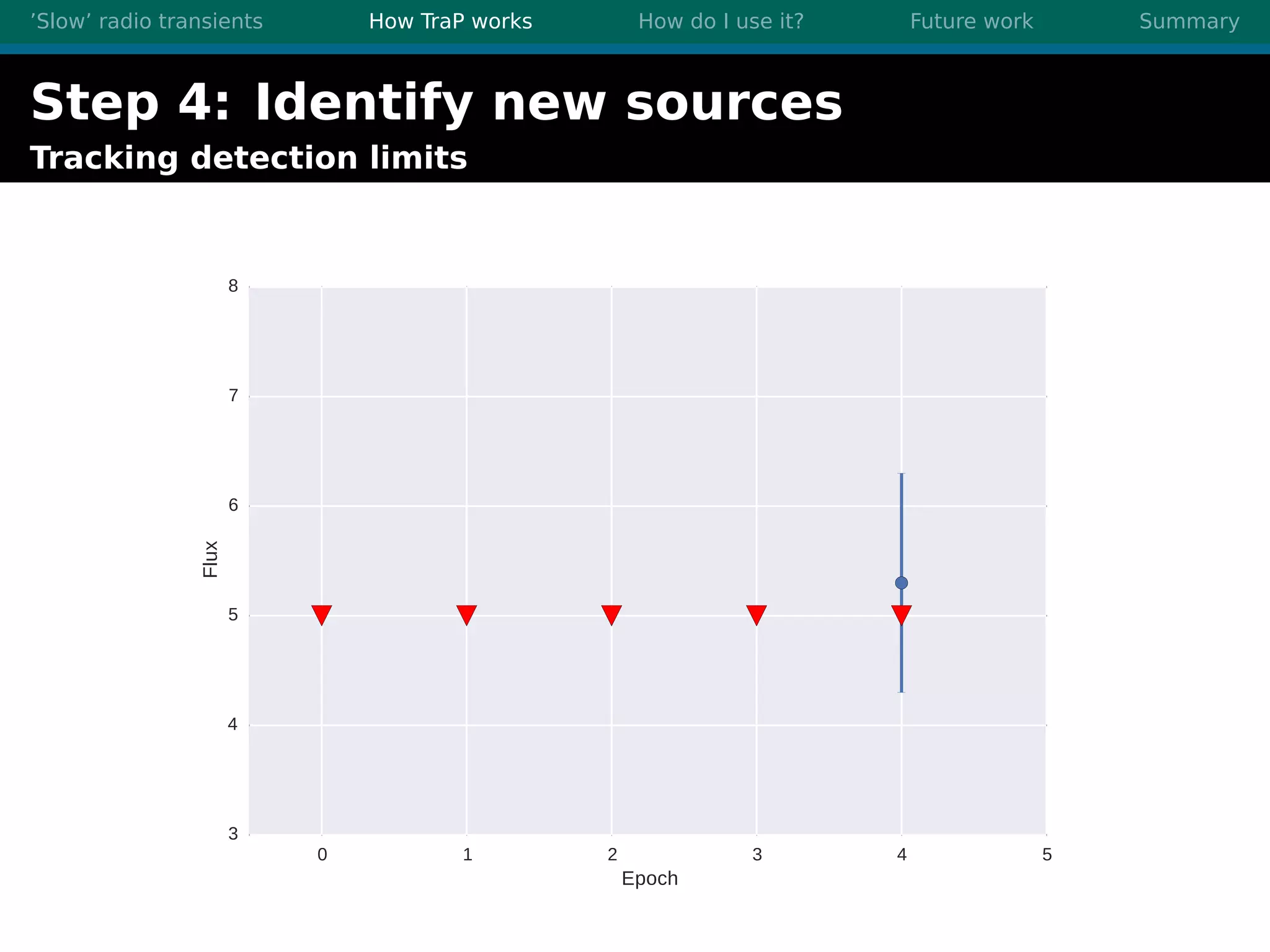
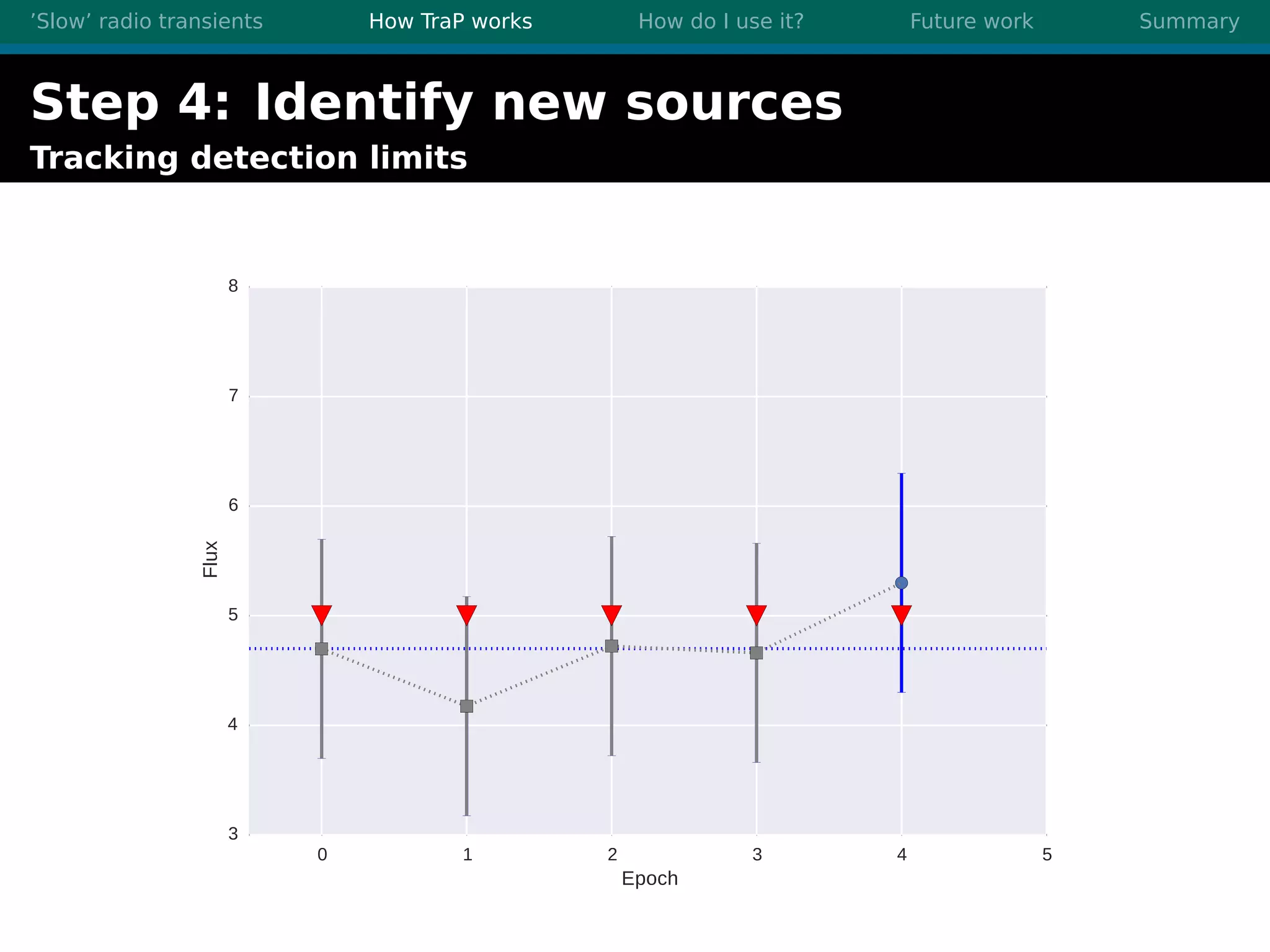
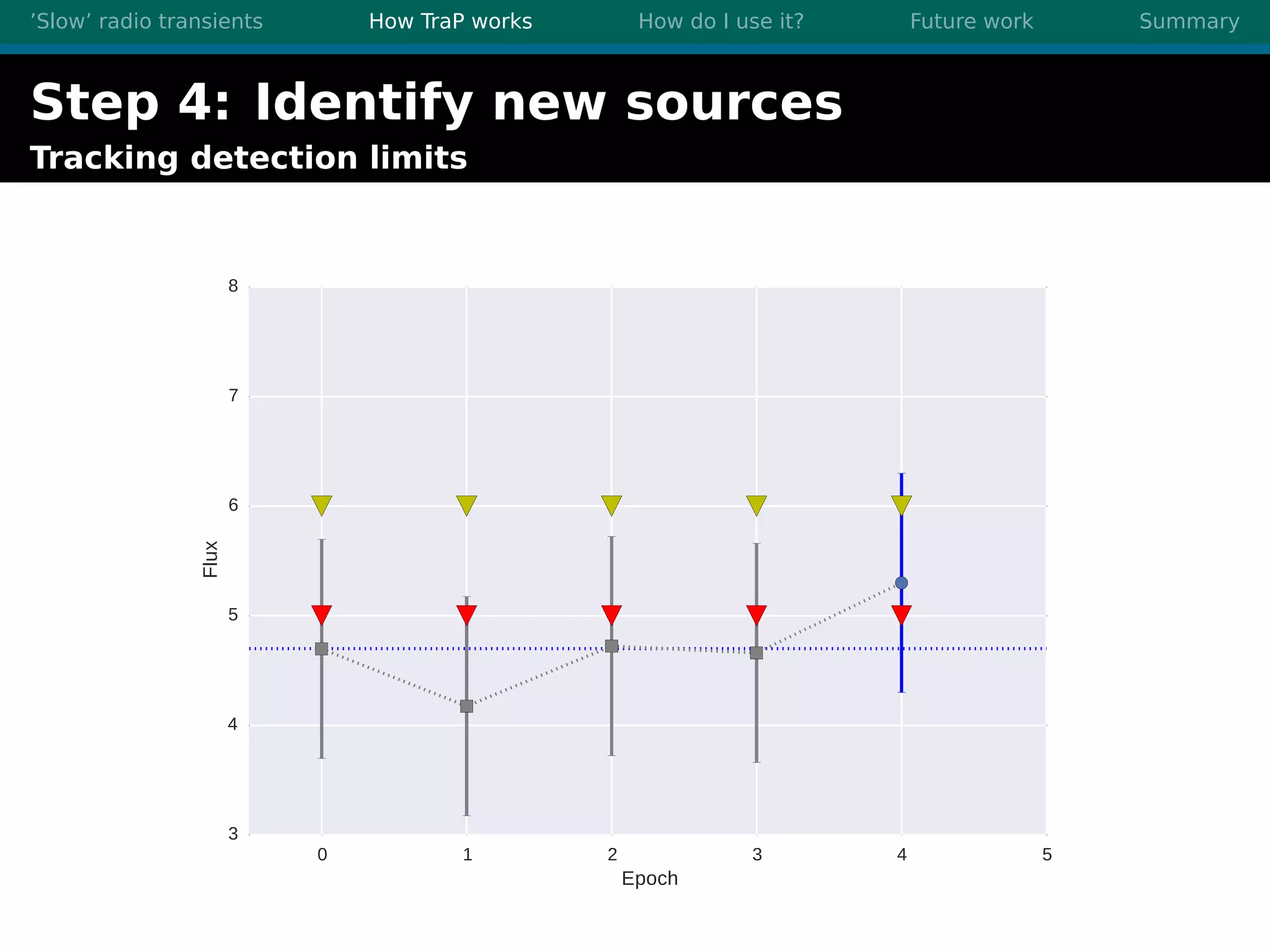
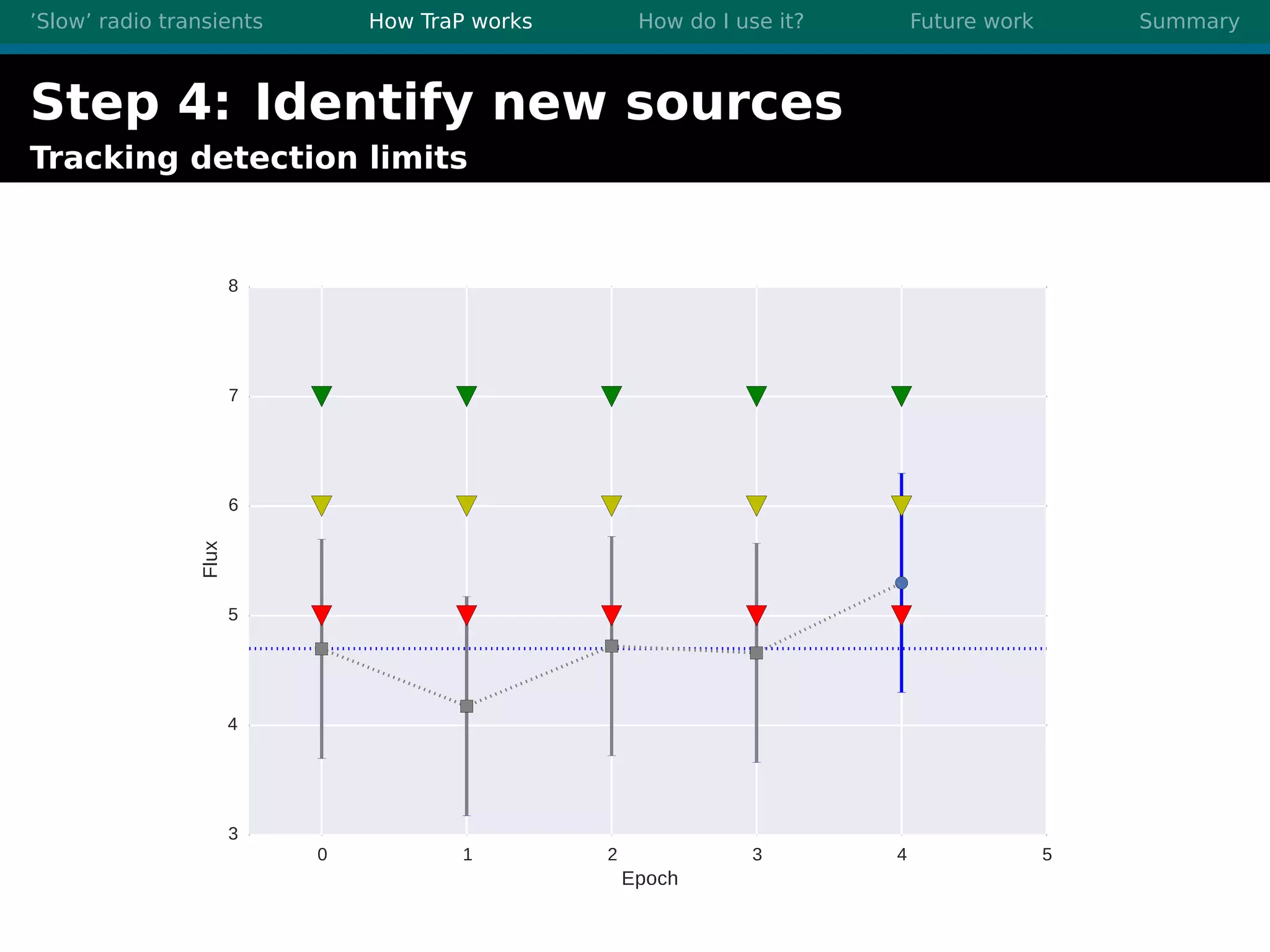

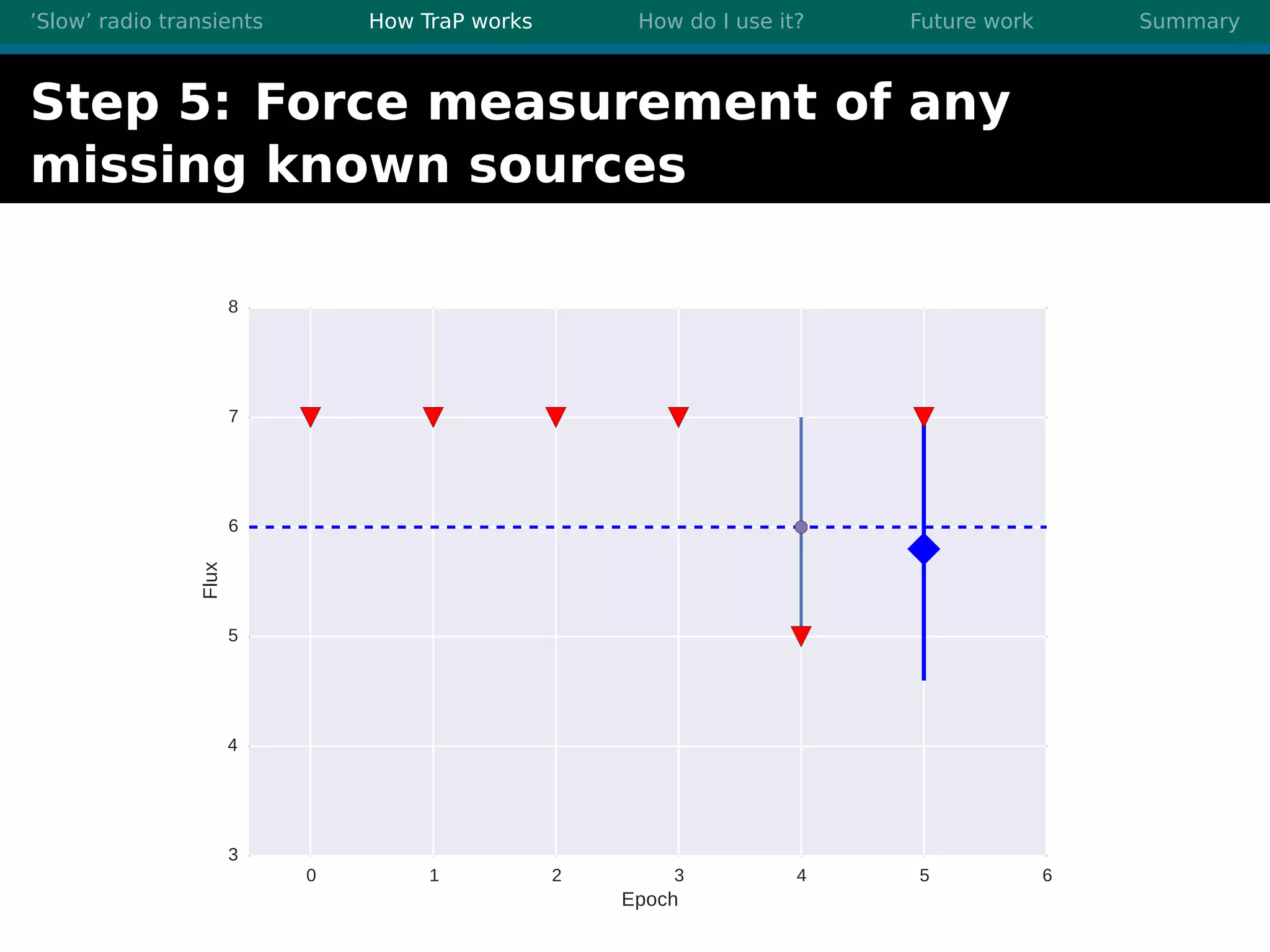









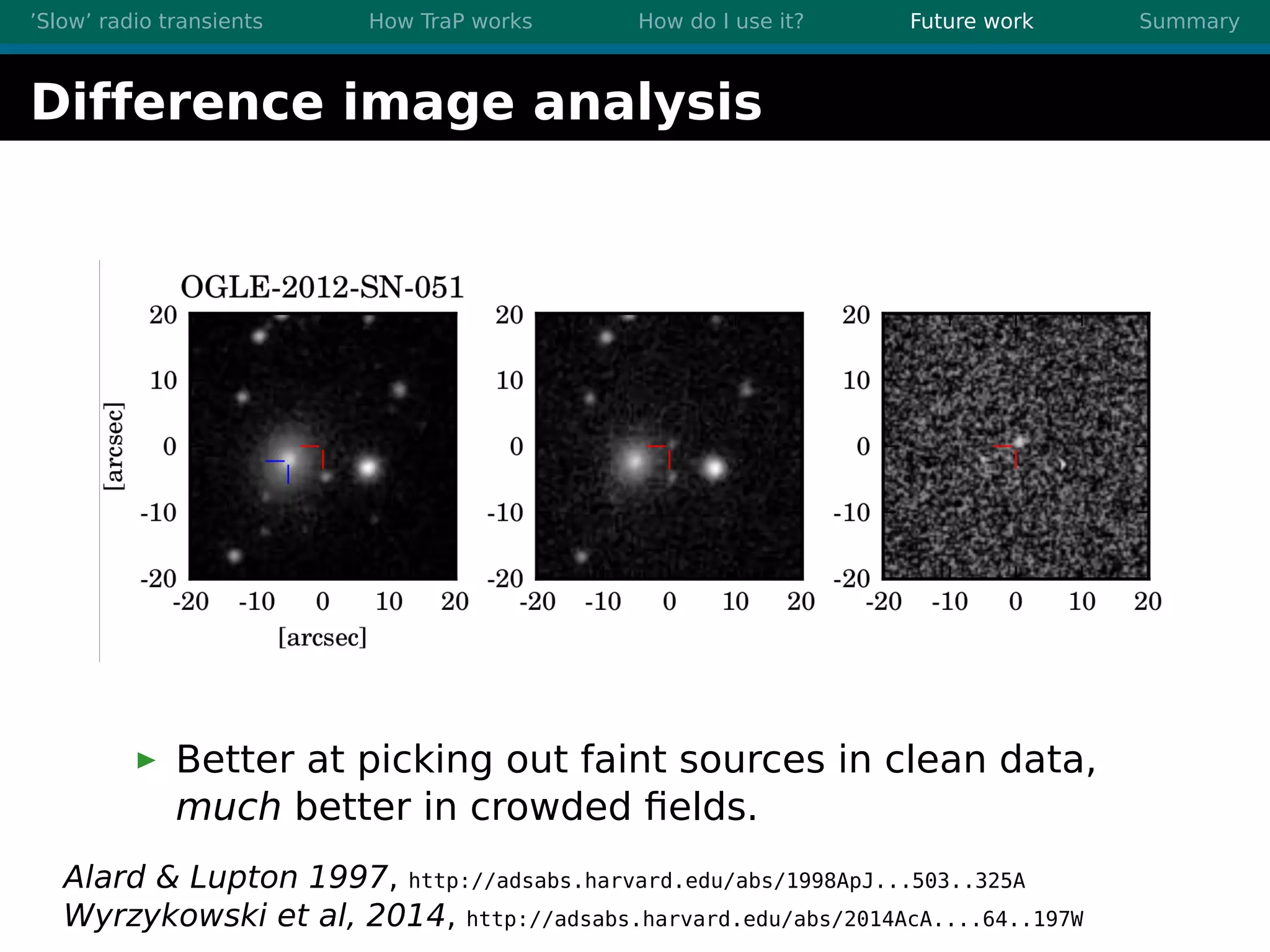





There are three main points summarized: 1. There are many interesting slow radio transients that could be detected through imaging surveys like accretion flares, orphan gamma-ray bursts, and flare stars. 2. Radio surveys are increasing in sensitivity and field of view by orders of magnitude with instruments like LOFAR, enabling the detection of more rare transient events. 3. TraP is a transient detection pipeline that works by extracting sources from radio images, matching to known sources, identifying new bright sources, analyzing light curves, and making the results accessible through a user-friendly web interface.
![[DT2015] CLASS02](https://cdn.slidesharecdn.com/ss_thumbnails/02classdefinition-150913082002-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)















































