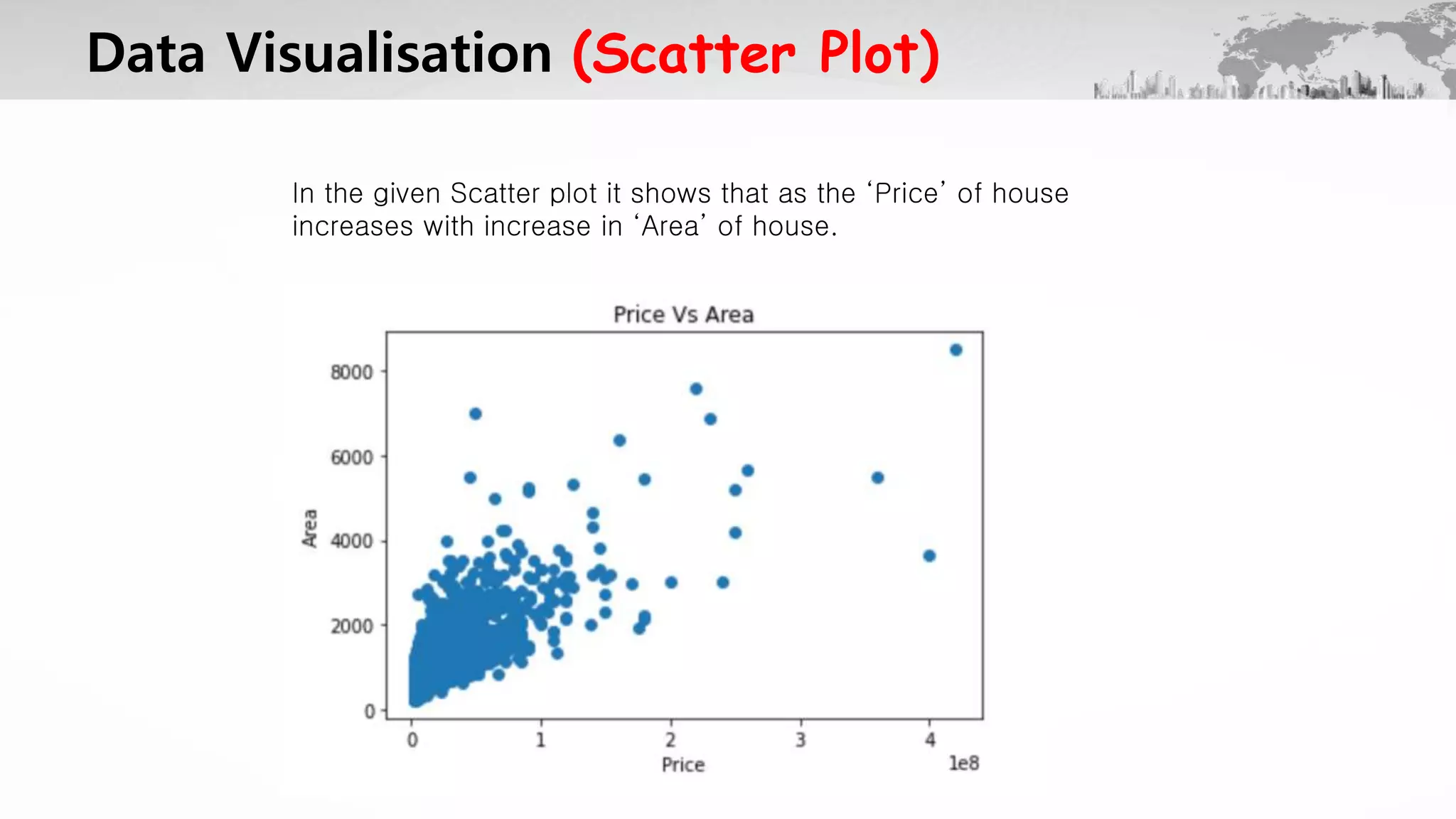
The project aims to predict house prices in Mumbai using machine learning techniques to address the challenges of finding accurate pricing in the real estate market. A dataset comprising 6,338 records and 17 variables, including area and number of bedrooms, was analyzed using models like linear regression, decision tree, and random forest, with random forest achieving the highest accuracy of approximately 46%. The document also includes various data visualization techniques to illustrate the relationships between different parameters and house prices.