HDP(Hortonworks Data Platform)をWindows 8にインストールしてWordCountを動かすまでの手順を説明します。 おまけでHive on Tezの手順もついています。


![HadoopとWindows
Hadoopと言えば
Linuxオンリー(*1)
- Linuxのコマンドを直たたきする
public class ProcessTree {
private static boolean isSetsidSupported() {
ShellCommandExecutor shexec = null;
boolean setsidSupported = true;
try {
String[] args = {"setsid", "bash", "-c", "echo $$"};
shexec = new ShellCommandExecutor(args);
shexec.execute();
} catch (IOException ioe) {
:
}
}
- パスの区切り文字の一貫性の無さ
- File.separatorを使ったり、"/"を使ったり
- JNIを使用する
- soファイルは同梱されるが、dllは同梱されない
- Cygwinでスタンドアロンモードは動くが...
WindowsでHadoopは「茨の道」
ここ
*1 http://www.cloudera.com/content/cloudera/en/documentation/core/latest/topics/cdh_ig_req_supported_versions.html](https://image.slidesharecdn.com/hdponwindows-141106195917-conversion-gate01/85/HDP-Windows-3-320.jpg)


![[おまけ]Hive on Tezのインストール(1/3)
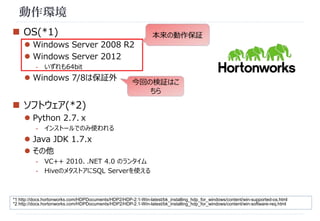
HDPのインストーラを起動する
インストーラで「変更」はできず、再インストールが必要
事前にSQL Serverなど周辺環境を揃えておくこと(後述)
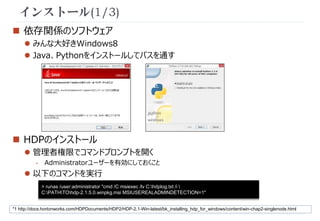
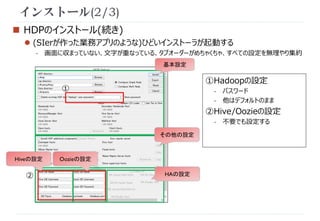
Hiveの設定
①
①Hive/Oozieの設定
- DB名
- ユーザー名
- パスワード
- SQLServerを使用する(画面から
見切れている)
- Oozieは不要でも設定する
②Tezを利用する
- 「Use Tez in Hive」にチェックを入
れる
基本設定
②
Oozieの設定](https://image.slidesharecdn.com/hdponwindows-141106195917-conversion-gate01/85/HDP-Windows-10-320.jpg)
![[おまけ]Hive on Tezのインストール(2/3)
メタストア用DBの準備
SQL Server (Express) のインストール
- 構成マネージャーでTCP/IPの接続を許可、TCPポート:1433を設定する(*1)
DB、ユーザーの作成
- インストーラで設定するDB名、ユーザー名で作成する
テーブルの作成
- C:hdphive-0.13.0.2.1.5.0-2060scriptsmetastoreupgrademssqlhive-schema-
0.13.0.mssql.sql をSQL Server Management Studio で流す
SQL ServerのJDBCドライバ
- sqljdbc4.jar をC:hdphive-0.13.0.2.1.5.0-2060lib に配置する
*1 http://symfoware.blog68.fc2.com/blog-entry-920.html](https://image.slidesharecdn.com/hdponwindows-141106195917-conversion-gate01/85/HDP-Windows-11-320.jpg)
![[おまけ]Hive on Tezのインストール(3/3)
ファイアウォールの設定
無効にできる環境であれば、無効にする
SQL Serverのポート
- TCP:1433
- UDP:1434(管理用)
メタストアサーバのポート
- TCP:9083
HiveおよびTezの環境を用意する
Hive用のディレクトリを作成する
> hadoop fs -mkdir -p /user/hive/warehouse
Tezのライブラリを配置する
> hadoop fs -put C:hdptez-0.4.0.2.1.5.0-2060* /apps/tez](https://image.slidesharecdn.com/hdponwindows-141106195917-conversion-gate01/85/HDP-Windows-12-320.jpg)
![[おまけ]Hive on Tezの実行(1/2)
Hiveコマンドで実験
適当なtsvファイルを用意する
> type c:tempt_user.tsv
1 aaa
2 bbb
3 ccc
Hiveコマンドを起動
> c:hdphive-0.13.0.2.1.5.0-2060binhive
テーブルを作成してデータをロード
hive> CREATE TABLE t_user (
id int,
name string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY 't'
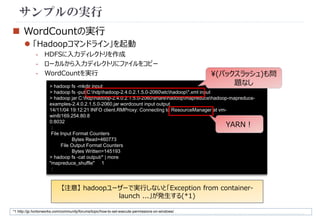
(バックスラッシュ)も問
LINES TERMINATED BY 'n'
題なし
;
hive> LOAD DATA LOCAL INPATH 'C:Tempt_user.tsv' OVERWRITE INTO TABLE t_user;
:
Loading data to table t_user](https://image.slidesharecdn.com/hdponwindows-141106195917-conversion-gate01/85/HDP-Windows-13-320.jpg)
![[おまけ]Hive on Tezの実行(2/2)
Hiveコマンドで実験(つづき)
- クエリを実行
hive> select * from t_user order by id;
Query ID = hadoop_20141105214242_ce859abf-10b5-47fd-8304-9765b5f08694
Total jobs = 1
Tezで実行されている
Launching Job 1 out of 1
Tez session was closed. Reopening...
Session re-established.
:
Status: Running (application id: application_1415164941328_0005)
:
Map 1: -/- Reducer 2: 0/1
Map 1: 0/1 Reducer 2: 0/1
:
Status: Finished successfully
OK
1 aaa
2 bbb
3 ccc](https://image.slidesharecdn.com/hdponwindows-141106195917-conversion-gate01/85/HDP-Windows-14-320.jpg)
































































