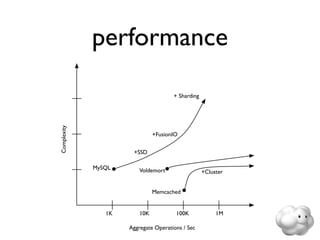
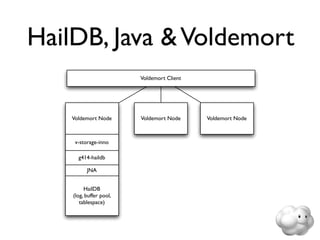
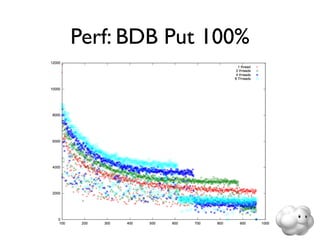
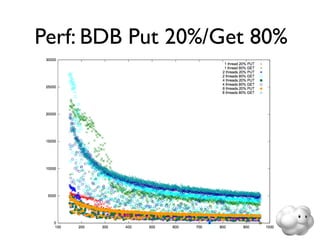
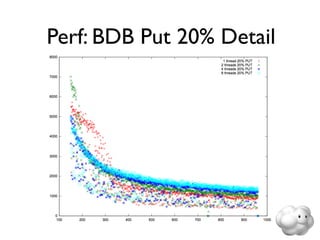
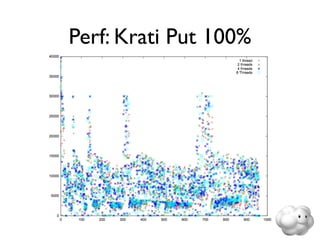
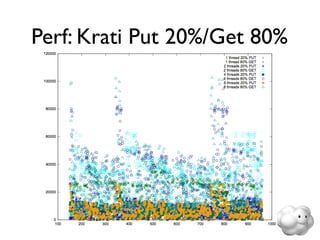
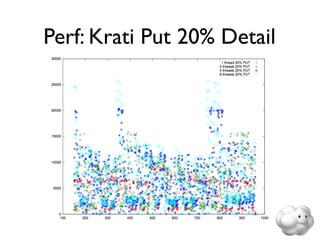
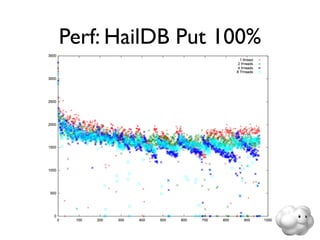
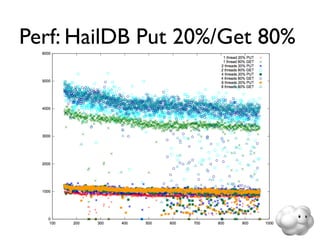
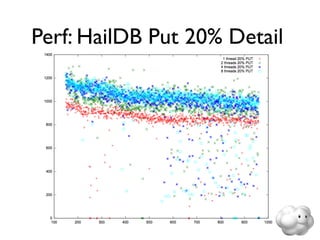
This document summarizes Sunny Gleason's presentation on accelerating the NoSQL key-value store Voldemort by running it on the HailDB storage engine. It describes how Voldemort and HailDB work, the experimental setup comparing the performance of Voldemort using BDB-JE, Krati and HailDB for storage, and the results showing that HailDB provided the best performance. It concludes with ideas for future work such as improving the HailDB integration and exploring online backups.








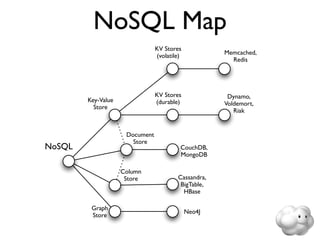
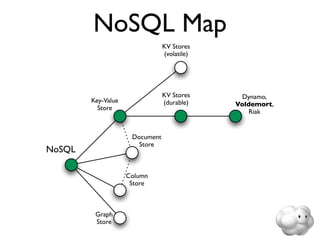


![key-value storage
• Essentially, a gigantic hash table
• Typically assign byte[] values to byte[] keys
• Plus versioning mixed in to handle failures
and conflicts
• Yes, you *can* do range partitioning; in
practice, avoid it because of hot spots](https://image.slidesharecdn.com/acceleratingnosql-110310093133-phpapp01/85/Accelerating-NoSQL-13-320.jpg)












































![JavaOne2016 - Microservices: Terabytes in Microseconds [CON4516]](https://cdn.slidesharecdn.com/ss_thumbnails/javaone2016microservicesfinal-160922163749-thumbnail.jpg?width=640&height=640&fit=bounds)















































