イメージ
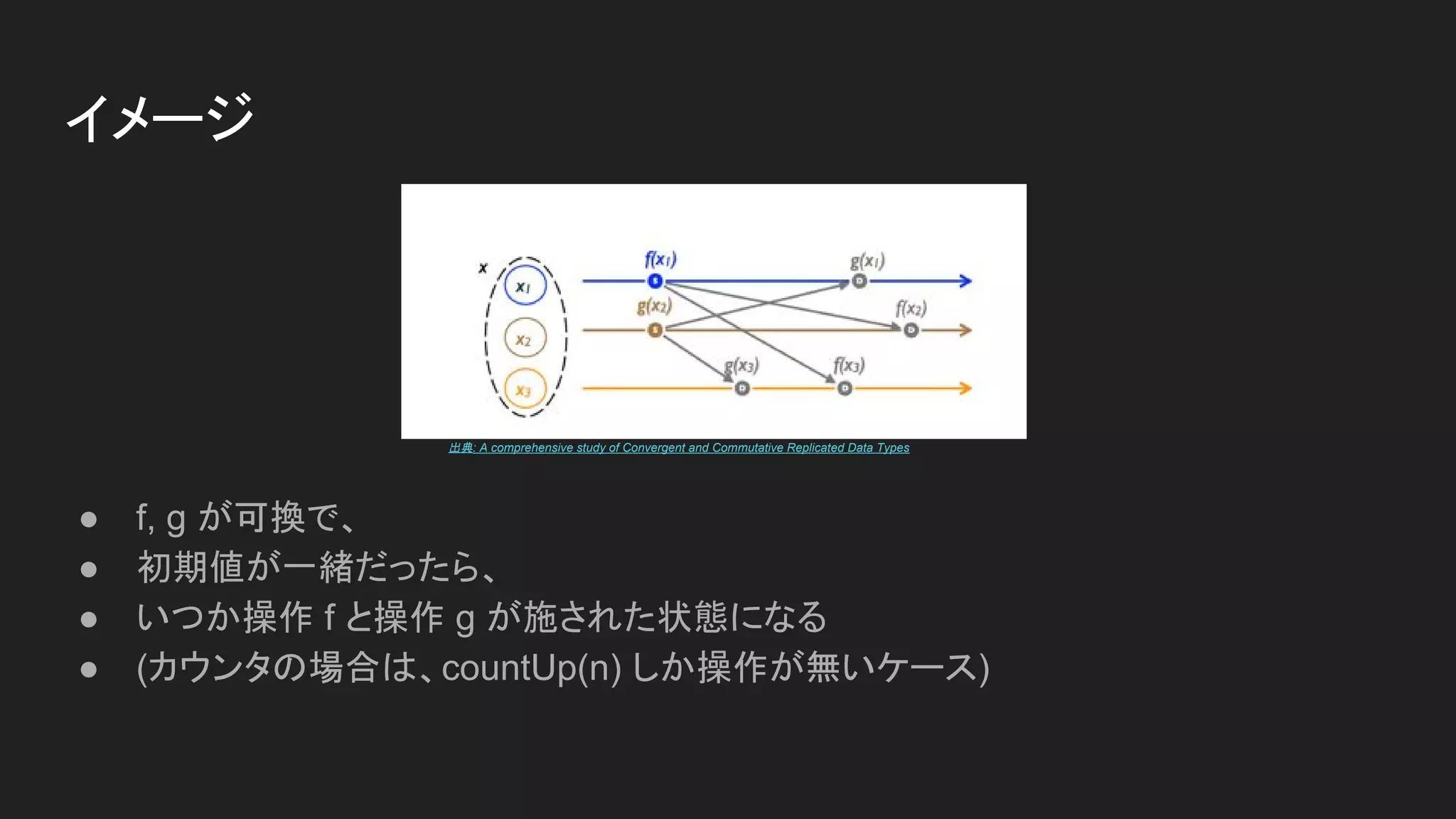
● f, gが可換で、
● 初期値が一緒だったら、
● いつか操作 f と操作 g が施された状態になる
● (カウンタの場合は、countUp(n) しか操作が無いケース)
出典: A comprehensive study of Convergent and Commutative Replicated Data Types
よく見るCRDTなデータ構造
● より複雑なデータ構造だとMap, Register,Graph なんかも作れたりする
○ 詳しくは A comprehensive study of Convergent and Commutative
Replicated Data Types を参照
○ データのマージ、変更操作がしっかり記述されています