Downloaded 184 times







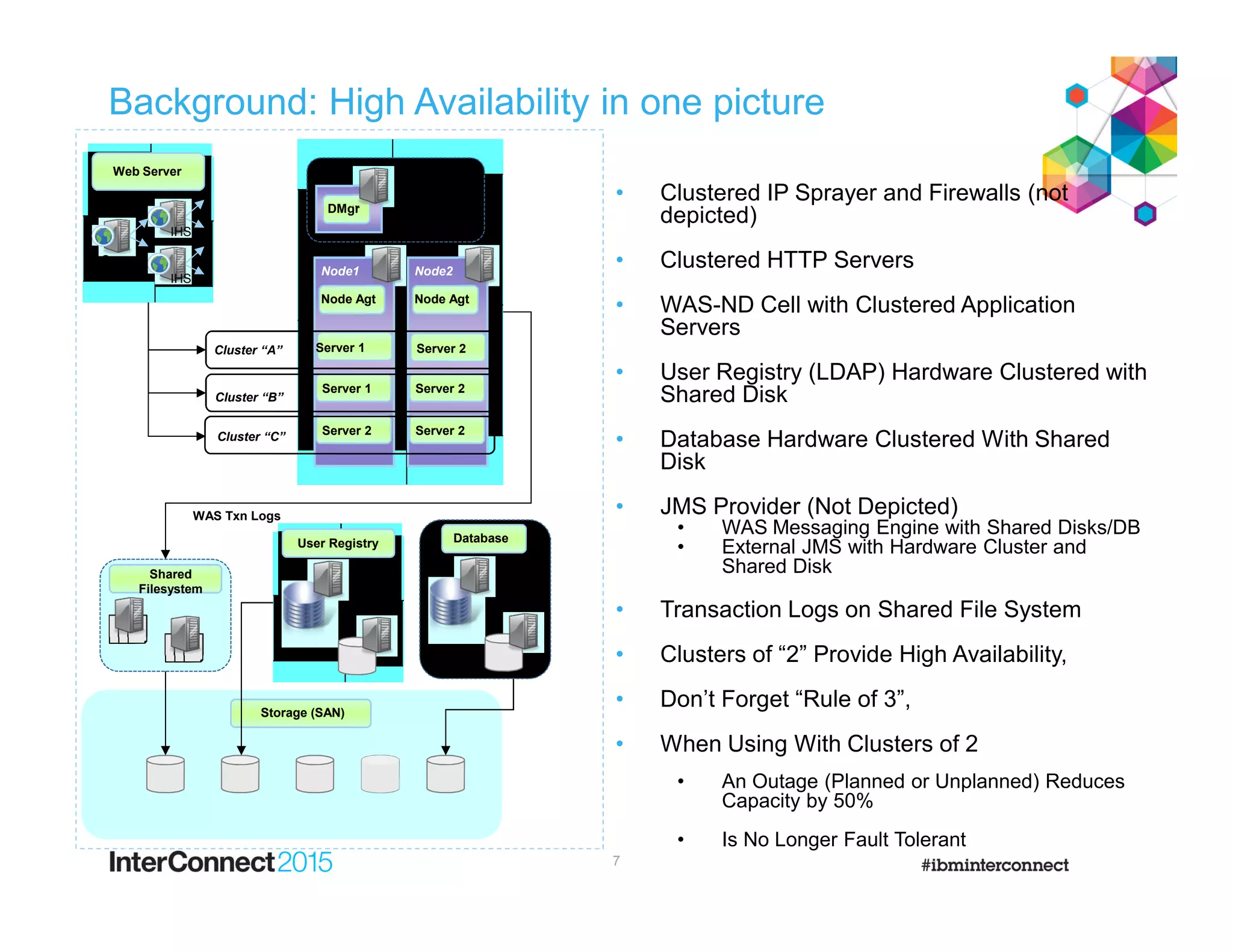





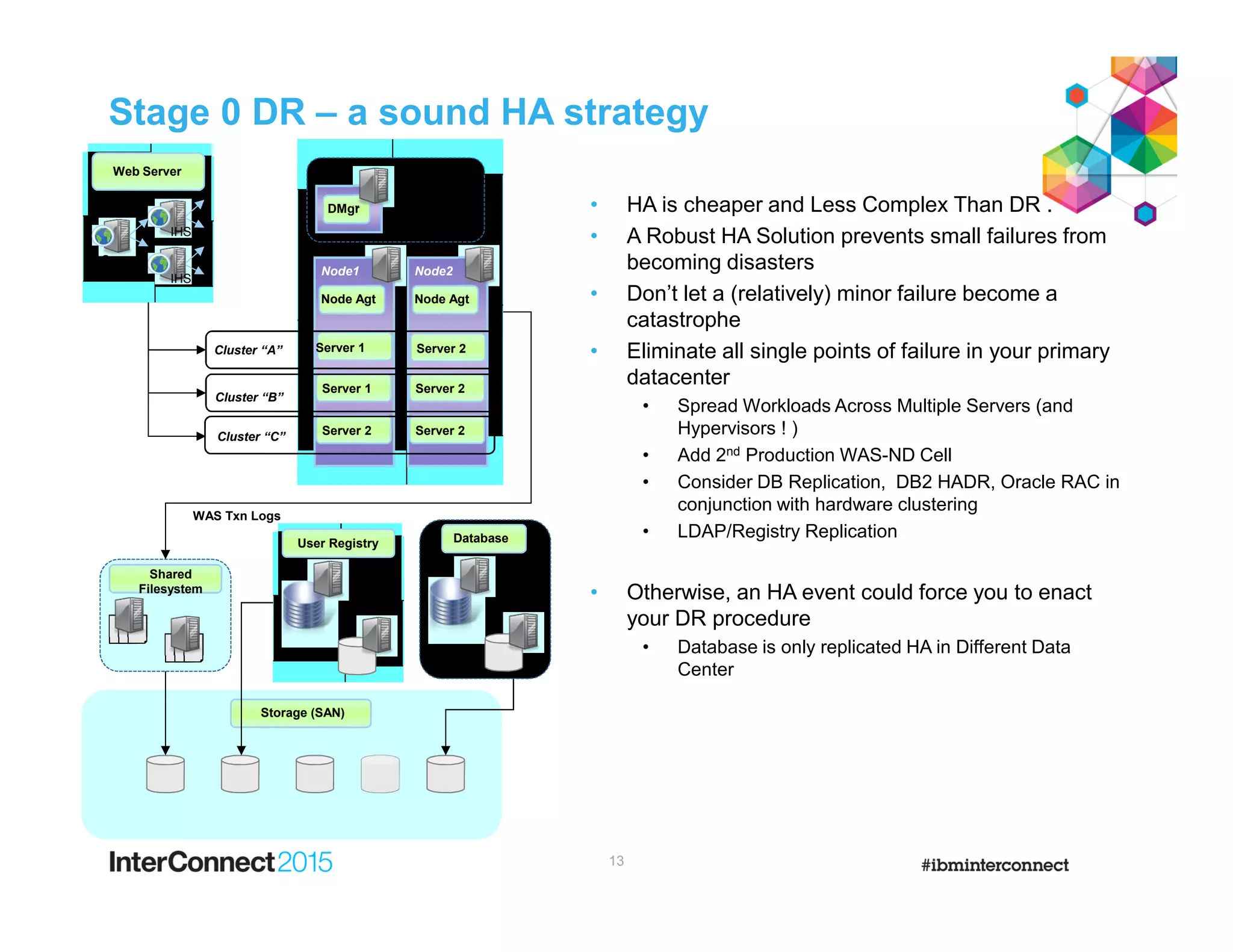















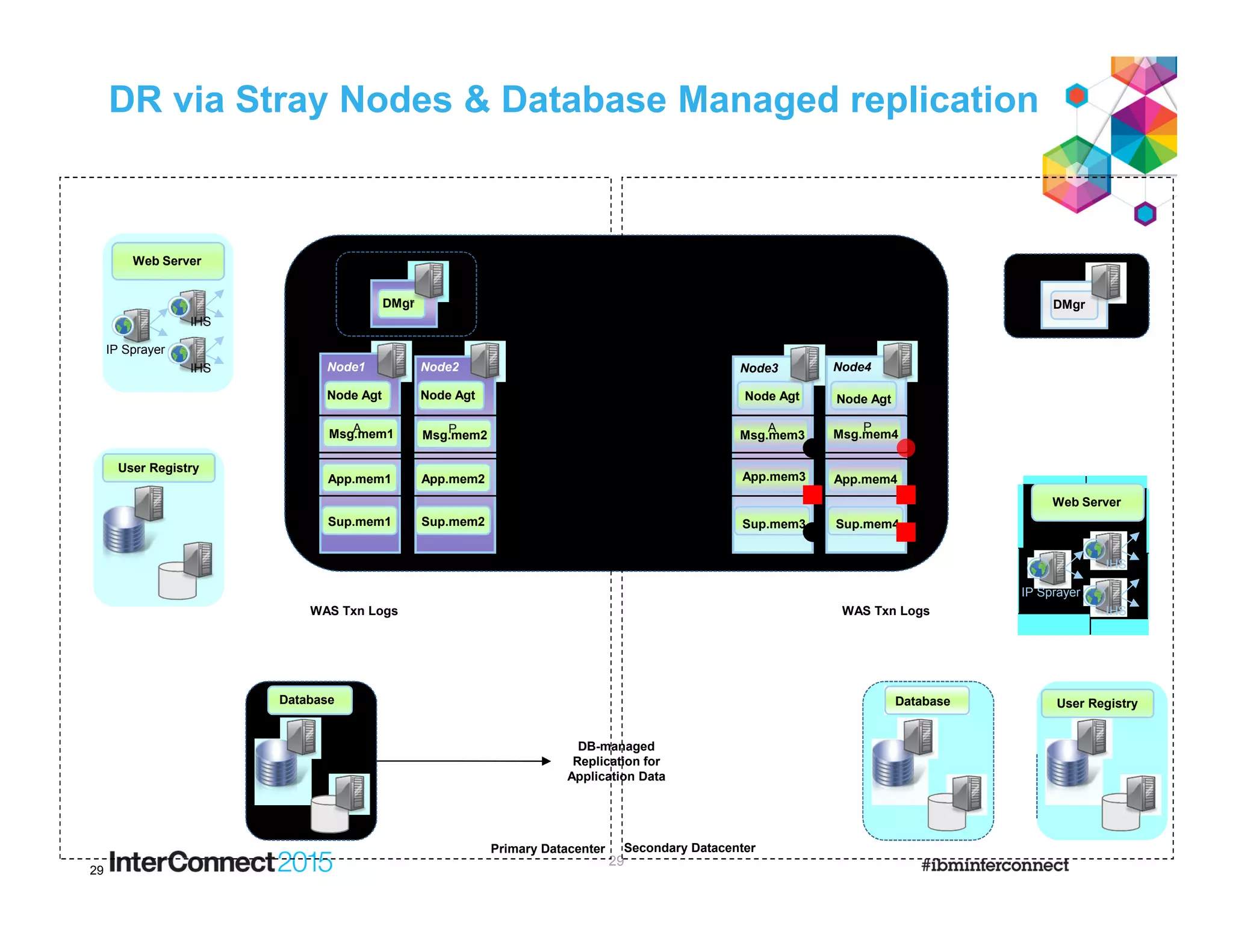

























This document discusses planning for disaster recovery of WebSphere Application Server and IBM Business Process Manager applications across multiple data centers. It covers various disaster recovery architecture options including active/passive and different active/active models. Key considerations for recovering WebSphere Application Server and IBM BPM applications are discussed such as using backup/restore of configuration files, transaction log replay, and message queue recovery. The importance of having independent cells aligned with data center boundaries is emphasized to avoid a single failure impacting both sites.






























































































