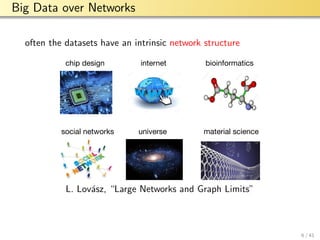
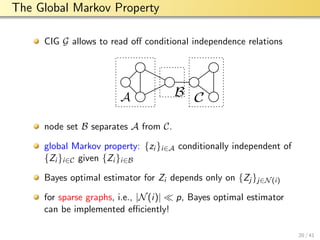
The document discusses graphical model selection for big data over networks, detailing the volume, velocity, and variety of data and how this challenges conventional data processing methods. It introduces probabilistic graphical models and efficient methods for graphical model selection through sparse neighborhood regression and convex optimization. Key issues include label sampling strategies, implementation of message passing algorithms for scalable processing, and future directions in directed graphical models and vector-valued data.






![aalto-logo-en-3
Graph Signals for Supervised Learning
consider supervised machine learning from dataset D
each datapoint zi has a label r[i] (e.g., persons preference for
buying certain product)
entire labelling is a graph signal r[·] : V → R
graph signal r[·] maps node i ∈ V to its label r[i]
graph signal processing (GSP) provides efficient tools for
handling large-scale graph signals
8 / 41](https://image.slidesharecdn.com/csgraphselbigdata2016v2-170827052850/85/Graphical-Model-Selection-for-Big-Data-8-320.jpg)
![aalto-logo-en-3
GSP generalizes DSP
discrete-time signals are graph signals over chain graph
· · ·· · ·
r[−1] r[0] r[1]
label r[i] might correspond to presence of “clipping” at time i
(greyscale) images are signals over grid graph
· · ·
···
r[i]
label r[i] might be presence of certain object at location i
GSP yields efficient learning by fast graph Fourier transforms
9 / 41](https://image.slidesharecdn.com/csgraphselbigdata2016v2-170827052850/85/Graphical-Model-Selection-for-Big-Data-9-320.jpg)
![aalto-logo-en-3
Fast Algorithms on Graphs
GSP theory yields fast algorithms for large-scale graphs
generalizes FFT from chain graph to general graphs
parallelization/vectorization possible for product graph
structure
6
graph product, denoted as G = G1 × G2,
is
= A1 ⊗ IN2 + IN1 ⊗A2. (25)
g product, denoted as G = G1 G2, the
⊗ A2 + A1 ⊗ IN2 + IN1 ⊗A2. (26)
can be seen as a combination of the Kro-
n products. Since the products (23), (25),
ve, Kronecker, Cartesian, and strong graph
ned for an arbitrary number of graphs.
rise in different applications, including
processing [32], computational sciences
], and computational biology [34]. Their
parts are used in network modeling and
], [37]. Multiple approaches have been
composition and approximation of graphs
[38], [30], [31], [39].
er a versatile graph model for the represen-
atasets in multi-level and multi-parameter
DSP, multi-dimensional signals, such as
video, reside on rectangular lattices that
ts of line graphs. Fig. 2(a) shows a two-
formed by the Cartesian product of two
ces.
of graph signals residing on product graphs
Digital image Row Column
(a)
Sensor network Time series
Measurements
atonetimestep
Measurements of one sensor
Sensor network measurements
(b)
Social network with communities
Community
structure
Intercommunity
communication
structure
(c)
10 / 41](https://image.slidesharecdn.com/csgraphselbigdata2016v2-170827052850/85/Graphical-Model-Selection-for-Big-Data-10-320.jpg)

![aalto-logo-en-3
Semi-Supervised Learning for Big Data over Networks
consider graph signal x[i] representing big dataset D
we only observe labels at sampling set S ⊆ V
aquiring labels can be costly
central hypothesis of supervised learning
close-by data points in high-density regions have similar labels
12 / 41](https://image.slidesharecdn.com/csgraphselbigdata2016v2-170827052850/85/Graphical-Model-Selection-for-Big-Data-12-320.jpg)





![aalto-logo-en-3
The Training Data
for each datapoint Zi , observe training samples
xi [1], . . . , xi [N]
stack samples into vector x[t] = (x1[t], . . . , xp[t])T
each vector sample x[t] multivariate normal ∼ N(0, C[t])
graphical model selection (GMS): learn G from x[t]
x1[1], . . . , x1[N]
x2[1], . . . , x2[N]
x3[1], . . . , x3[N]
21 / 41](https://image.slidesharecdn.com/csgraphselbigdata2016v2-170827052850/85/Graphical-Model-Selection-for-Big-Data-21-320.jpg)

![aalto-logo-en-3
Learning based on Sparse Regression
neighbourhood N(i) characterized by
N(i) = arg min
| supp(a)|≤smax
E{(zi −
j∈supp(a)
aj zj )2
}
not implementable since cannot evaluate expectation E
consider i.i.d. training x[t] ∼ N(0, C)
replace E with sample average
N(i) ≈ arg min
| supp(a)|≤smax
(1/N)
N
t=1
(xi [t] −
j∈supp(a)
aj xj [t])2
(1)
involves search over p
smax
subsets (more on this later!)
25 / 41](https://image.slidesharecdn.com/csgraphselbigdata2016v2-170827052850/85/Graphical-Model-Selection-for-Big-Data-25-320.jpg)
![aalto-logo-en-3
The Test Statistic of Sparse Regression
in what follows assume |N(i)| = smax
for index set I = {i1, . . . , ismax }, define statistic
Z(I) := arg min
| supp(a)|⊆I
(1/N)
N
t=1
(xi [t] −
j∈supp(a)
aj xj [t])2
= (1/N) P⊥
I xi
2
2
with the vector xi = (xi [1], . . . , xi [N])T
projection P⊥
I on orthogonal complement of span{xj }j∈I
P⊥
I := I − XI XT
I XI
−1
XT
I
26 / 41](https://image.slidesharecdn.com/csgraphselbigdata2016v2-170827052850/85/Graphical-Model-Selection-for-Big-Data-26-320.jpg)
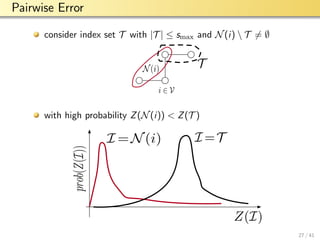
![aalto-logo-en-3
Pairwise Error
assume samples x[t] i.i.d. with ∼ N(0, C)
edges of CIG correspond to non-zero locations in K = C−1
define condition number κ := λmin(C)/λmax(C)
strength of edge (i, j) quantified by partial correlation
ρi,j := |Ki,j |/ Ki,i Kj,j
minimum partial correlation ρmin ≤ ρi,j
the probability of confusing T with N(i) is bounded as
Prob{Z(N(i)) ≥ Z(T )} ≤ 4 exp −(N−smax)
ρ2
minκ
64(ρ2
minκ + 8)
28 / 41](https://image.slidesharecdn.com/csgraphselbigdata2016v2-170827052850/85/Graphical-Model-Selection-for-Big-Data-28-320.jpg)


![aalto-logo-en-3
Non-IID Samples
samples x[f ]∼N(0, C[f ]) still independent but varying C[f ]
model useful for two particular process classes:
x[f ] are Fourier coeffs of stationary process y[t]:
x[f ] =
N
t=1
y[t] exp(−(2π/N)(t−1)(f −1))
x[f ] are LCB coeffs of locally stationary process y[t]:
x[f ] =
N
t=1
y[t]g(f )
[t]
32 / 41](https://image.slidesharecdn.com/csgraphselbigdata2016v2-170827052850/85/Graphical-Model-Selection-for-Big-Data-32-320.jpg)
![aalto-logo-en-3
Sample Complexity for Non-IID Samples
RECALL sample complexity for iid case:
N ∝
log(p−smax)
κρ2
min
replace ρmin with minimum average partial correlation
¯ρmin := min
(i,j)∈E
(1/N)
N
f =1
K2
i,j [f ]/(Ki,i [f ]Kj,j [f ])
with K[f ] := C−1[f ]
sample complex for non-iid case:
N ∝
log(p−smax)
κ¯ρ2
min
33 / 41](https://image.slidesharecdn.com/csgraphselbigdata2016v2-170827052850/85/Graphical-Model-Selection-for-Big-Data-33-320.jpg)
![aalto-logo-en-3
Average Partial Correlation
N
¯ρ2
min
f
K2
i,j [f]
Ki,i[f]Kj,j [f]
34 / 41](https://image.slidesharecdn.com/csgraphselbigdata2016v2-170827052850/85/Graphical-Model-Selection-for-Big-Data-34-320.jpg)





































![[NS][Lab_Seminar_240710]Improving Graph Networks through Selection-based Conv...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240710selgcn-240723105252-3f46ad9d-thumbnail.jpg?width=640&height=640&fit=bounds)


































