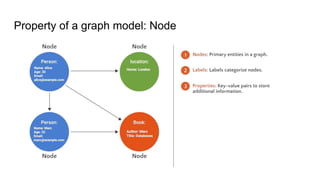
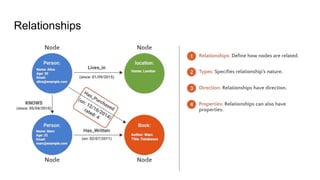
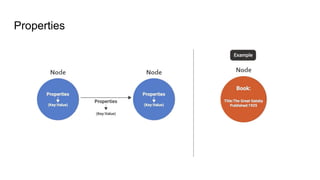
Introduction to graphdatabase
id name
1 Amina
2 Karim
3 Leila
4 Samir
5 Nadia
user_id friend_id
1 2
2 3
3 4
4 5
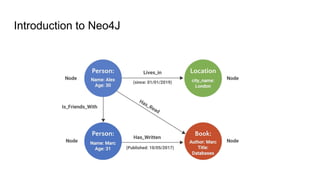
We want to find Amina’s
friends of friends ?
● Direct friend of Amina: Karim
● Friend of friend (2 hops): Leila
● 3 hops away: Samir
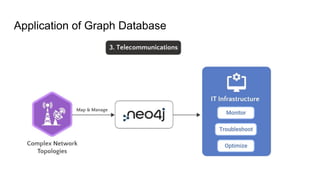
3.
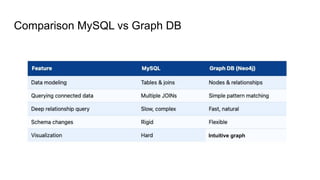
SQL Queries
SELECT u2.nameAS friend
FROM friends f
JOIN users u1 ON f.user_id = u1.id
JOIN users u2 ON f.friend_id = u2.id
WHERE u1.name = 'Amina';
SELECT DISTINCT u3.name AS friend_of_friend
FROM friends f1
JOIN friends f2 ON f1.friend_id = f2.user_id
JOIN users u1 ON f1.user_id = u1.id
JOIN users u3 ON f2.friend_id = u3.id
WHERE u1.name = 'Amina';
SELECT DISTINCT u4.name
FROM friends f1
JOIN friends f2 ON f1.friend_id = f2.user_id
JOIN friends f3 ON f2.friend_id = f3.user_id
JOIN users u1 ON f1.user_id = u1.id
JOIN users u4 ON f3.friend_id = u4.id
WHERE u1.name = 'Amina';
Find direct friends (1 hop): Find friends of friends (2 hops):
Friends of friends of friends (3 hops):
4.
Neo4 Queries
Find directfriends (1 hop):
Find friends of friends (2 hops):
friends of friends of friends (3 hops):
MATCH (a:Person {name:'Amina'})-[:FRIEND_WITH]->(f)
RETURN f.name;
MATCH (a:Person {name:'Amina'})-[:FRIEND_WITH*2]->(fof)
RETURN DISTINCT fof.name;
MATCH (a:Person {name:'Amina'})-[:FRIEND_WITH*1..3]->(other)
RETURN DISTINCT other.name;
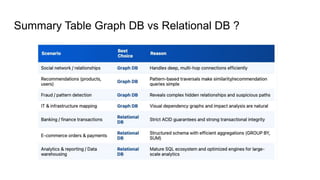
When Graph DatabasesAre Better?
Scenario A: Social Network Connections
● Goal: Find “friends of friends” or mutual friends.
● Data nature: Highly connected, many relationships per entity.
● Relational Problem: Requires multiple self-joins (slow as data grows).
● Graph Advantage: Simple pattern query, constant traversal time.
Use cases:
● Social networks (Facebook, LinkedIn)
● Professional networking platforms
● Influencer discovery
8.
When Graph DatabasesAre Better?
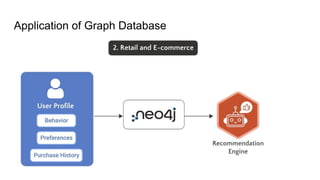
Scenario B: Recommendation Systems
● Goal: “People who like this product also liked…”
● Data nature: Complex relationships between users, products, categories.
● Relational Problem: Many-to-many joins between large tables.
● Graph Advantage: Relationships are direct, easy to traverse.
Use cases:
● Amazon, Netflix, Spotify recommendation engines
● Product or movie similarity detection
9.
When Graph DatabasesAre Better?
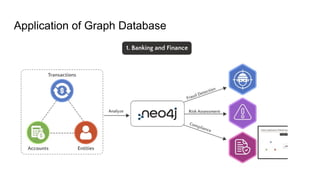
Scenario C: Fraud Detection / Pattern Recognition
● Goal: Detect suspicious account networks or hidden connections.
● Data nature: Many indirect relationships, often unknown in advance.
● Relational Problem: Hard to query unknown relationship depth (needs recursive SQL).
● Graph Advantage: Pattern matching easily reveals complex hidden paths.
Use cases:
● Banking & financial monitoring
● Cybersecurity
● Telecom fraud
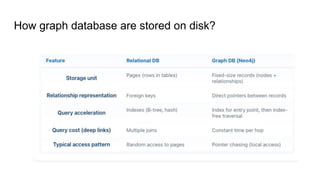
How does bigcompanies handle their database
architecture ? (Polyglot persistence)
● Use different types of databases for different types of data or workloads.
● Instead of one giant MySQL or Neo4j system, they combine relational, graph,
key-value, document, and search databases each one doing what it’s best at.
12.
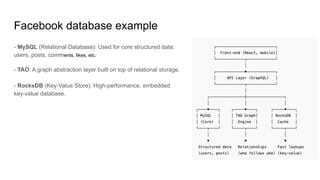
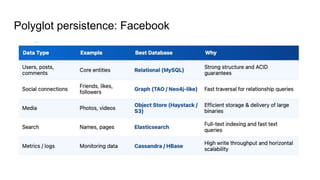
Facebook database example
-MySQL (Relational Database): Used for core structured data:
users, posts, comments, likes, etc.
- TAO: A graph abstraction layer built on top of relational storage.
- RocksDB (Key-Value Store): High-performance, embedded
key-value database.
13.
How They WorkTogether ?
When a user opens Facebook:
1. Frontend (React app) calls a GraphQL API.
2. The GraphQL server queries multiple backend databases:
○ MySQL (for posts, user data)
○ TAO (for relationships)
○ RocksDB (for cache)
○ Haystack (for media)
3. The API layer merges and formats the response.
4. The result is sent back to your screen in milliseconds.
This hybrid setup ensures:
● Speed for connected data (via graph layers)
● Consistency for core data (via relational DBs)
● Scalability for massive workloads
Introduction to CypherQuery Language
MATCH (m:Movie) RETURN m
MATCH (m:Movie) RETURN m.title, m.released
MATCH (m:Movie) WHERE m.released >2000 RETURN m.title, m.released
MATCH (m:Movie) RETURN count(m) AS NumberOfMovies
https://neo4j.com/docs/cypher-manual/current/introduction/




![Neo4 Queries
Find direct friends (1 hop):
Find friends of friends (2 hops):
friends of friends of friends (3 hops):
MATCH (a:Person {name:'Amina'})-[:FRIEND_WITH]->(f)
RETURN f.name;
MATCH (a:Person {name:'Amina'})-[:FRIEND_WITH*2]->(fof)
RETURN DISTINCT fof.name;
MATCH (a:Person {name:'Amina'})-[:FRIEND_WITH*1..3]->(other)
RETURN DISTINCT other.name;](https://image.slidesharecdn.com/graph-database10-251114155732-4f709ece/85/Graph-database_10-ppt-etty-rty-Graph-database_10-ppt-etty-rtyGraph-database_10-ppt-etty-rty-4-320.jpg)