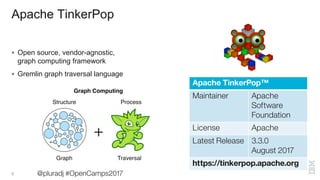
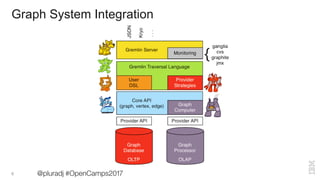
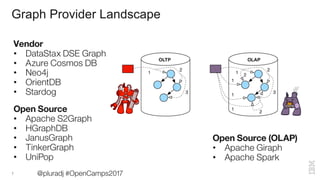
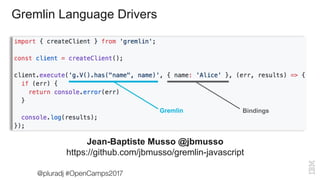
The document covers a presentation by Jason Plurad on graph computing using Apache TinkerPop, an open-source graph framework featuring the Gremlin graph traversal language. It discusses various graph databases, integrations, and provides examples of Gremlin queries and graph operations. The document also highlights contributions and resources for developers interested in graph technology.










![16
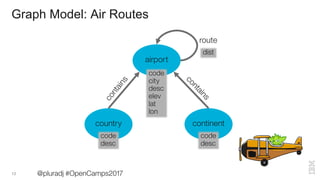
Where can I fly non-stop from Raleigh?
@pluradj #OpenCamps2017
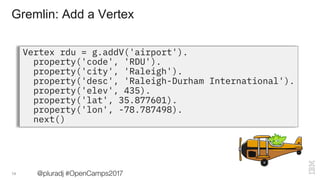
> g.V().has('airport', 'code', 'RDU').
out('route').
values('code').
fold().
toList()
==> [IAH, JFK, LAX, LGA, MCO, MIA, MSP, HOU,
CLE, DFW, FLL, IAD, MSY, YYZ, PHX, BDL, SEA,
CMH, SFO, TTN, TPA, SFB, SLC, PGD, LAS, PIE,
DEN, EWR, ATL, AUS, BNA, BOS, BWI, MDW, DCA,
ORD, STL, DAL, PHL, CDG, DTW, LHR, CLT, PIT,
MEM, CUN, IND, CVG]](https://image.slidesharecdn.com/graphcomputingwithapachetinkerpop-171120161021/85/Graph-Computing-with-Apache-TinkerPop-16-320.jpg)

![18
What is the shortest path to Melbourne?
@pluradj #OpenCamps2017
> g.V(rdu).
repeat( out('route').simplePath() ).
until( has('code', 'MEL') ).
limit(5).
path().by('code').
toList()
==> [RDU, LAX, MEL]
==> [RDU, IAH, NRT, MEL]
==> [RDU, IAH, DXB, MEL]
==> [RDU, IAH, AKL, MEL]
==> [RDU, IAH, PEK, MEL]](https://image.slidesharecdn.com/graphcomputingwithapachetinkerpop-171120161021/85/Graph-Computing-with-Apache-TinkerPop-18-320.jpg)













































![[Databeers] 27-11-2014 “Githubland”. Luis Osa](https://cdn.slidesharecdn.com/ss_thumbnails/slidesgithubland-150108030230-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)























