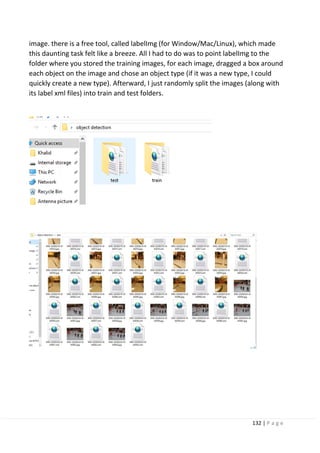
The history of self-driving cars began in the 1930s with conceptual designs and progressed through the 20th century with early prototypes. Significant milestones include RCA Labs building a guided miniature car in the 1950s, vision-guided robotic vans achieving highway speeds in the 1980s, and USDOT demonstrations of automated highway systems in the 1990s. Development continued through military efforts in the 2000s and 2010s with increasing capabilities and testing of commercial applications such as mining haulage systems.






![5 | P a g e
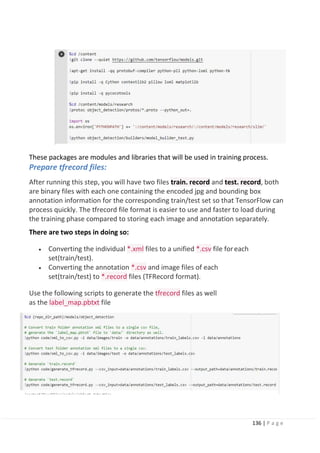
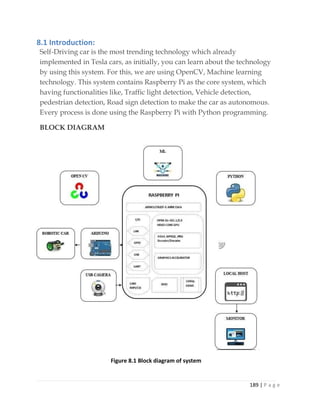
Chapter 4: Object Detection
4.1 Introduction.
4.2 General object detection framework.
4.3 Region proposals.
4.4 Steps of how the NMS algorithm works.
4.5 Precision-Recall Curve (PR Curve).
4.6 Conclusion.
4.7 Region-Based Convolutional Neural Networks (R-CNNs) [high mAP andlow
FPS].
4.8 Fast R-CNN
4.9 Faster R-CNN
4.10 Single Shot Detection (SSD) [Detection Algorithm Used In Our Project]
4.11 Base network.
4.12 Multi-scale feature layers.
4.13 (YOLO) [high speed but low mAP][5].
4.14 What Colab Offers You?
Chapter 5: Transfer Machine Learning
5.1 Introduction.
5.1.1 Definition and why transfer learning?
5.1.2 How transfer learning works.
5.1.3 Transfer learning approaches.
5.2 Detecting traffic signs and pedestrians.
5.2.1 Model selection (most bored).
5.3 Google’s edge TPU. What? How?
why?
Chapter 6: Lane Keeping System
6.1 introduction
6.2 timeline of available systems](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-6-320.jpg)








































![53 | P a g e
3.6 Problem setting in image recognition:
In conventional machine learning (here, it is defined as a method prior to the time
when deep learning gained attention), it is difficult to directly solve general object
recognition tasks from the input image. This problem can be solved by distinguishing
the tasks of image identification, image classification, object detection, scene
understanding, and specific object recognition. Definitions of each task
and approaches to each task are described below.
Image verification:
Image verification is a problem to check whether the object in the
image is the same as the reference pattern. In image verification, the
distance between the feature vector of the reference pattern and the
feature vector of the input image is calculated. If the distance value is less
than a certain value, the images are determined as identical, and if the
value is more, it is determined otherwise. Fingerprint, face, and person
identification relates to tasks in which it is required to determine
whether an actual person is another person. In deep learning, the problem
of person identification is solved by designing a loss function (triplet loss
function) that calculates the value of distance between two images of the
same person as small, and the value of distance with another person's
image as large [1].
Figure3-2 General Object Recognition.](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-54-320.jpg)
![54 | P a g e
Object detection:
Object detection is the problem of finding the location of an object of a certain
category in the image. Practical face detection and pedestrian detection are
included in this task. Face detection uses a combination of Haar-like features [2]
and AdaBoost, and pedestrian detection uses HOG features [3] and support vector
machine (SVM). In conventional machine learning, object detection is achieved by
training 2-class classifiers corresponding to a certain category and raster scanning
in the image. In deep learning-based object detection, multiclass object detection
targeting several categories can be achieved with one network.
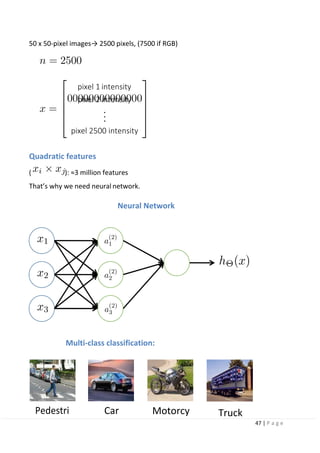
Image classification:
Image classification is a problem to find out the category to which an object in an
image belongs to, among predefined categories. In the conventional machine
learning, an approach called bag-of-features (BoF) has been used: a vector quantifies
the image local features and expresses the features of the whole image as a
histogram. Yet, deep learning is well-suited to the image classification task, and
became popular in 2015 by achieving an accuracy exceeding human recognition
performance in the 1000-class image classification task.
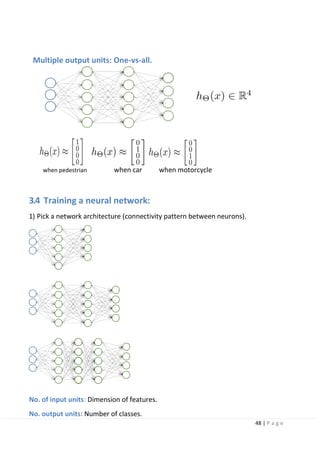
3.7 Convolutional Neural Network (CNN):
CNN computes the feature map corresponding to the kernel by convoluting the
kernel (weight filter) on the input image. Feature maps corresponding to the kernel
types can be computed as there are multiple kernels. Next, the size of the feature
map is reduced by the pooling feature map. As a result, it is possible to absorb
geometrical variations such as slight translation and rotation of the input image.
The convolution process and the pooling process are applied repeatedly to extract
the feature map. The extracted feature map is input to fully connected layers, and
the probability of each class is finally output. In this case, the input layer and the
output layer have a network structure that has units for the image and the number
of classes. Training of CNN is achieved by updating the parameters of the network by
the backpropagation method. The parameters in CNN refer to the kernel of the
convolutional layer and the weights of all coupled layers. The process flow of the
backpropagation method is shown:](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-55-320.jpg)
![55 | P a g e
First,training data is input to the network using the current parameters to obtain
the predictions (forward propagation). The error is calculated from the predictions
and the training label; the update amount of each parameter is obtained from the
error, and each parameter in the network is updated from the output layer toward
the input layer (back propagation). Training of CNN refers to repeating these
processes to acquire good parameters that can recognize the images correctly.
Scene understanding (semantic segmentation):
Scene understanding is the problem of understanding the scene structure in an
image. Above all, semantic segmentation that finds object categories in each pixel in
an image has been considered difficult to solve using conventional machine learning.
Therefore, it has been regarded as one of the ultimate problems of computer vision,
but it has been shown that it is a problem that can be solved by applying deep
learning.
Specific object recognition:
Specific object recognition is the problem of finding a specific object. By giving
attributes to objects with proper nouns, specific object recognition is defined as a
subtask of the general object recognition problem. Specific object recognition is
achieved by detecting feature points using SIFT from images, and a voting process
based on the calculation of distance from feature points of reference patterns.
Machine learning is not used here directly here, but the learned invariant feature
transform (LIFT) proposed in 2016 achieved an improvement in performance by
learning and replacing each process in SIFT through deep learning.
3.4 Deep learning-based image recognition:
Image recognition prior to deep learning is not always optimal because image
features are extracted and expressed using an algorithm designed based on the
knowledge of researchers, which is called a handcrafted feature. Convolutional
neural network (CNN) [7]), which is one type of deep learning, is an approach for
learning classification and feature extraction from training samples, as shown in This
chapter describes CNN, focuses on object detection and scene understanding
(semantic segmentation), and describes its application to image recognition and its
trends.](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-56-320.jpg)







![63 | P a g e
Figure3-10 Example of PSPNet-based Semantic Segmentation Results (cited
from Reference [11]).
3.7.4 CNN for ADAS application:
The machine learning technique is applicable to use for system intelligence
implementation in ADAS(Advanced Driving Assistance System). In ADAS, it is to
facilitate the driver with the latest surrounding information obtained by sonar,
radar, and cameras. Although ADAS typically utilizes radar and sonar for long-range
detection, CNN-based systems can recently play a significant role in pedestrian
detection, lane detection, and redundant object detection at moderate distances.
For autonomous driving, the core component can be categorized into three
categories, namely perception, planning, and control. Perception refers to the
understanding of the environment, such as where obstacles located, detection of
road signs/marking, and categorizing objects by their semantic labels such as
pedestrians, bikes, and vehicles.
Localization refers to the ability of the autonomous vehicle to determine its position
in the environment. Planning refers to the process of making decisions in order to
achieve the vehicle's goals, typically to bring the vehicle from a start location to a
goal location while avoiding obstacles and optimizing the trajectory. Finally, the
control refers to the vehicle's ability to execute the planned actions. CNN-based
object detection is suitable for the perception because it can handle the multi-class
objects. Also, semantic segmentation is useful information for making decisions in](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-64-320.jpg)

![65 | P a g e
in one's own vehicle for throttle control. In this manner, high-precision control of
steering and throttle can be achieved in various driving scenarios.
3.8.2 Visual explanation of end-to-end learning:
CNN-based end-to-end learning has a problem where the basis of output control
value is not known. To address this problem, research is being conducted on an
approach on the judgment grounds (such as turning steering wheel to the left or
right and stepping on brakes) that can be understood by humans.
The common approach to clarify the reason of the network decision-making is a
visual explanation. Visual explanation method outputs an attention map that
visualizes the region in which the network focused as a heat map. Based on the
obtained attention map, we can analyze and understand the reason of the decision-
making. To obtain more explainable and clearer attention map for efficient visual
explanation, a number of methods have been proposed in the computer vision field.
Class activation mapping (CAM) generates attention maps by weighting the feature
maps obtained from the last convolutional layer in a network. A gradient- weighted
class activation mapping (Grad-CAM) is another common method, which generates
an attention map by using gradient values calculated at backpropagation process.
This method is widely used for a general analysis of CNNs because it can be applied
to any networks. Fig. 10 shows example attention maps of CAM and Grad-CAM.
Figure3-11 attention maps of CAM and Grad-CAM. (cite from reference [22]).
Visual explanation methods have been developed for general image recognition
tasks while visual explanation for autonomous driving has been also proposed.
Visual backprop is developed for visualize the intermediate values in a CNN, which
accumulates feature maps for each convolutional layer to a single map.](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-66-320.jpg)

![67 | P a g e
Figure3-12 Regression-type Attention Branch Network. (cite from reference [17].
Figure3-13 Attention map-based visual explanation for self-driving.
3.8.3 Future challenges:
The visual explanations enable us to analyze and understand the internal state of
deep neural networks, which is efficient for engineers and researchers. One of the
future challenges is explanation for end users, i.e., passengers on a self-driving
vehicle. In case of fully autonomous driving, for instance, when lanes are suddenly
changed even when there are no vehicles ahead or on the side, the passenger in the
car may be concerned as to why the lanes were changed. In such cases, the
attention map visualization technology introduced in Section 4.2 enables people to
understand the reason for changing lanes. However, visualizing the attention map in
a fully automated vehicle does not make sense unless a person on the autonomous
vehicle always sees it. A person in an autonomous car, that is, a person whoreceives
the full benefit of AI, needs to be informed of the judgment grounds in the form of
text or voice stating, “Changing to left lane as a vehicle from the rear is approaching](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-68-320.jpg)



![71 | P a g e
Figure4-1 Classification and Object Detection.
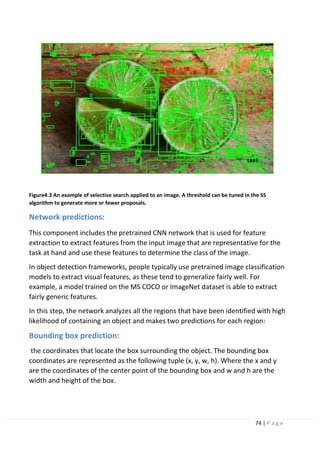
Object detection is widely used in many fields. For example, in self-driving
technology, we need to plan routes by identifying the locations of vehicles,
pedestrians, roads, and obstacles in the captured video image. Robots often
perform this type of task to detect targets of interest. Systems in the security field
need to detect abnormal targets, such as intruders or bombs.
Now that you understand what object detection is and what differentiates it from
image classification tasks, let’s take a look at the general framework of object
detection projects.
1. First, we will explore the general framework of the object detection algorithms.
2. Then, we will dive deep into three of the most popular detection algorithms:
a. R-CNN family of networks
b. SSD
c. YOLO family of networks [3]
4.2 General object detection framework:
Typically, there are four components of an object detection framework.](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-72-320.jpg)







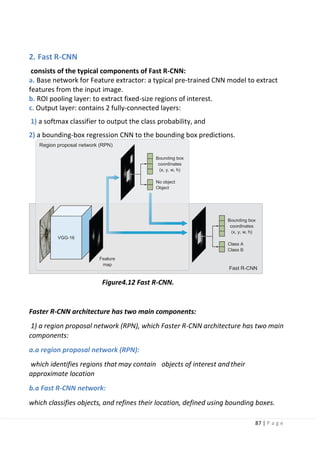
![80 | P a g e
Now, that we understand the general framework of object detection algorithms,
let’s dive deeper into three of the most popular detection algorithms.
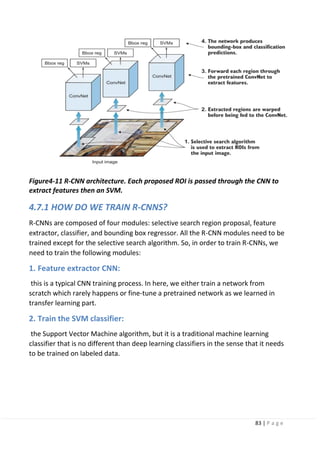
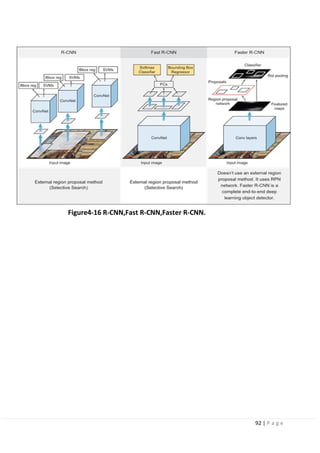
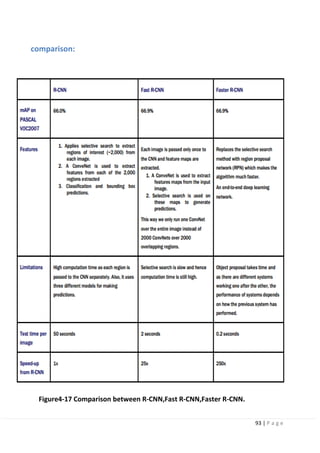
4.7 Region-Based Convolutional Neural Networks (R-CNNs) [high mAP
and low FPS]:
Developed by Ross Girshick et al. in 2014 in their paper “Rich feature hierarchies for
accurate object detection and semantic
segmentation”.
The R-CNN family has then expanded to include Fast-RCNN and Faster-RCNN that
came out in 2015 and 2016.
R-CNN:
The R-CNN is the least sophisticated region-based architecture in its family, but itis
the basis for understanding how multiple object recognition algorithms work for all
of them. It may have
been one of the first large and successful applications of convolutional neural
networks to the problem of object detection and localization that paved the way
for the other advanced detection algorithms.
Figure4-9 Regions with CNN features.](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-81-320.jpg)









![94 | P a g e
4.10 Single Shot Detection (SSD) [Detection Algorithm UsedIn
Our Project]:
The paper about SSD: Single Shot MultiBox Detector was released in November
2016 by C. Szegedy et al. Single Shot Detection network reached new records in
terms of performance and precision for object detection tasks, scoring over 74%
mAP (mean Average Precision) at 59 frames per second (FPS) on standard datasets
such as PascalVOC and MS COCO.
4.10.1 Very important note:
The most common metric that is used to measure the detection speed isthe
number of frames per second (FPS). For example,
Faster R-CNN operates at only 7 frames per second (FPS). There have been many
attempts to build faster detectors by attacking each stage of the detection pipeline
but so far, significantly increased speed comes only at the cost of significantly
decreased detection accuracy. In this section you will see why single-stage
networks like SSD can achieve faster detections that are more suitable for real-time
detections.
For benchmarking, SSD300 achieves 74.3% mAP at 59 FPS while SSD512 achieves
76.8% mAP at 22 FPS, which outperforms Faster R-CNN (73.2% mAP at 7 FPS).
SSD300 refers to the size of the input image of 300x300 and SSD512 refers to an
input image of size = 512x512.
4.10.2 SSD IS A SINGLE-STAGE DETECTOR:
The R-CNN family is a multi-stage detector. Where the network first predict the
objectness score of the bounding box then pass this box through a classifier to
predict the class probability.
In single-stage detectors like SSD and YOLO (explained later), the convolutional
layers make both predictions directly in one shot, hence the name Single Shot
Detector. Where the image is passed once through the network and the objectness
score for each bounding box is predicted using logistic regression to indicate the
level of overlap with the ground truth. If the bounding box overlaps 100% with the
ground truth, the objectness score is = 1 and if there is no overlap, the objectness
score = 0. We then set a threshold value (0.5) that says: “if the objectness score is
above 50%, then this bounding box likely has an object of interest and we get
predictions, if it is less than 50%, we ignore the prediction.”](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-95-320.jpg)
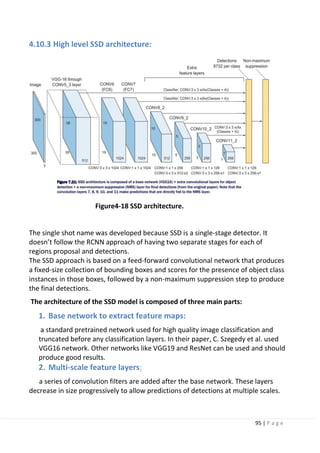




![100 | P a g e
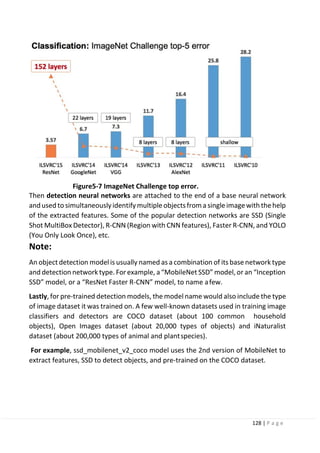
4.12.3 (YOLO) [high speed but low mAP]:
The YOLO family of models is a series of end-to-end deep learning models designed
for fast object detection, developed by joseph redmon, et al. And is considered one
of the first attempts to build a fast real-time object detector. It is one of the faster
object detection algorithms out there. Though it is no longer the most accurate
object detection algorithm, it is a very good choice when you need real-time
detection, without loss of too much accuracy.
The creators of YOLO took a different approach than the previous networks. YOLO
does not undergo the region proposal step like R-CNNs. Instead, it only predicts
over a limited number of bounding boxes by splitting the input into a grid of cells
and each cell directly predicts a bounding box and object classification. The result is
a large number of candidates bounding boxes that are consolidated into a final
prediction using non-maximum suppression.
4.13.1 Yolo versions:](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-101-320.jpg)

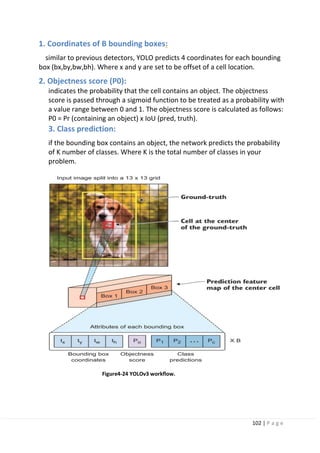








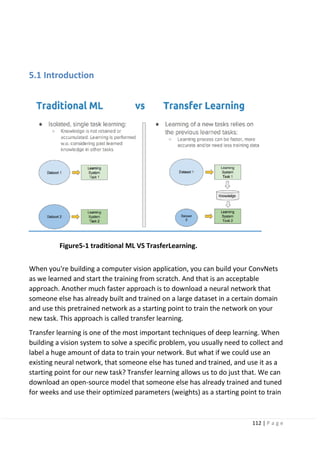















![133 | P a g e
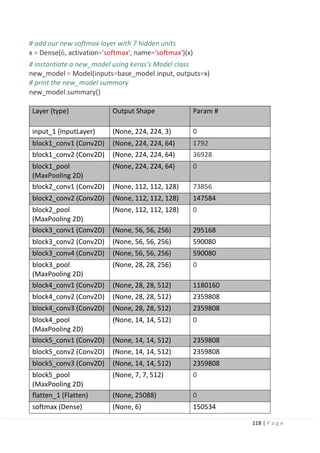
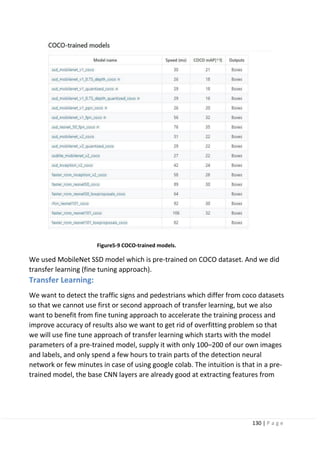
5.2.1 Model selection (most bored):
On a Raspberry Pi, since we have limited computing power, we have to choose a
model that both runs relatively fast and accurately. After experimenting with a few
models, we have settled on the MobileNet v2 SSD COCO model as the optimal
balance between speed and accuracy.
Note:
we tried faster_rcnn_inception_v2 _coco it was very accurate but very slow and we
also tried YOLO_V3 it was very fast but extremely low accuracy and its training
process is very complex.
Furthermore, for our model to work on the Edge TPU accelerator, we have to
choose the MobileNet v2 SSD COCO Quantized model.
Quantization is a way to make model inferences run faster by storing the model
parameters not as double values, but as integral values so decrease the required
memory and computational power, with very little degradation in prediction
accuracy[2]
. Edge TPU hardware is optimized and can only run quantized models.
Also if you run this quantized model on PC or laptop it will increase the speed which
is an important factor in real time object detection.](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-134-320.jpg)








































![185 | P a g e
The first frame will consist of the code 1111 0XXD2 where XX are the two MSB
bits of the 10-bit slave address and D is the R/W bit as described above. The
first frame ACK bit will be asserted by all slaves matching the first two bits of
the address. As with a normal 7-bit transfer, another transfer begins
immediately, and this transfer contains bits [7:0] of the address. At this point,
the addressed slave should respond with an ACK bit. If it doesn’t, the failure
mode is the same as a 7-bit system.
Note that 10-bit address devices can coexist with 7-bit address devices, since
the leading 11110 part of the address is not a part of any valid 7-bit
addresses.
Acknowledge (ACK) and Not Acknowledge (NACK):
The ACK takes place after every byte. The ACK bit allows the receiver to
signal the transmitter⁹ that the byte was successfully received and
another byte may be sent. The master generates all clock pulses over the
SCL line, including the ACK ninth clock pulse.
The ACK signal is defined as follows: the transmitter releases the SDA line
during the acknowledge clock pulse so that the receiver can pull the SDA
line LOW and it remains stable LOW during the HIGH period of this clock
pulse. When SDA remains HIGH during this ninth clock pulse, this is
defined as the Not Acknowledge (NACK) signal. The master can then
generate either a STOP condition to abort the transfer, or a RESTART
condition to start a new transfer. There are five conditions leading to the
generation of a NACK:
5.No receiver is present on the bus with the transmitted address so there
is no device to respond with an acknowledge.
6.The receiver is unable to receive or transmit because it is performing
some real-time function and is not ready to start communication with
the master.
7.During the transfer, the receiver gets data or commands that it does
not understand.
8.During the transfer, the receiver cannot receive any more data bytes.
9.A master-receiver must signal the end of the transfer to the
slave transmitter.](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-186-320.jpg)








![196 | P a g e
8.4.4 connecting raspberry-pi with SSH:
We should make sure that laptop is on the same network as the Raspberry Pi
(the network in the wpa_supplicant.conf file). Next, we want to get the IP
address of the Raspberry Pi on the network. By running arp -a we will see IP
addresses of other devices on the network. This will give a list of devices and
the corresponding IP and MAC addresses. We should see our Raspberry Pi listed
with its IP address.
Then Connecting to the Raspberry Pi by running ssh pi@ [the Pi's IP Address].
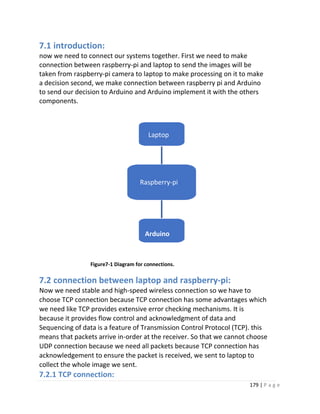
8.5 connection between Arduino and Raspberry-pi:
There are only limited number of GPIO pins available on the Raspberry Pi, so
it would be great to expand the input and output pins by linking Raspberry
Pi with Arduino. In this section we will discuss how we can connect the Pi
with single or multiple Arduino boards. You have three options to connect
them I2C.
8.5.1 Setup:
Figure 8.8 Hardware schematics](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-197-320.jpg)


![199 | P a g e
International Conference on Advances in Computing and Communication
Engineering (22-23 June 2018), 10.1109/ICACCE.2018.8441758 Google Scholar
12- J. Levinson, J. Askeland, J. Becker, J. Dolson, D. Held, S. Kammel, J.Z. Kolter, D.
Langer, O. Pink, V.R. Pratt, M. Sokolsky, G. Stanek, D.M. Stav ens, A. Teichman, M.
Werling, S. ThrunTowards fully autonomous driving: systems and algorithms
Intelligent Vehicles Symposium (2011), pp. 163-168 CrossRefView Record in
ScopusGoogle Scholar
Chapter 4:
1. https://www.dlology.com/blog/how-to-train-an-object-detection-
model-easy-for-free/
2. https://arxiv.org/abs/1806.08342
3. https://machinelearningmastery.com/object-recognition-with-deep-
learning/
4. https://arxiv.org/abs/1512.02325
5. https://arxiv.org/abs/1506.02640
6. https://medium.com/@prvnk10/object-detection-rcnn-
4d9d7ad55067,https://arxiv.org/pdf/1807.05511.pdf
7. https://arxiv.org/abs/1504.08083
8. https://arxiv.org/abs/1506.01497
Chapter 5:
1. Deep Learning for Vision Systems by Mohamed Elgendy
2. https://manalelaidouni.github.io/manalelaidouni.github.io/Evaluatin g-Object-Detection-
Models-Guide-to-Performance-Metrics.html
3. Deep Learning for Vision Systems by Mohamed Elgendy
Chapter 6:
[1] David tian “Deep pi car” [online] available.
https://towardsdatascience.com/deeppicar-part-1- 102e03c83f2c
[2] Mr. Tony Fan, Dr. Gene Yeau-Jian Liao, Prof. Chih-Ping Yeh, Dr. Chung-Tse Michael
Wu, Dr. Jimmy Ching- MingChen “Lane Keeping system by visual technology
“[online] available. https://peer.asee.org/lane-keeping- system- by-visual-
technology.pdf
[3] Prof. Albertengo Guido “Adaptive Lane Keeping Assistance System design based on
driver’sbehavio”. [online] available.
https://webthesis.biblio.polito.it/11978/1/tesi.pdf
[4] David tian ‘’End-to-End Lane Navigation Model via Nvidia Model’’ online
[available].
https://colab.research.google.com/drive/14WzCLYqwjiwuiwap6aXf9imhyctjRMQp](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-200-320.jpg)
![200 | P a g e
Chapter 7:
[1] Carmine Noviello, Mastering STM32A step-by-step guide to themost complete
ARM Cortex-M platform, using a free and powerful development
environment based on Eclipse and GCC.
[2] TCP Connection Establish and Terminate” [online] available.
https://www.vskills.in/certification/tutorial/information-technology/basic- network-
support-professional/tcp-connection-establish-and-terminate/
[3] anonymous007, ashushrma378, abhishek_paul ” Differences between TCP and
UDP” [online] available. https://www.geeksforgeeks.org/differences-between-tcp-
and-udp/](https://image.slidesharecdn.com/selfdrivingcarv2-200607145852/85/Graduation-project-Book-Self-Driving-Car-201-320.jpg)
































































