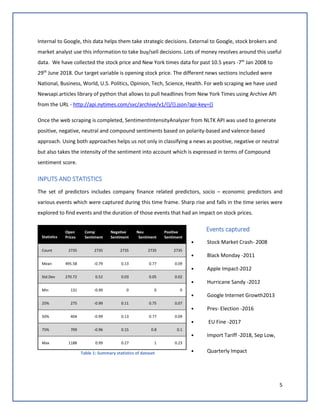
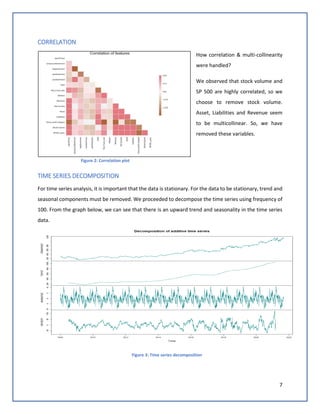
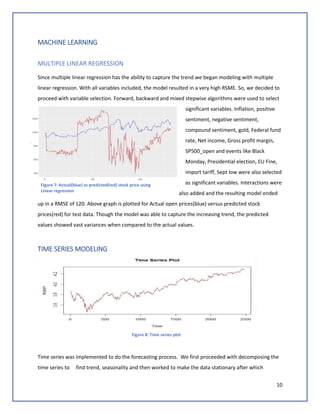
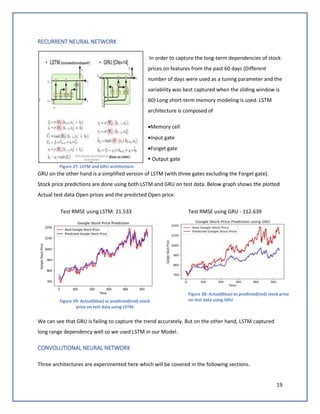
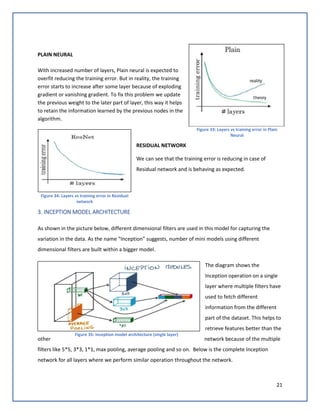
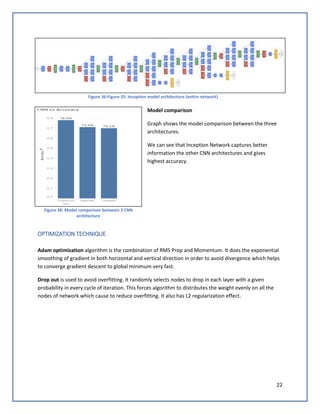
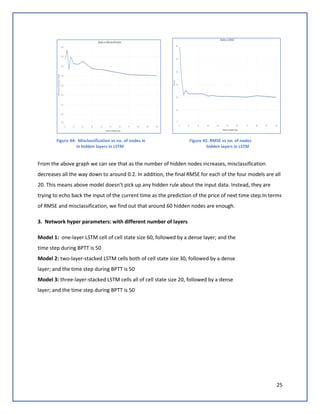
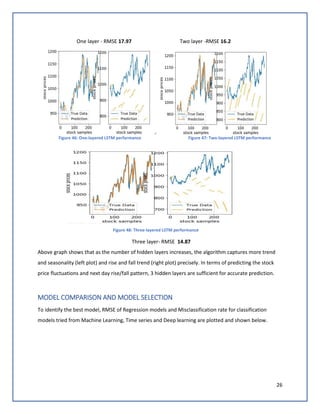
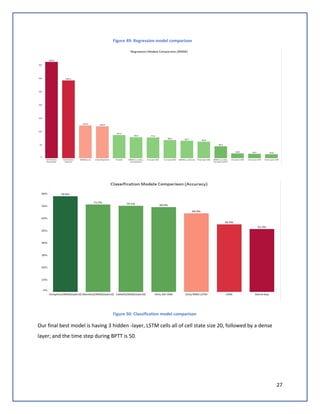
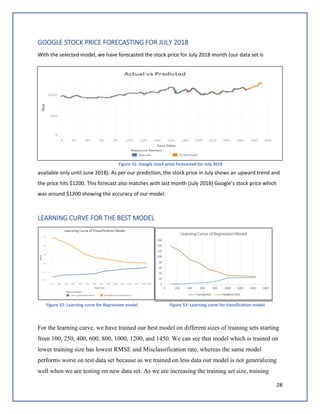
The document discusses predicting Google stock prices using machine learning algorithms. It explores using news sentiment data and historical stock prices to build regression and time series forecasting models. Multiple linear regression, ARIMA, and Holt-Winters exponential smoothing models were tested on the data, with ARIMA producing the best results with an RMSE of 123.73 on test data. The aim is to improve predictive accuracy of Google stock movements.







![14
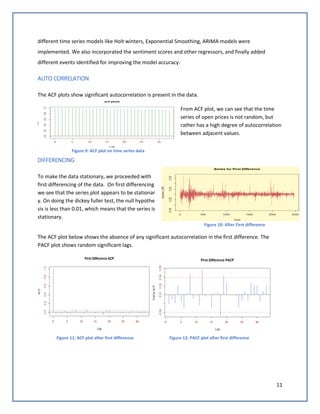
differencing. Hence, we applied an auto ARIMA with seasonal difference of 1, and the best model that
came was ARIMA(1,1,1)(0,1,0). The auto ARIMA function returns the best ARIMA model according to
either AIC, AICC or BIC value. The function conducts a search over all possible models within the order
constraints provided. The RMSE on the test set is 65.755. Best time series model that resulted in lowest
RMSE is ARIMA(1,1,1)(0,1,0).
sigma^2 estimated as 0.0001042: log likelihood=6674.37
AIC=-13342.75 AICc=-13342.74 BIC=-13325.79
RMSE: 65.75556
Table 4: Model Results for ARIMA(1,1,1)(0,1,0)[365]
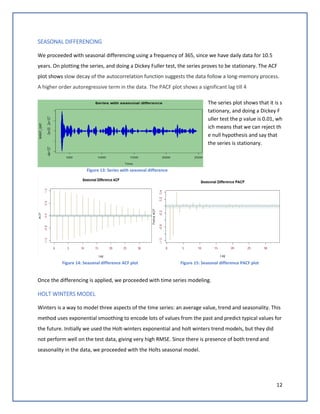
The plot shows th
e difference betw
een actual and pre
dicted open prices
for test dataset.
ARIMA WITH REGRESSORS
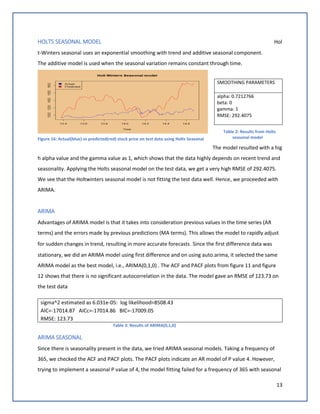
We then added all regressors (Compound Sentiment, Negative Sentiment, Neutral Sentiment, Positive
Sentiment, Gold, Federal Fund rate, Inflation, Net Income, Gross profit margin, Stock Volume,
SP500_open) on the best model ARIMA (1,1,1)(0,1,0).We observed that the RMSE is increasing to 78.98.
This shows that all the regressors might not be significant for the model.
Proceeded to remove insignificant
regressors, and tried adding certain
events, we found that the model RMSE
decreased to 62.7. This shows that
events greatly influence the stock
prediction.
Figure 17: Actual(blue) vs predicted(red) stock price on test data using ARIMA (1,1,1)(0,1,0)
Figure 18: ARIMA with regressors](https://image.slidesharecdn.com/teamdatasquadprojectreportgooglestockpriceforecasting-180827042547/85/Google-Stock-Price-Forecasting-14-320.jpg)










![34
APPENDIX 3 – TABLES
Table 1: Summary statistics of dataset.........................................................................................................5
Table 2: Results from Holts.........................................................................................................................13
Table 3: Results of ARIMA(0,1,0) ................................................................................................................13
Table 4: Model Results for ARIMA(1,1,1)(0,1,0)[365].................................................................................14](https://image.slidesharecdn.com/teamdatasquadprojectreportgooglestockpriceforecasting-180827042547/85/Google-Stock-Price-Forecasting-34-320.jpg)
















































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Harshvardhan Jain - From Pre-Trained to Purpose-Built: Fine-T...](https://cdn.slidesharecdn.com/ss_thumbnails/zru4zmiseku5tgvu2dgw-harshvardhan-jain-from-pre-trained-to-purpose-built-fine-tuning-llms-for-high-i-260119101520-8335585f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Egor Krasheninnikov - The Control Stack: Building Guardrails ...](https://cdn.slidesharecdn.com/ss_thumbnails/3lzcz7hxqmo51mtalv4u-the-control-stack-260119101520-ea90841a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)




