Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Google Cloud Platform - Japan
PDF, PPTX
14,812 views
Google Cloud Dataflow を理解する - #bq_sushi
4 月 24 日、#bq_sushi での Slava Chernyak によるプレゼンテーションです。
Technology
◦
Read more
41
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 47
2
/ 47
3
/ 47
4
/ 47
5
/ 47
6
/ 47
7
/ 47
8
/ 47
9
/ 47
10
/ 47
11
/ 47
12
/ 47
13
/ 47
14
/ 47
15
/ 47
16
/ 47
17
/ 47
18
/ 47
19
/ 47
20
/ 47
21
/ 47
22
/ 47
23
/ 47
24
/ 47
25
/ 47
26
/ 47
27
/ 47
28
/ 47
29
/ 47
30
/ 47
31
/ 47
32
/ 47
33
/ 47
34
/ 47
35
/ 47
36
/ 47
37
/ 47
38
/ 47
39
/ 47
40
/ 47
41
/ 47
42
/ 47
43
/ 47
44
/ 47
45
/ 47
46
/ 47
47
/ 47
More Related Content
PDF
分散トレーシング技術について(Open tracingやjaeger)
by
NTT Communications Technology Development
PPTX
Dockerからcontainerdへの移行
by
Akihiro Suda
PDF
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
PDF
[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送
by
Google Cloud Platform - Japan
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
PDF
イミュータブルデータモデル(入門編)
by
Yoshitaka Kawashima
PDF
Dockerからcontainerdへの移行
by
Kohei Tokunaga
PPTX
MongoDBが遅いときの切り分け方法
by
Tetsutaro Watanabe
分散トレーシング技術について(Open tracingやjaeger)
by
NTT Communications Technology Development
Dockerからcontainerdへの移行
by
Akihiro Suda
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送
by
Google Cloud Platform - Japan
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
イミュータブルデータモデル(入門編)
by
Yoshitaka Kawashima
Dockerからcontainerdへの移行
by
Kohei Tokunaga
MongoDBが遅いときの切り分け方法
by
Tetsutaro Watanabe
What's hot
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PDF
Python 3.9からの新定番zoneinfoを使いこなそう
by
Ryuji Tsutsui
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PDF
それはYAGNIか? それとも思考停止か?
by
Yoshitaka Kawashima
PDF
DDDのモデリングとは何なのか、 そしてどうコードに落とすのか
by
Koichiro Matsuoka
PDF
The Twelve-Factor Appで考えるAWSのサービス開発
by
Amazon Web Services Japan
PDF
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
PPTX
監査要件を有するシステムに対する PostgreSQL 導入の課題と可能性
by
Ohyama Masanori
PDF
PlaySQLAlchemy: SQLAlchemy入門
by
泰 増田
PDF
20210216 AWS Black Belt Online Seminar AWS Database Migration Service
by
Amazon Web Services Japan
PDF
ドメイン駆動設計 本格入門
by
増田 亨
PDF
Javaはどのように動くのか~スライドでわかるJVMの仕組み
by
Chihiro Ito
PDF
Hadoopの概念と基本的知識
by
Ken SASAKI
PPTX
Redisの特徴と活用方法について
by
Yuji Otani
PDF
JVMのGCアルゴリズムとチューニング
by
佑哉 廣岡
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PPTX
急速に進化を続けるCNIプラグイン Antrea
by
Motonori Shindo
PDF
AWSでDockerを扱うためのベストプラクティス
by
Amazon Web Services Japan
PDF
ゲームアーキテクチャパターン (Aurora Serverless / DynamoDB)
by
Amazon Web Services Japan
PPTX
Azure API Management 俺的マニュアル
by
貴志 上坂
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
Python 3.9からの新定番zoneinfoを使いこなそう
by
Ryuji Tsutsui
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
それはYAGNIか? それとも思考停止か?
by
Yoshitaka Kawashima
DDDのモデリングとは何なのか、 そしてどうコードに落とすのか
by
Koichiro Matsuoka
The Twelve-Factor Appで考えるAWSのサービス開発
by
Amazon Web Services Japan
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
監査要件を有するシステムに対する PostgreSQL 導入の課題と可能性
by
Ohyama Masanori
PlaySQLAlchemy: SQLAlchemy入門
by
泰 増田
20210216 AWS Black Belt Online Seminar AWS Database Migration Service
by
Amazon Web Services Japan
ドメイン駆動設計 本格入門
by
増田 亨
Javaはどのように動くのか~スライドでわかるJVMの仕組み
by
Chihiro Ito
Hadoopの概念と基本的知識
by
Ken SASAKI
Redisの特徴と活用方法について
by
Yuji Otani
JVMのGCアルゴリズムとチューニング
by
佑哉 廣岡
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
急速に進化を続けるCNIプラグイン Antrea
by
Motonori Shindo
AWSでDockerを扱うためのベストプラクティス
by
Amazon Web Services Japan
ゲームアーキテクチャパターン (Aurora Serverless / DynamoDB)
by
Amazon Web Services Japan
Azure API Management 俺的マニュアル
by
貴志 上坂
Similar to Google Cloud Dataflow を理解する - #bq_sushi
PDF
CEDEC 2015: Google スケールで実現する!ゲーム&分析基盤
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] GCP 上でストリーミングデータ処理基盤を構築してみよう! 2018年9月13日 放送
by
Google Cloud Platform - Japan
PDF
Google Cloud Platform 概要
by
Kiyoshi Fukuda
PDF
No-Ops で大量データ処理基盤
by
Google Cloud Platform - Japan
PDF
No-Ops で大量データ処理基盤を簡単に実現する
by
Kiyoshi Fukuda
PDF
Apache Airflow で作る GCP のデータパイプライン @ 酔いどれGCPUG 2017/11/28
by
Yuta Hono
PDF
Google Compute EngineとGAE Pipeline API
by
maruyama097
PDF
Google Compute EngineとPipe API
by
maruyama097
PDF
Google for Mobile: Google スケールで構築する! ゲームインフラと分析環境 - 橋口 剛
by
Google Cloud Platform - Japan
PDF
Dataflow(python)を触った所感
by
Ryo Yamaoka
PPTX
2024年5月25日Serverless Meetup大阪 アプリケーションをどこで動かすべきなのか.pptx
by
ssuserbefd24
PDF
甘酸っぱいGCPレガシーApp Engine python2からCloud Runへの移行の勘所
by
Ryusuke Kimura
PDF
APIMeetup 20170329_ichimura
by
Tomohiro Ichimura
PPTX
データ集計基盤のいままでとこれから 〜Hadoopからdataflowまで使い込んだ経験を徹底共有〜
by
Kazuhiro Mitsuhashi
PDF
GCP でも Serverless!!
by
Igarashi Toru
PDF
Google Cloud でアプリケーションを動かす.pdf
by
Google Cloud Platform - Japan
PDF
Google Cloud Platform は何がすごいのか?
by
Kiyoshi Fukuda
PDF
[CEDEC 2018] グローバル スケール コネクテッドゲームを GCP で作ろう!
by
Samir Hammoudi
PPT
Googleの基盤クローン Hadoopについて
by
Kazuki Ohta
PDF
Developer summit 2015 gcp
by
Google Cloud Platform - Japan
CEDEC 2015: Google スケールで実現する!ゲーム&分析基盤
by
Google Cloud Platform - Japan
[Cloud OnAir] GCP 上でストリーミングデータ処理基盤を構築してみよう! 2018年9月13日 放送
by
Google Cloud Platform - Japan
Google Cloud Platform 概要
by
Kiyoshi Fukuda
No-Ops で大量データ処理基盤
by
Google Cloud Platform - Japan
No-Ops で大量データ処理基盤を簡単に実現する
by
Kiyoshi Fukuda
Apache Airflow で作る GCP のデータパイプライン @ 酔いどれGCPUG 2017/11/28
by
Yuta Hono
Google Compute EngineとGAE Pipeline API
by
maruyama097
Google Compute EngineとPipe API
by
maruyama097
Google for Mobile: Google スケールで構築する! ゲームインフラと分析環境 - 橋口 剛
by
Google Cloud Platform - Japan
Dataflow(python)を触った所感
by
Ryo Yamaoka
2024年5月25日Serverless Meetup大阪 アプリケーションをどこで動かすべきなのか.pptx
by
ssuserbefd24
甘酸っぱいGCPレガシーApp Engine python2からCloud Runへの移行の勘所
by
Ryusuke Kimura
APIMeetup 20170329_ichimura
by
Tomohiro Ichimura
データ集計基盤のいままでとこれから 〜Hadoopからdataflowまで使い込んだ経験を徹底共有〜
by
Kazuhiro Mitsuhashi
GCP でも Serverless!!
by
Igarashi Toru
Google Cloud でアプリケーションを動かす.pdf
by
Google Cloud Platform - Japan
Google Cloud Platform は何がすごいのか?
by
Kiyoshi Fukuda
[CEDEC 2018] グローバル スケール コネクテッドゲームを GCP で作ろう!
by
Samir Hammoudi
Googleの基盤クローン Hadoopについて
by
Kazuki Ohta
Developer summit 2015 gcp
by
Google Cloud Platform - Japan
More from Google Cloud Platform - Japan
PDF
ServerlessDays Tokyo 2022 Virtual.pdf
by
Google Cloud Platform - Japan
PDF
20221105_GCPUG 女子会 Kubernets 編.pdf
by
Google Cloud Platform - Japan
PDF
[External] 2021.12.15 コンテナ移行の前に知っておきたいこと @ gcpug 湘南
by
Google Cloud Platform - Japan
PDF
What’s new in cloud run 2021 後期
by
Google Cloud Platform - Japan
PDF
【Dialogflow cx】はじめてみよう google cloud dialogflow cx 編
by
Google Cloud Platform - Japan
PDF
Google Cloud で実践する SRE
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] 事例紹介 : 株式会社マーケティングアプリケーションズ 〜クラウドへのマイグレーションとその後〜 2020年12月17日 放送
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] 【実演】Google Cloud VMware Engine と VMware ソリューションを組み合わせたハイブリッド環境の...
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] Google Workspace でできる データ分析と業務自動化のご紹介 2020年12月3日 放送
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] Google Cloud へのマイグレーション ツールの紹介 2020年11月26日 放送
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] Google Cloud における RDBMS の運用パターン 2020年11月19日 放送
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] 事例紹介: 株式会社オープンハウス 〜Google サービスを活用したオープンハウスの AI の取り組み〜 2020年11月1...
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] 【Anthos 演習】 解説を聞きながら Anthos を体験しよう 2020年11月5日 放送
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] 【Google Kubernetes Engine 演習】解説を聞きながら GKE を体験しよう 2020年10月29日 放送
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] Google Cloud の AI / IoT 最新事例紹介 2020年10月22日 放送
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] Google Cloud Next '20: OnAir 特別編 〜世界で人気のあったセッション特集〜 2020年9月24日 放送
by
Google Cloud Platform - Japan
PDF
[Cloud OnAir] Talks by DevRel Vol.5 アプリケーションのモダナイゼーション 2020年9月3日 放送
by
Google Cloud Platform - Japan
PDF
明日から役立つ BigQuery ML 活用 5 つのヒント | Google Cloud INSIDE Games & Apps: Online
by
Google Cloud Platform - Japan
PDF
今だから知りたい BigQuery 再入門 | Google Cloud INSIDE Games & Apps: Online
by
Google Cloud Platform - Japan
PDF
『MAGELLAN BLOCKS』を使って BigQuery を使い倒す!| Google Cloud INSIDE Games & Apps: Online
by
Google Cloud Platform - Japan
ServerlessDays Tokyo 2022 Virtual.pdf
by
Google Cloud Platform - Japan
20221105_GCPUG 女子会 Kubernets 編.pdf
by
Google Cloud Platform - Japan
[External] 2021.12.15 コンテナ移行の前に知っておきたいこと @ gcpug 湘南
by
Google Cloud Platform - Japan
What’s new in cloud run 2021 後期
by
Google Cloud Platform - Japan
【Dialogflow cx】はじめてみよう google cloud dialogflow cx 編
by
Google Cloud Platform - Japan
Google Cloud で実践する SRE
by
Google Cloud Platform - Japan
[Cloud OnAir] 事例紹介 : 株式会社マーケティングアプリケーションズ 〜クラウドへのマイグレーションとその後〜 2020年12月17日 放送
by
Google Cloud Platform - Japan
[Cloud OnAir] 【実演】Google Cloud VMware Engine と VMware ソリューションを組み合わせたハイブリッド環境の...
by
Google Cloud Platform - Japan
[Cloud OnAir] Google Workspace でできる データ分析と業務自動化のご紹介 2020年12月3日 放送
by
Google Cloud Platform - Japan
[Cloud OnAir] Google Cloud へのマイグレーション ツールの紹介 2020年11月26日 放送
by
Google Cloud Platform - Japan
[Cloud OnAir] Google Cloud における RDBMS の運用パターン 2020年11月19日 放送
by
Google Cloud Platform - Japan
[Cloud OnAir] 事例紹介: 株式会社オープンハウス 〜Google サービスを活用したオープンハウスの AI の取り組み〜 2020年11月1...
by
Google Cloud Platform - Japan
[Cloud OnAir] 【Anthos 演習】 解説を聞きながら Anthos を体験しよう 2020年11月5日 放送
by
Google Cloud Platform - Japan
[Cloud OnAir] 【Google Kubernetes Engine 演習】解説を聞きながら GKE を体験しよう 2020年10月29日 放送
by
Google Cloud Platform - Japan
[Cloud OnAir] Google Cloud の AI / IoT 最新事例紹介 2020年10月22日 放送
by
Google Cloud Platform - Japan
[Cloud OnAir] Google Cloud Next '20: OnAir 特別編 〜世界で人気のあったセッション特集〜 2020年9月24日 放送
by
Google Cloud Platform - Japan
[Cloud OnAir] Talks by DevRel Vol.5 アプリケーションのモダナイゼーション 2020年9月3日 放送
by
Google Cloud Platform - Japan
明日から役立つ BigQuery ML 活用 5 つのヒント | Google Cloud INSIDE Games & Apps: Online
by
Google Cloud Platform - Japan
今だから知りたい BigQuery 再入門 | Google Cloud INSIDE Games & Apps: Online
by
Google Cloud Platform - Japan
『MAGELLAN BLOCKS』を使って BigQuery を使い倒す!| Google Cloud INSIDE Games & Apps: Online
by
Google Cloud Platform - Japan
Google Cloud Dataflow を理解する - #bq_sushi
1.
Google Cloud Dataflow を理解する Slava
Chernyak, Senior Software Engineer chernyak@google.com
2.
Googleのビッグデータ Cloud Dataflow SDK Cloud
Dataflow Service バッチ処理とストリーム処理 全体の連携 1 2 3 4 5 アジェンダ
3.
Googleのビッグデータ
4.
Googleでは ビッグデータを表す 特別な用語を使います What is Big
Data at Google?
5.
「データ」 What is Big
Data at Google?
6.
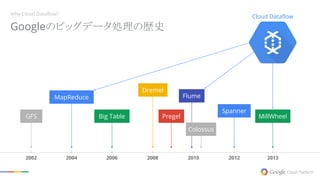
2012 20132002 2004
2006 2008 2010 Cloud Dataflow Googleのビッグデータ処理の歴史 Why Cloud Dataflow? MapReduce GFS Big Table Dremel Pregel Flume Colossus Spanner MillWheel
7.
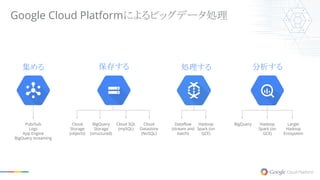
保存する集める 分析する BigQuery Larger Hadoop Ecosystem Hadoop Spark
(on GCE) Pub/Sub Logs App Engine BigQuery streaming 処理する Dataflow (stream and batch) Cloud Storage (objects) Cloud Datastore (NoSQL) Cloud SQL (mySQL) BigQuery Storage (structured) Hadoop Spark (on GCE) Google Cloud Platformによるビッグデータ処理
8.
Cloud Dataflowとは何か
9.
Cloud Dataflowは 並列化された データ処理パイプラインを作 るためのSDK群 What is
Cloud Dataflow? Cloud Dataflowは 並列化された データ処理パイプラインを 実行するための マネージドサービス
10.
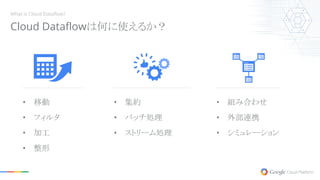
What is Cloud
Dataflow? • 移動 • フィルタ • 加工 • 整形 • 集約 • バッチ処理 • ストリーム処理 • 組み合わせ • 外部連携 • シミュレーション Cloud Dataflowは何に使えるか?
11.
• (変換に基づく)関数型プログラミングモデル • バッチ処理とストリーム処理を統合 •
クラスタ管理の運用コストを削減 • 次世代のプラットフォームによるジョブ実行時間の縮小 • SDK、プラグイン、Runner等のオープンソース エコシステム Cloud Dataflowのメリット What is Cloud Dataflow?
12.
Cloud Dataflowのリリース スケジュール What
is Cloud Dataflow? • June 24, 2014: Google I/Oで発表 • Dec. 17, 2014: Alpha版 • Apr. 15, 2015: Beta版 • 次は: 一般公開
13.
Cloud Dataflow SDK
14.
ハッシュタグのオートコンプリートの実装例 入力した文字列 サジェストするリスト #ar #argentina,
#arugularocks, #argylesocks #arg #argentina, #argylesocks, #argonauts #arge #argentina, #argentum, #argentine
15.
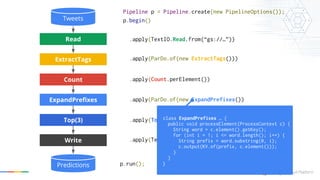
{a->[apple, art, argentina],
ar->[art, argentina, armenia],...} Count ExpandPrefixes Top(3) Write Read ExtractTags {a->(argentina, 5M), a->(armenia, 2M), …, ar-> (argentina, 5M), ar->(armenia, 2M), ...} {#argentina scores!, watching #armenia vs #argentina, my #art project, …} {argentina, armenia, argentina, art, ...} {argentina->5M, armenia->2M, art->90M, ...} Tweets Predictions
16.
Count ExpandPrefixes Top(3) Write Read ExtractTags Tweets Predictions Pipeline p =
Pipeline.create(new PipelineOptions()); p.begin() p.run(); .apply(ParDo.of(new ExtractTags())) .apply(Top.largestPerKey(3)) .apply(Count.perElement()) .apply(ParDo.of(new ExpandPrefixes()) .apply(TextIO.Write.to(“gs://…”)); .apply(TextIO.Read.from(“gs://…”)) class ExpandPrefixes … { public void processElement(ProcessContext c) { String word = c.element().getKey(); for (int i = 1; i <= word.length(); i++) { String prefix = word.substring(0, i); c.output(KV.of(prefix, c.element())); } } }
17.
• 異なるRunnerを使い、同じコードをさまざまな方法で実行可能 • Direct
Runner • ローカル環境でインメモリ実行できる • 開発やテストに最適 • Cloud Dataflow Service Runner • フルマネージドのDataflowサービス上で動作 • 複数のGCEインスタンス上で分散実行 • コミュニティによる実装 • Spark runner @ github.com/cloudera/spark-dataflow • Flink runner coming soon from dataArtisans Cloud Dataflow Runners
18.
Cloud Dataflow Service
19.
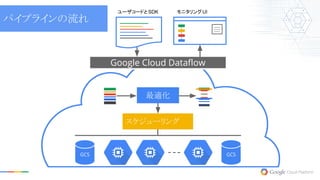
Google Cloud Dataflow 最適化 スケジューリング GCS
GCS ユーザコードとSDK モニタリングUI パイプラインの流れ
20.
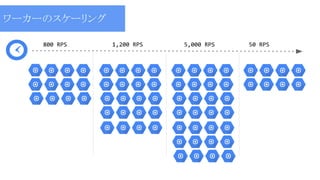
800 RPS 1,200
RPS 5,000 RPS 50 RPS ワーカーのスケーリング
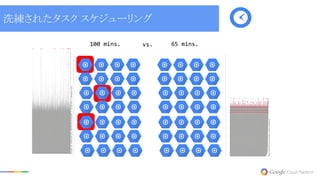
21.
100 mins. 65
mins. 洗練されたタスク スケジューリング vs.
22.
バッチ処理とストリーム処理
23.
Google Cloud Pub/Subでストリームを読み書き ストリーム処理しよう!
24.
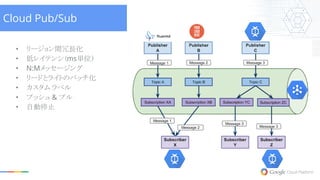
• リージョン間冗長化 • 低レイテンシ(ms単位) •
N:Mメッセージング • リードとライトのバッチ化 • カスタム ラベル • プッシュ & プル • 自動停止 Cloud Pub/Sub
25.
Pipeline p =
Pipeline.create(new PipelineOptions()); p.begin() .apply(TextIO.Read.from(“gs://…”)) .apply(ParDo.of(new ExtractTags())) .apply(Count.perElement()) .apply(ParDo.of(new ExpandPrefixes()) .apply(Top.largestPerKey(3)) .apply(TextIO.Write.to(“gs://…”)); p.run();
26.
Pipeline p =
Pipeline.create(new PipelineOptions()); p.begin() .apply(TextIO.Read.from(“gs://…”)) .apply(ParDo.of(new ExtractTags())) .apply(Count.perElement()) .apply(ParDo.of(new ExpandPrefixes()) .apply(Top.largestPerKey(3)) .apply(TextIO.Write.to(“gs://…”)); p.run();
27.
Pipeline p =
Pipeline.create(new PipelineOptions()); p.begin() .apply(PubsubIO.Read.topic(“input_topic”)) .apply(ParDo.of(new ExtractTags())) .apply(Count.perElement()) .apply(ParDo.of(new ExpandPrefixes()) .apply(Top.largestPerKey(3)) .apply(PubsubIO.Write.topic(“output_topic”)); p.run();
28.
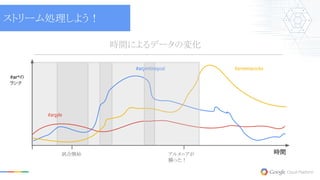
時間 #ar*の ランク 試合開始 アルメニアが 勝った! #argyle #armeniarocks 時間によるデータの変化 #argentinagoal ストリーム処理しよう!
29.
Pipeline p =
Pipeline.create(new PipelineOptions()); p.begin() .apply(PubsubIO.Read.topic(“input_topic”)) .apply(ParDo.of(new ExtractTags())) .apply(Count.perElement()) .apply(ParDo.of(new ExpandPrefixes()) .apply(Top.largestPerKey(3)) .apply(PubsubIO.Write.topic(“output_topic”)); p.run();
30.
Pipeline p =
Pipeline.create(new PipelineOptions()); p.begin() .apply(PubsubIO.Read.topic(“input_topic”)) .apply(ParDo.of(new ExtractTags())) .apply(Count.perElement()) .apply(ParDo.of(new ExpandPrefixes()) .apply(Top.largestPerKey(3)) .apply(PubsubIO.Write.topic(“output_topic”)); p.run();
31.
Pipeline p =
Pipeline.create(new PipelineOptions()); p.begin() .apply(PubsubIO.Read.topic(“input_topic”)) .apply(Window.into(SlidingWindows.of( Duration.standardMinutes(60))) .apply(ParDo.of(new ExtractTags())) .apply(Count.perElement()) .apply(ParDo.of(new ExpandPrefixes()) .apply(Top.largestPerKey(3)) .apply(PubsubIO.Write.topic(“output_topic”)); p.run();
32.
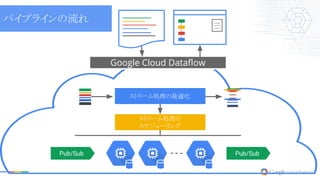
Google Cloud Dataflow ストリーム処理の最適化 ストリーム処理の スケジューリング Pub/Sub
Pub/Sub パイプラインの流れ
33.
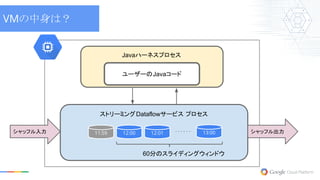
VMの中身は? Javaハーネスプロセス ユーザーのJavaコード ストリーミングDataflowサービス プロセス 11:59 12:00
12:01 13:00 60分のスライディングウィンドウ シャッフル入力 シャッフル出力
34.
全体の連携
35.
❯ Google Cloud
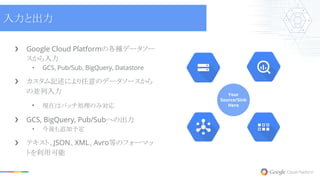
Platformの各種データソー スから入力 • GCS, Pub/Sub, BigQuery, Datastore ❯ カスタム記述により任意のデータソースから の並列入力 • 現在はバッチ処理のみ対応 ❯ GCS, BigQuery, Pub/Subへの出力 • 今後も追加予定 ❯ テキスト、JSON、XML、Avro等のフォーマッ トを利用可能 Your Source/Sink Here 入力と出力
36.
● Dataflow SDKのPythonサポート ●
さらに強力な機能をDataflow SDKに追加 ● Dataflowサービスを今後も改善 ● さらにいろいろ! 今後の展望
37.
エンジニアの作業時間を節約
38.
(provisioning) エンジニアの作業時間を節約
39.
(fault-tolerance) エンジニアの作業時間を節約
40.
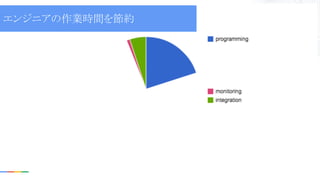
(deployment issues) エンジニアの作業時間を節約
41.
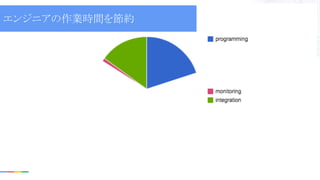
(improving utilization) エンジニアの作業時間を節約
42.
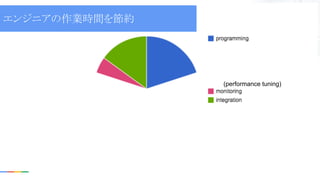
(performance tuning) エンジニアの作業時間を節約
43.
エンジニアの作業時間を節約
44.
エンジニアの作業時間を節約
45.
Thank You! cloud.google.com/dataflow
47.
cloud.google.com/dataflow stackoverflow.com/questions/tagged/google-cloud-dataflow github.com/GoogleCloudPlatform/DataflowJavaSDK はじめよう
Download












![{a->[apple, art, argentina], ar->[art, argentina, armenia],...}
Count
ExpandPrefixes
Top(3)
Write
Read
ExtractTags
{a->(argentina, 5M), a->(armenia, 2M), …, ar->
(argentina, 5M), ar->(armenia, 2M), ...}
{#argentina scores!, watching #armenia vs
#argentina, my #art project, …}
{argentina, armenia, argentina, art, ...}
{argentina->5M, armenia->2M, art->90M, ...}
Tweets
Predictions](https://image.slidesharecdn.com/japanesedataflow-gcpjapanbqsushi-150428002802-conversion-gate02/85/Google-Cloud-Dataflow-bq_sushi-15-320.jpg)



















![[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/dddddd-180906091548-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[Cloud OnAir] GCP 上でストリーミングデータ処理基盤を構築してみよう! 2018年9月13日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/oooooo-180913090941-thumbnail.jpg?width=640&height=640&fit=bounds)















![[CEDEC 2018] グローバル スケール コネクテッドゲームを GCP で作ろう!](https://cdn.slidesharecdn.com/ss_thumbnails/cedec2018-180828084042-thumbnail.jpg?width=640&height=640&fit=bounds)




![[External] 2021.12.15 コンテナ移行の前に知っておきたいこと @ gcpug 湘南](https://cdn.slidesharecdn.com/ss_thumbnails/external2021-211216025522-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Cloud OnAir] 事例紹介 : 株式会社マーケティングアプリケーションズ 〜クラウドへのマイグレーションとその後〜 2020年12月17日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ppp-201221033858-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【実演】Google Cloud VMware Engine と VMware ソリューションを組み合わせたハイブリッド環境の...](https://cdn.slidesharecdn.com/ss_thumbnails/pta-201210085248-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Workspace でできる データ分析と業務自動化のご紹介 2020年12月3日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ol-201203090835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud へのマイグレーション ツールの紹介 2020年11月26日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ii-201126090801-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud における RDBMS の運用パターン 2020年11月19日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/yy-201119084816-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 事例紹介: 株式会社オープンハウス 〜Google サービスを活用したオープンハウスの AI の取り組み〜 2020年11月1...](https://cdn.slidesharecdn.com/ss_thumbnails/h-201112061942-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【Anthos 演習】 解説を聞きながら Anthos を体験しよう 2020年11月5日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ab-201105085037-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【Google Kubernetes Engine 演習】解説を聞きながら GKE を体験しよう 2020年10月29日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/bb-201029090440-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud の AI / IoT 最新事例紹介 2020年10月22日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/aa-201022092013-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud Next '20: OnAir 特別編 〜世界で人気のあったセッション特集〜 2020年9月24日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ooo-200924094839-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Talks by DevRel Vol.5 アプリケーションのモダナイゼーション 2020年9月3日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ffffffffffffffff-200903090943-thumbnail.jpg?width=640&height=640&fit=bounds)


