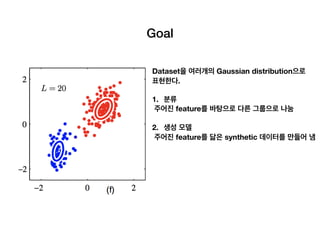
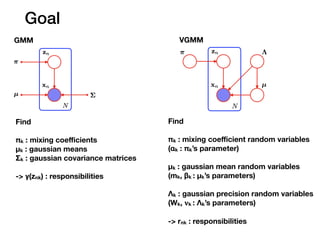
Big picture
VGMM
1. pi,Z와 mu, Lambda가 독립이라고 가정
2. pi, mu, Lambda가 고정된 상태서 Z를 최적화 (E-step)
3. Z가 고정된 상태에서 pi, mu, Lambda를 최적화 (M-step)
Z를 고정하면 (observed) pi와 mu, Lambda가 독립
4. 2. 3. step을 반복
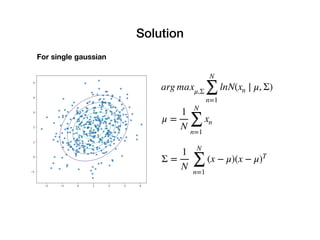
10.
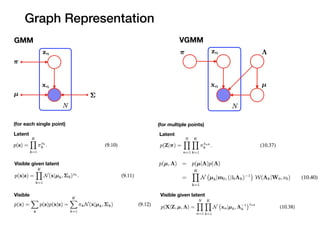
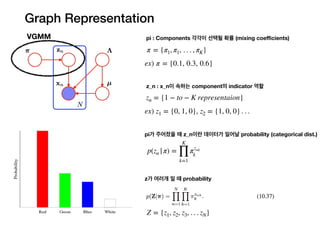
Graph Representation
VGMM
p(zn |π)=
K
∏
k=1
πznk
k
π = {π1, π1, . . . , πK}
zn = {1 − to − K representaion}
pi : Components 각각이 선택될 확률 (mixing coefficients)
z_n : x_n이 속하는 component의 indicator 역할
pi가 주어졌을 때 z_n이란 데이터가 일어날 probability (categorical dist.)
z가 여러개 일 때 probability
ex) π = {0.1, 0.3, 0.6}
ex) z1 = {0, 1, 0}, z2 = {1, 0, 0} . . .
Z = {z1, z2, z3, . . . zN}
11.
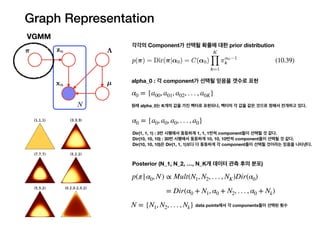
Graph Representation
VGMM
각각의 Component가선택될 확률에 대한 prior distribution
alpha_0 : 각 component가 선택될 믿음을 갯수로 표현
α0 = {a00, a01, a02, . . . , a0K}
원래 alpha_0는 K개의 값을 가진 벡터로 표현되나, 벡터의 각 값을 같은 것으로 정해서 전개하고 있다.
α0 = {a0, a0, a0, . . . , a0}
Dir(1, 1, 1) : 3번 시행에서 동등하게 1, 1, 1번씩 component들이 선택될 것 같다.
Dir(10, 10, 10) : 30번 시행에서 동등하게 10, 10, 10번씩 component들이 선택될 것 같다.
Dir(10, 10, 10)은 Dir(1, 1, 1)보다 더 동등하게 각 component들이 선택될 것이라는 믿음을 나타낸다.
Posterior (N_1, N_2, …, N_K개 데이터 관측 후의 분포)
p(π|α0, N) ∝ Mult(N1, N2, . . . , NK)Dir(α0)
N = {N1, N2, . . . , Nk} data points에서 각 components들이 선택된 횟수
= Dir(α0 + N1, α0 + N2, . . . , α0 + Nk)
12.
Graph Representation
Posterior :Dir(4, 3, 5) - 이 동물원에서 13번 동물을 마주칠 경우,
고양이, 강아지, 토끼가 4, 3, 6번 꼴로 나타날꺼야.
Prior : Dir(1, 1, 1) - 이 동물원에서 3번 동물을 마주칠 경우,
고양이, 강아지, 토끼가 1, 1, 1번 꼴로 나타날꺼야.
Likelihood : Mult(3, 2, 4) - 이 동물원에서 9번 동물을 마주쳤더니,
고양이, 강아지, 토끼가 3, 2, 4번 나타났다.
13.
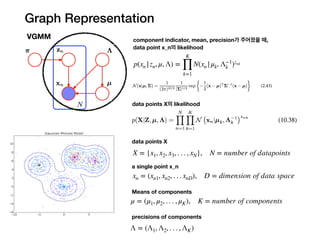
Graph Representation
VGMM componentindicator, mean, precision가 주어졌을 때,
data point x_n의 likelihood
p(xn |zn, μ, Λ) =
K
∏
k=1
N(xn |μk, Λ−1
k )znk
data points X의 likelihood
X = {x1, x2, x3, . . . , xN}, N = number of datapoints
xn = (xn1, xn2, . . . xnD), D = dimension of data space
μ = (μ1, μ2, . . . , μK), K = number of components
Λ = (Λ1, Λ2, . . . , ΛK)
data points X
a single point x_n
Means of components
precisions of components
14.
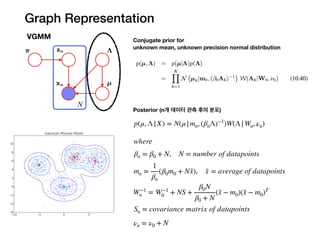
Graph Representation
VGMM Conjugateprior for
unknown mean, unknown precision normal distribution
Posterior (n개 데이터 관측 후의 분포)
p(μ, Λ|X) = N(μ|mn, (βnΛ)−1
)W(Λ|Wn, νn)
where
βn = β0 + N, N = number of datapoints
mn =
1
βn
(β0m0 + N¯x), ¯x = average of datapoints
W−1
n = W−1
0 + NS +
β0N
β0 + N
(¯x − m0)(¯x − m0)T
νn = ν0 + N
Sn = covariance matrix of datapoints
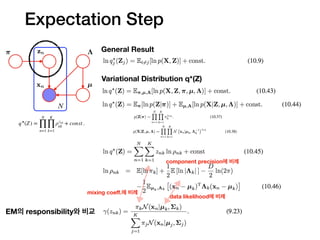
General Result
Variational Distributionq*(Z)
EM의 responsibility와 비교
q⋆
(Z) =
N
∏
n=1
K
∏
k=1
ρznk
nk
+ const .
Expectation Step
mixing coeff.에 비례
data likelihood에 비례
component precision에 비례
26.
Expectation Step
expectation step에서구한 r_nk는 responsibility에 해당하고,
maximization step에서 쓰일 수 있도록 몇가지 통계값을 구해놓는다.
(data nums, means, covariances)
(categorical dist.의 expected value)
자세히 살펴보면 pi에대한 식과, mu, Lambda에 대한 식으로 분리 가능
왜 이런일 일어나는가?
E-step에서 구한 Z에 대해 pi, mu, Lambda가 독립이라 가정하면,
pi와 mu, Lambda는 독립이 되기 때문이다. (D-separation)
ln q⋆
(π) = ln p(π) + EZ[ln p(Z|π)] + const .
ln q⋆
(μ, Λ) =
K
∑
k=1
ln p(μk, Λk) + Ez[ln p(Z|π)] +
K
∑
k=1
N
∑
n=1
E[znk]ln N(xn |muk, Λ−1
k ) + const .
Maximization Step
30.
ln q⋆
(π) =ln p(π) + EZ[ln p(Z|π)] + const .
by prior of pi (10.39) and
Conditional distribution Z given pi (10.37)
양 변에 exponential 취하면 q^star(pi)를 디리클레 분포로 볼 수 있다.
pi가 Lambda, mu와 독립이라고 가정했으므로, 단지 prior와 N_1, N_2, N_3개의
데이터가 주어졌을 때의 posterior와 같다.
p(π|α0, N) ∝ Cat(N1, N2, . . . , NK)Dir(α0)
= Dir(α0 + N1, α0 + N2, . . . , α0 + Nk)
Maximization Step
EM의 mixing coeff.와 비교
N개의 데이터 중 N_k개 속함
N_1 + N_2 +. … + N_k개 데이터가 관측됐을 때,
k클래스는 alpha_0 + N_k개 관측될 것이라는 믿음으로 업데이트!
31.
ln q⋆
(μ, Λ)=
K
∑
k=1
ln p(μk, Λk) +
K
∑
k=1
N
∑
n=1
E[znk]ln N(xn |μk, Λ−1
k ) + const .
mu, Lambda가 pi, Z와 독립이라고 가정했으므로,
Z가 정해진 상황에서, mu, Lambda에 대한 prior와
N_1, N_2, …, N_k개의 데이터가 주어졌을 때의 posterior와 같다.
EM의 mu, Sigma와 비교
N_k가 클수록 mean의 precision 증가
N_k가 클수록 data mean에 가까워짐
N_k가 클수록
precision matrix의
자유도 증가
N_k가 클수록 data precision의 영향력이 커지며,
N_k가 클수록 data mean과 prior mean의 차이만큼
variance가 커지는 것으로 보상
ln q⋆
(μk, Λk) = ln p(μk, Λk) +
N
∑
n=1
E[znk]ln N(xn |μk, Λ−1
k ) + const .
Prior Likelihood (resposibility로 weight되어 있음)
Maximization Step









![Wishart Distribution
W(
[
1 0
0 1]
, 2)](https://image.slidesharecdn.com/gmmtovgmm-181005074507/85/Gmm-to-vgmm-17-320.jpg)
![Wishart Distribution
W(
[
1 0
0 1]
, 100)](https://image.slidesharecdn.com/gmmtovgmm-181005074507/85/Gmm-to-vgmm-18-320.jpg)
![Graph Representation
Prior : datapoint들의 mean과 covariance는
N(μ|0,1Λ) W(Λ|
[
1 0
0 1]
,2) 의 분포를 따를꺼야.](https://image.slidesharecdn.com/gmmtovgmm-181005074507/85/Gmm-to-vgmm-19-320.jpg)
![Graph Representation
Likelihood : 1000개의 datapoint들이 N(x|[2, 3],
[
2 1.5
1.5 2 ]
)
의 분포에서 최대 likelihood를 갖는것을 발견했다.](https://image.slidesharecdn.com/gmmtovgmm-181005074507/85/Gmm-to-vgmm-20-320.jpg)
![Graph Representation
posterior : datapoint들의 mean과 covariance는
와 같은 분포를 따를꺼야.p(μ, Λ|X) = N(μ|mn, (βnΛ)−1
)W(Λ|Wn, νn)
where
βn = β0 + N, N = number of datapoints
mn =
1
βn
(β0m0 + N ¯x), ¯x = average of datapoints
W−1
n = W−1
0 + NS +
β0N
β0 + N
(¯x − m0)(¯x − m0)T
νn = ν0 + N
Sn = covariance matrix of datapoints
βn = 1 + 1000
mn =
1
βn
(1 + [0,0]T
+ 1000[2,3]T
)
W−1
n =
[
1 0
0 1]
−1
+ 1000
[
2 1.5
1.5 2 ]
+
1 ⋅ 1000
1 + 1000
([2,3] − [0,0])([2,3] − [0,0])T
νn = 2 + 1000](https://image.slidesharecdn.com/gmmtovgmm-181005074507/85/Gmm-to-vgmm-21-320.jpg)




![Maximization Step
General Result
Variational Distribution
ln q⋆
(π, μ, Λ) = EZ[ln p(X, Z, π, μ, Λ)] + const .
= EZ[ln [p(X|Z, μ, Λ)p(Z|π)p(π)p(μ|Λ)p(Λ)]] + const .
= EZ[ln p(X|Z, μ, Λ) + ln p(Z|π) + ln p(π) + ln p(μ|Λ)p(Λ)] + const .
= EZ[ln p(X|Z, μ, Λ)] + EZ[ln p(Z|π)] + EZ[ln p(π)] + EZ[ln p(μ|Λ)p(Λ)] + const .
q⋆
(π, μ, Λ)
by factorization (10.41)
by property of log
by linearity of expectation](https://image.slidesharecdn.com/gmmtovgmm-181005074507/85/Gmm-to-vgmm-28-320.jpg)
![자세히 살펴보면 pi에 대한 식과, mu, Lambda에 대한 식으로 분리 가능
왜 이런일 일어나는가?
E-step에서 구한 Z에 대해 pi, mu, Lambda가 독립이라 가정하면,
pi와 mu, Lambda는 독립이 되기 때문이다. (D-separation)
ln q⋆
(π) = ln p(π) + EZ[ln p(Z|π)] + const .
ln q⋆
(μ, Λ) =
K
∑
k=1
ln p(μk, Λk) + Ez[ln p(Z|π)] +
K
∑
k=1
N
∑
n=1
E[znk]ln N(xn |muk, Λ−1
k ) + const .
Maximization Step](https://image.slidesharecdn.com/gmmtovgmm-181005074507/85/Gmm-to-vgmm-29-320.jpg)
![ln q⋆
(π) = ln p(π) + EZ[ln p(Z|π)] + const .
by prior of pi (10.39) and
Conditional distribution Z given pi (10.37)
양 변에 exponential 취하면 q^star(pi)를 디리클레 분포로 볼 수 있다.
pi가 Lambda, mu와 독립이라고 가정했으므로, 단지 prior와 N_1, N_2, N_3개의
데이터가 주어졌을 때의 posterior와 같다.
p(π|α0, N) ∝ Cat(N1, N2, . . . , NK)Dir(α0)
= Dir(α0 + N1, α0 + N2, . . . , α0 + Nk)
Maximization Step
EM의 mixing coeff.와 비교
N개의 데이터 중 N_k개 속함
N_1 + N_2 +. … + N_k개 데이터가 관측됐을 때,
k클래스는 alpha_0 + N_k개 관측될 것이라는 믿음으로 업데이트!](https://image.slidesharecdn.com/gmmtovgmm-181005074507/85/Gmm-to-vgmm-30-320.jpg)
![ln q⋆
(μ, Λ) =
K
∑
k=1
ln p(μk, Λk) +
K
∑
k=1
N
∑
n=1
E[znk]ln N(xn |μk, Λ−1
k ) + const .
mu, Lambda가 pi, Z와 독립이라고 가정했으므로,
Z가 정해진 상황에서, mu, Lambda에 대한 prior와
N_1, N_2, …, N_k개의 데이터가 주어졌을 때의 posterior와 같다.
EM의 mu, Sigma와 비교
N_k가 클수록 mean의 precision 증가
N_k가 클수록 data mean에 가까워짐
N_k가 클수록
precision matrix의
자유도 증가
N_k가 클수록 data precision의 영향력이 커지며,
N_k가 클수록 data mean과 prior mean의 차이만큼
variance가 커지는 것으로 보상
ln q⋆
(μk, Λk) = ln p(μk, Λk) +
N
∑
n=1
E[znk]ln N(xn |μk, Λ−1
k ) + const .
Prior Likelihood (resposibility로 weight되어 있음)
Maximization Step](https://image.slidesharecdn.com/gmmtovgmm-181005074507/85/Gmm-to-vgmm-31-320.jpg)












![[PRML] パターン認識と機械学習(第2章:確率分布)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter2-171002030018-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[한글] Tutorial: Sparse variational dropout](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialsparsevariationaldropout-190728122300-thumbnail.jpg?width=640&height=640&fit=bounds)














![[216]딥러닝예제로보는개발자를위한통계 최재걸](https://cdn.slidesharecdn.com/ss_thumbnails/216-161025031655-thumbnail.jpg?width=640&height=640&fit=bounds)
