Downloaded 15 times




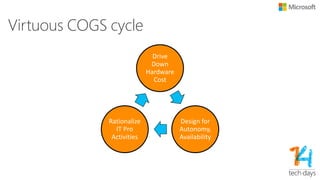



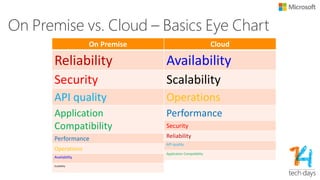







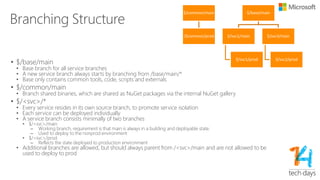



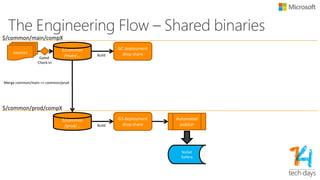
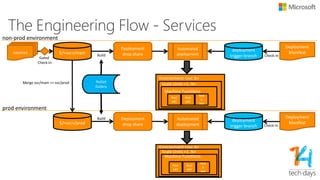

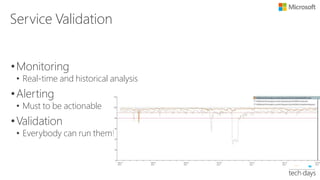













The document outlines principles for software design and cloud computing, emphasizing simplicity, reliability, and scalability in engineering practices. It promotes self-assembling systems and highlights the importance of efficient operations, including automated deployments and proactive maintenance strategies. Key best practices recommended include designing for failure, loose coupling, and effective versioning to support dynamic service environments.

























![Perforce webinar clear-case_jb[2]](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-webinarclearcasejb2-171107142005-thumbnail.jpg?width=640&height=640&fit=bounds)









































