This document provides an introduction to generative adversarial networks (GANs). It discusses how GANs work by framing image generation as a game between a generator network that produces images and a discriminator network that evaluates them. The generator is trained to produce more realistic images that can fool the discriminator while the discriminator is trained to better distinguish real from generated images. GANs allow generating new images in one step by passing random noise to the trained generator network.

















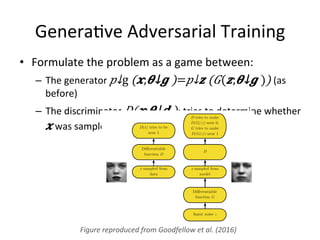
![Genera)ve Adversarial Training
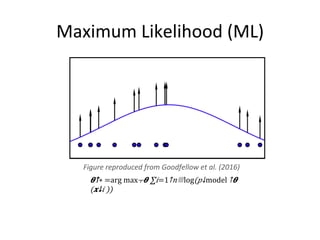
𝜽↓𝒈 ↑∗ =argmin┬𝜽↓𝒈 max┬𝜽↓𝒅 𝔼↓𝑥~𝑝↓data [log𝐷(𝒙;𝜽↓𝒅 ) ] +𝔼↓𝑧~𝑝↓𝐳 [
log(1−𝐷(𝐺(𝒛;𝜽↓𝒈 )) ]
• Formally:
Figure reproduced from Goodfellow et al. (2014)](https://image.slidesharecdn.com/generativeadversarialnets-220814074743-3279cc94/85/Generative-Adversarial-Nets-pdf-21-320.jpg)


![The Minimax Game (Generalized)
• D minimizes 𝐽↑(𝐷) (𝜽↓𝒈 ,𝜽↓𝒅 ) w.r.t. 𝜽↓𝒅 and
updates 𝜽↓𝒅
• G minimizes 𝐽↑(𝐺) (𝜽↓𝒈 ,𝜽↓𝒅 ) w.r.t. 𝜽↓𝒈 and
updates 𝜽↓𝒈
• For D, we always use the cross entropy:
𝐽↑(𝐷) =−𝔼↓𝑥~𝑝↓data [log𝐷(𝒙;𝜽↓𝒅 ) ]−
𝔼↓𝑧~𝑝↓𝐳 [log(1−𝐷(𝐺(𝒛;𝜽↓𝒈 )) ]
• For G, in the minimax game:](https://image.slidesharecdn.com/generativeadversarialnets-220814074743-3279cc94/85/Generative-Adversarial-Nets-pdf-24-320.jpg)
![Heuris)c non-satura)ng game
• Problem with minimax: when 𝐷 rejects generated
samples, G has no gradient!
• Solu)on: flip the target of the cross-entropy for G
𝐽↑(𝐺) =𝔼↓𝑧~𝑝↓𝐳 [log(𝐷(𝐺(𝒛;𝜽↓𝒈 )) ]
• G minimizes: 𝐷↓𝐾𝐿 (𝑝↓model ‖𝑝↓data )−2𝐷↓𝐽𝑆
(𝑝↓data ‖𝑝↓model )
• L Not nice (but it works!):
– No longer a 0-sum game
– Gets us even further from the theore)cal guarantees
• Recent work by Arjovski et. al. (2017) removes
the need for such tricks J (not presented here)](https://image.slidesharecdn.com/generativeadversarialnets-220814074743-3279cc94/85/Generative-Adversarial-Nets-pdf-25-320.jpg)
![Maximum likelihood game
• It can be shown that the minimax game
op)mizes the Jensen-Shannon (JS) divergence
between 𝑝↓data and 𝑝↓model
• We can make the model op)mize the KL
divergence if we set
𝐽↑(𝐺) =−𝔼↓𝑧~𝑝↓𝐳 [log(𝜌↑−1 (𝐺(𝒛;𝜽↓𝒈 )) ]](https://image.slidesharecdn.com/generativeadversarialnets-220814074743-3279cc94/85/Generative-Adversarial-Nets-pdf-26-320.jpg)







![References
• [1] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S.
Ozair, A. Courville and Y. Bengio. “Genera)ve Adversarial Nets”, NIPS,
2014.
• [2] I. Goodfellow, ”Genera)ve Adversarial Networks”, NIPS 2016 Tutorial
• [3] M. Arjovsky, S. Chintala, L. BoTou, “Wasserstein GAN”, ArXiV
1701.07875v2, 2017
• [4] S. Albanie, S. Ehrhardt, J. F. Henriques, “Stopping GAN Violence:
Genera)ve Unadversarial Networks”, ArXiV 1703.02528v1, 2017](https://image.slidesharecdn.com/generativeadversarialnets-220814074743-3279cc94/85/Generative-Adversarial-Nets-pdf-34-320.jpg)















































