Download as PDF, PPTX








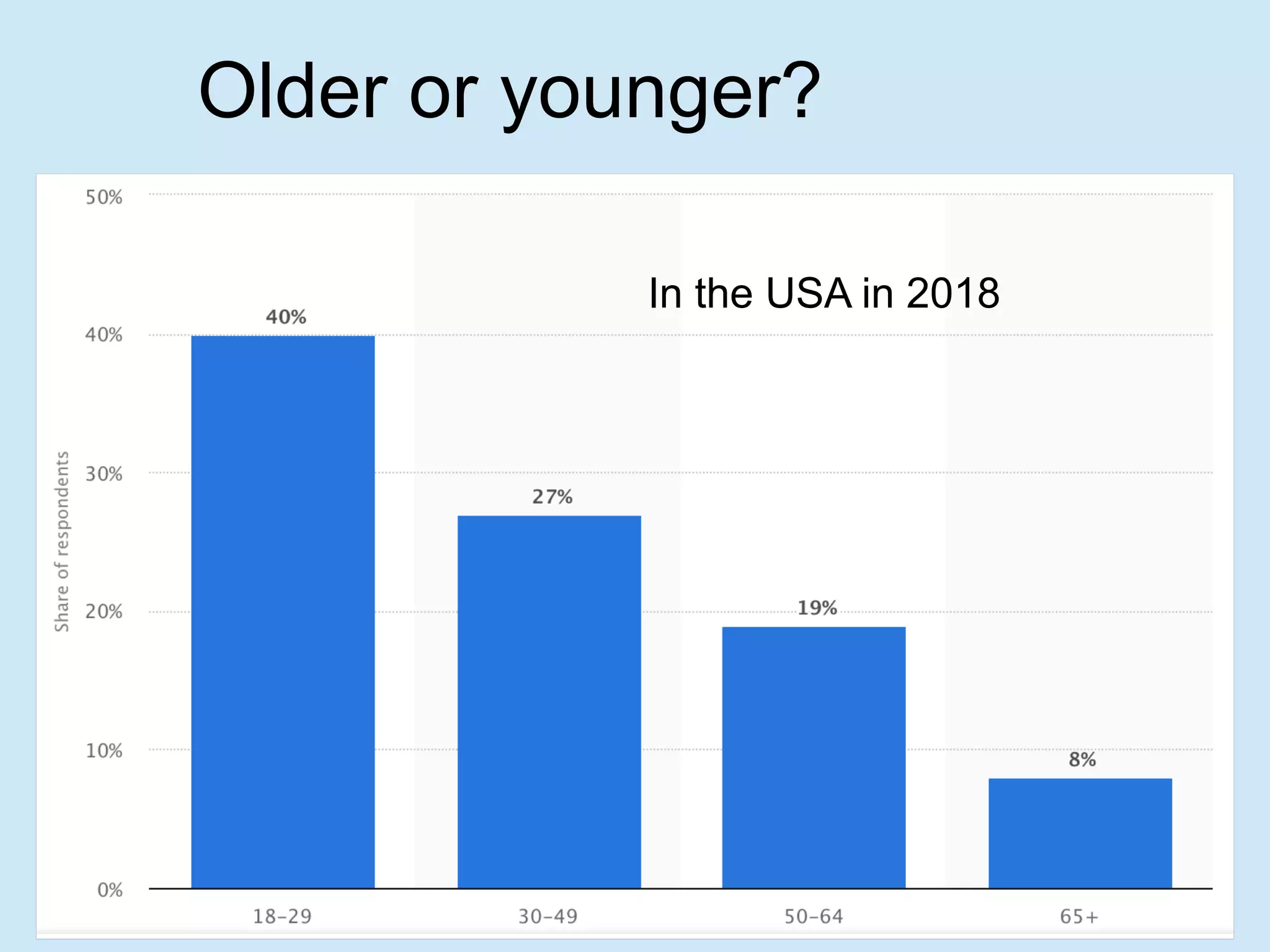



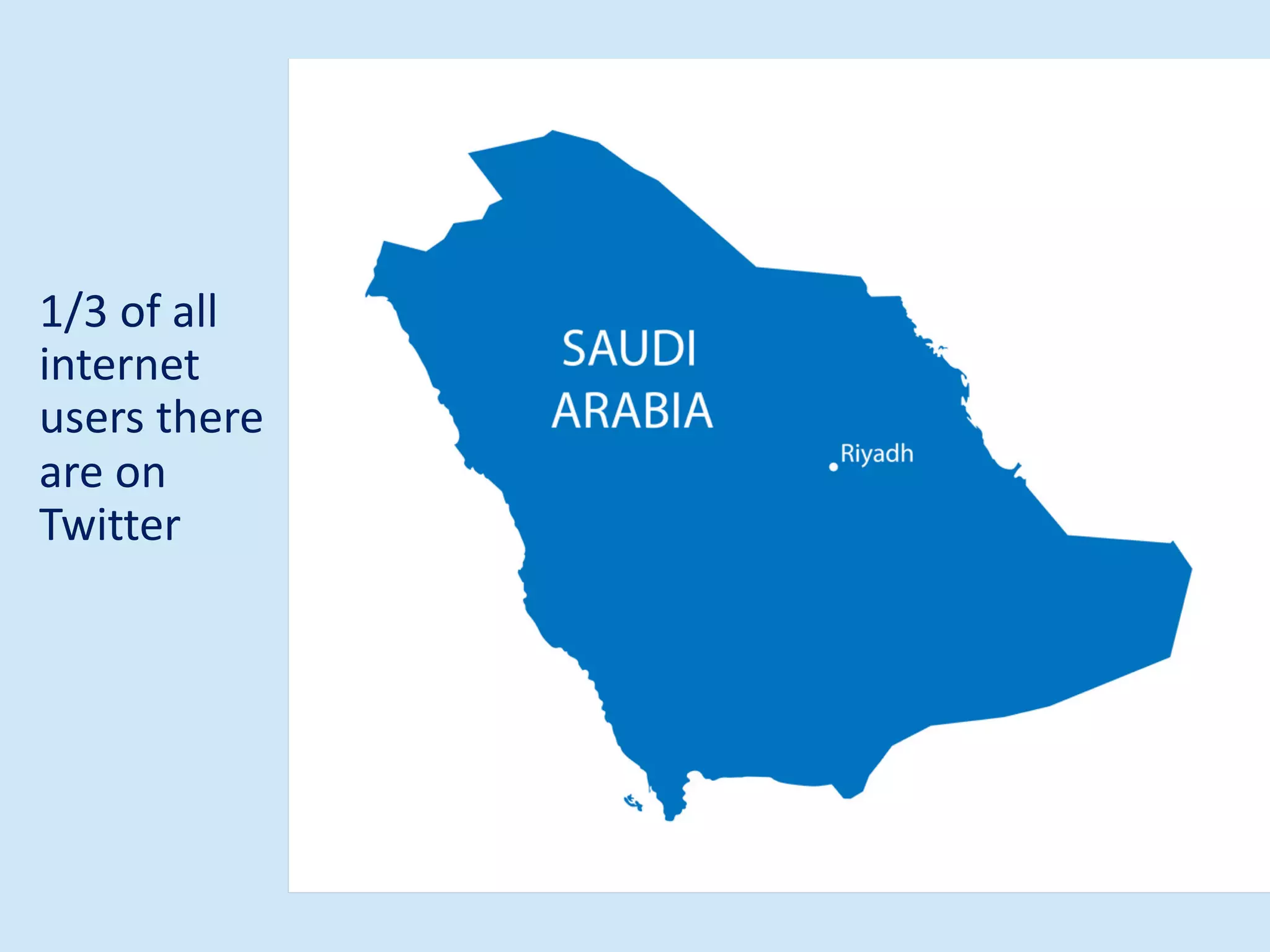








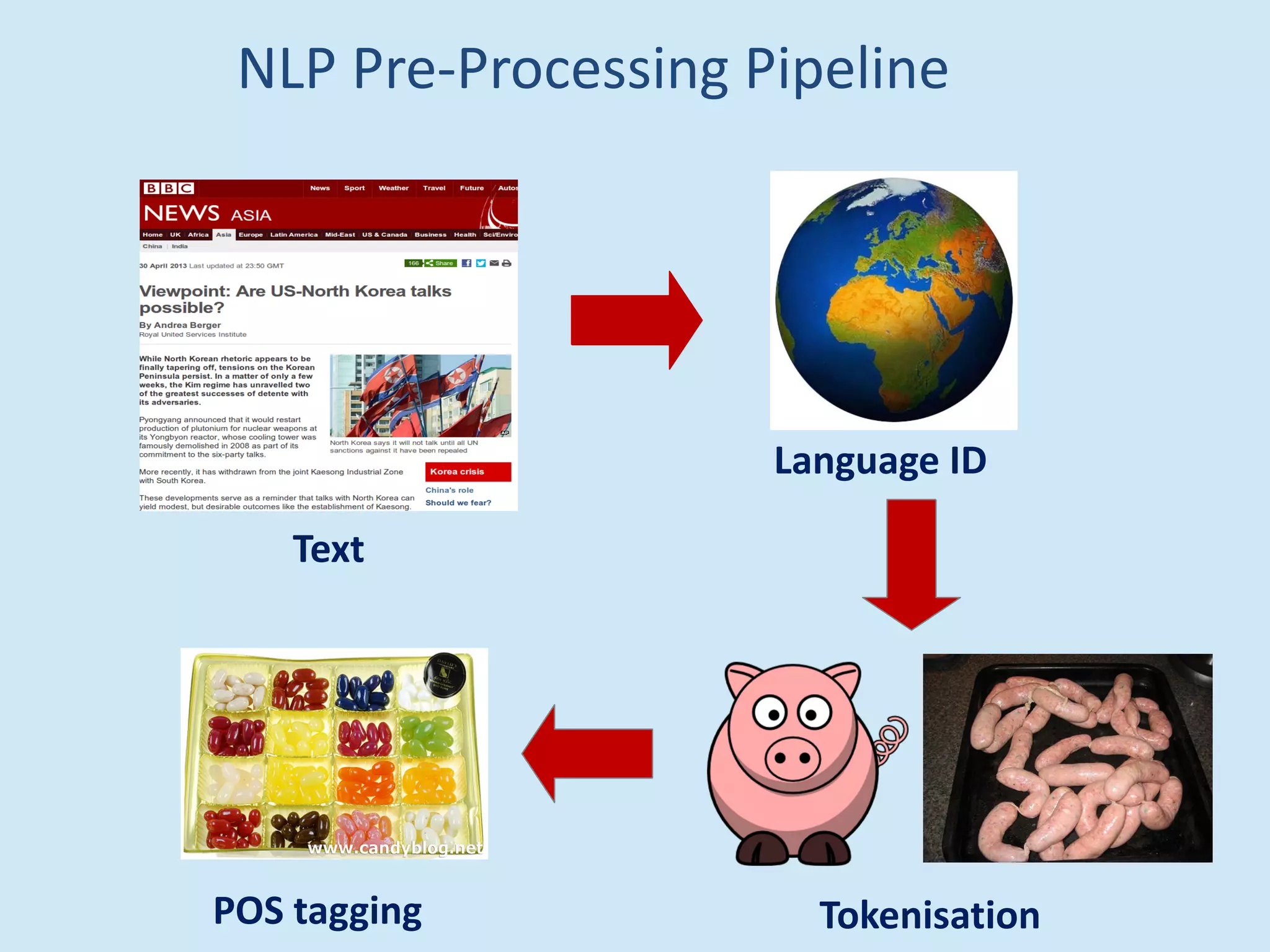

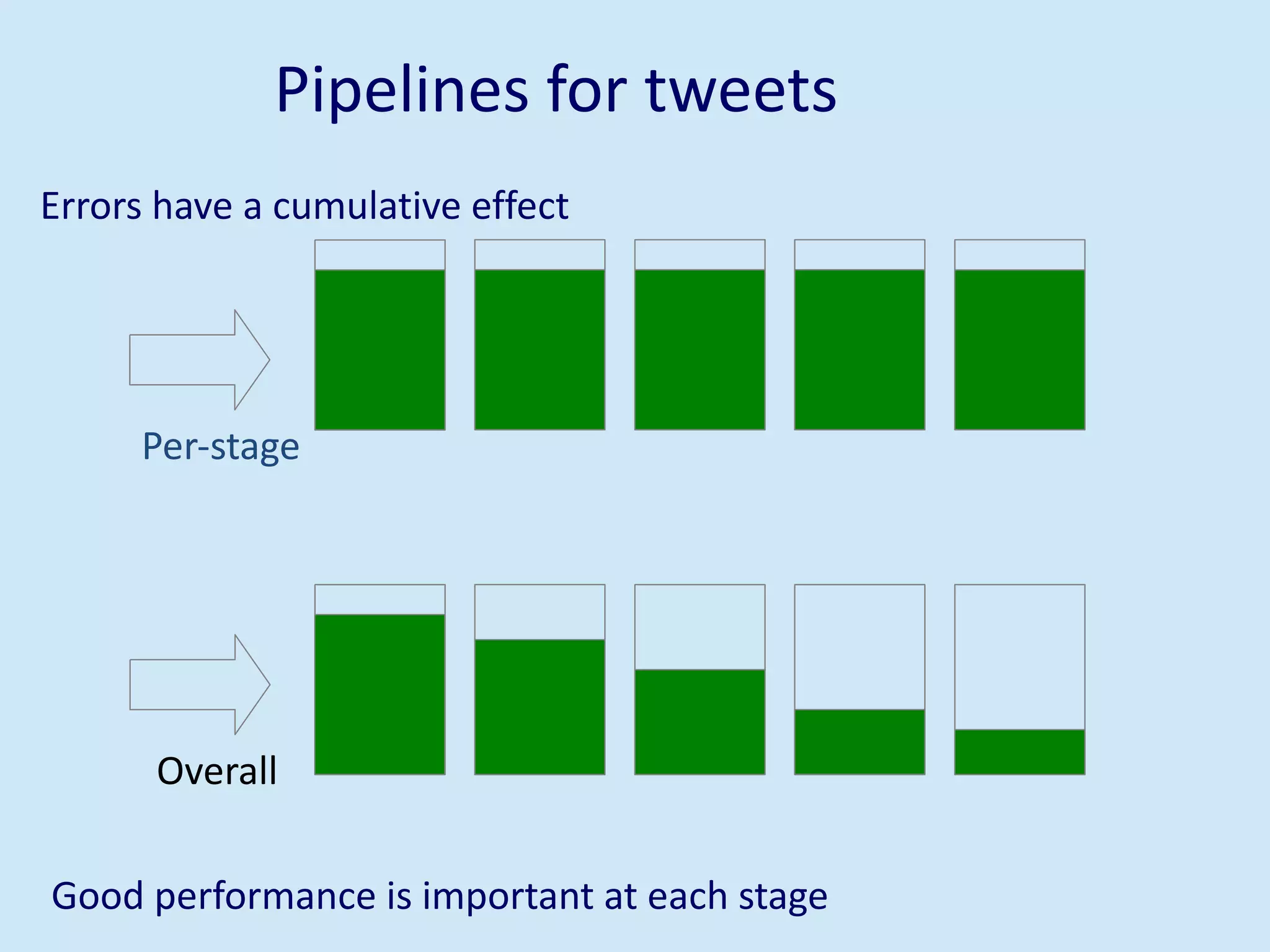


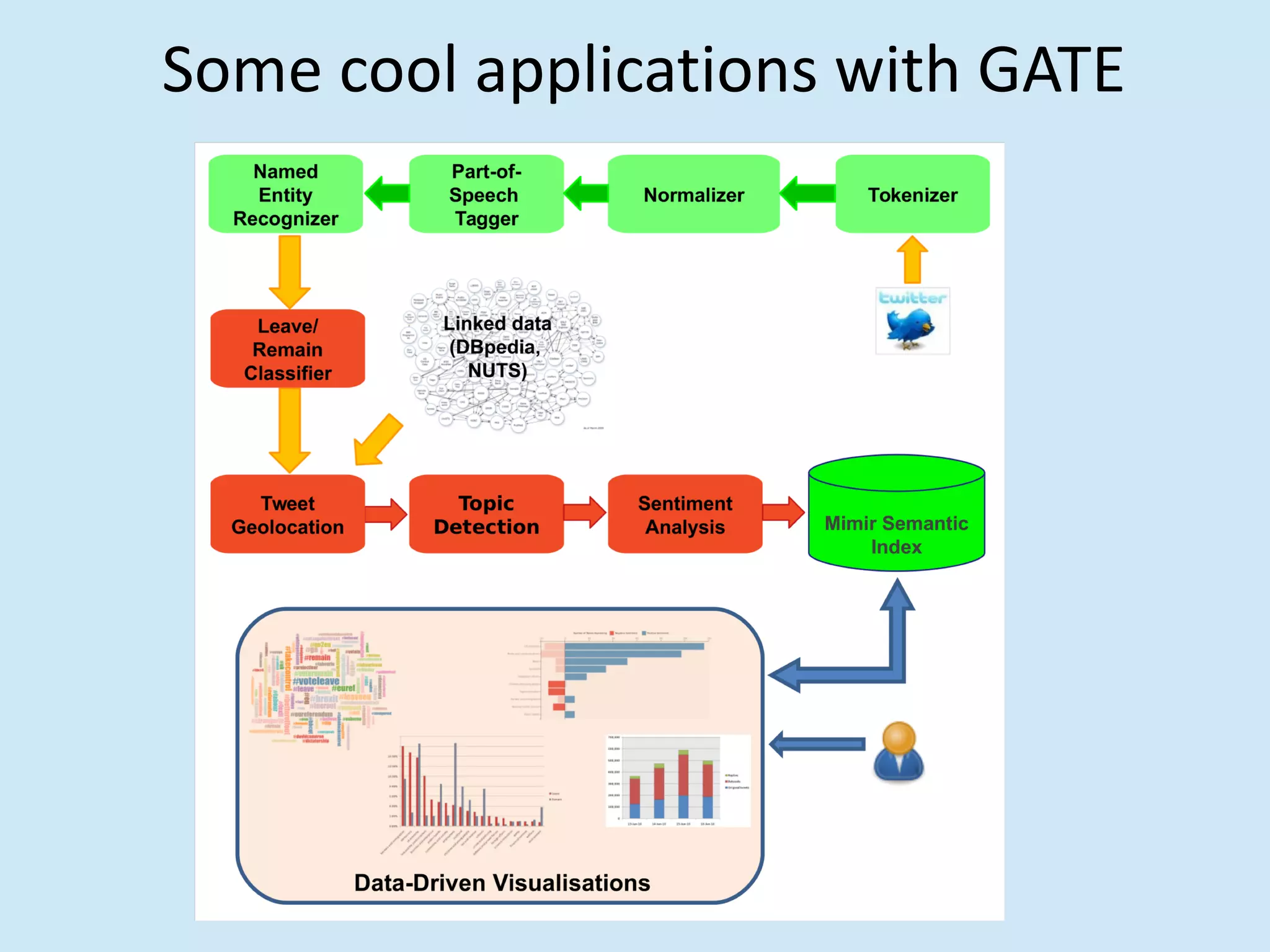



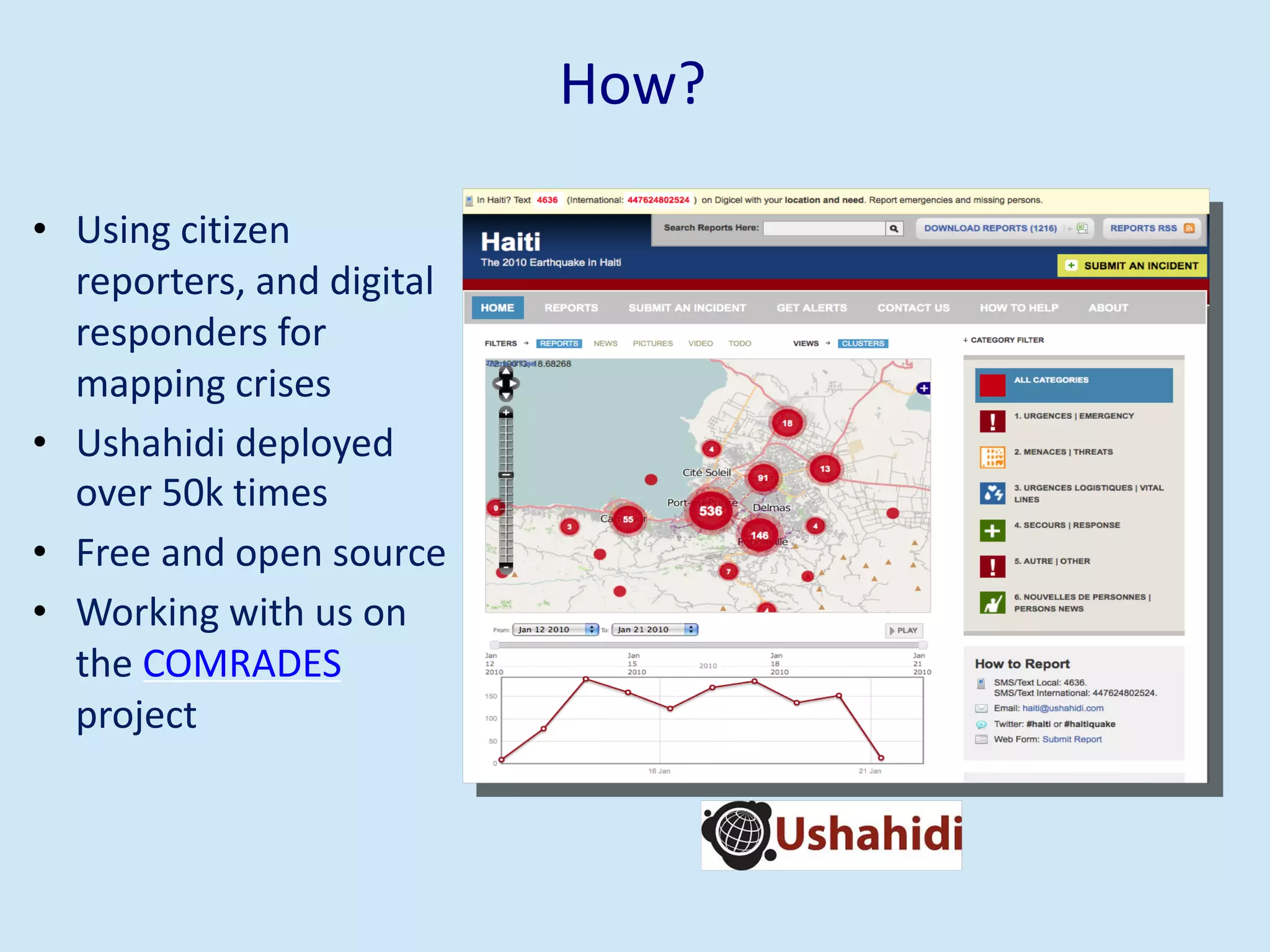
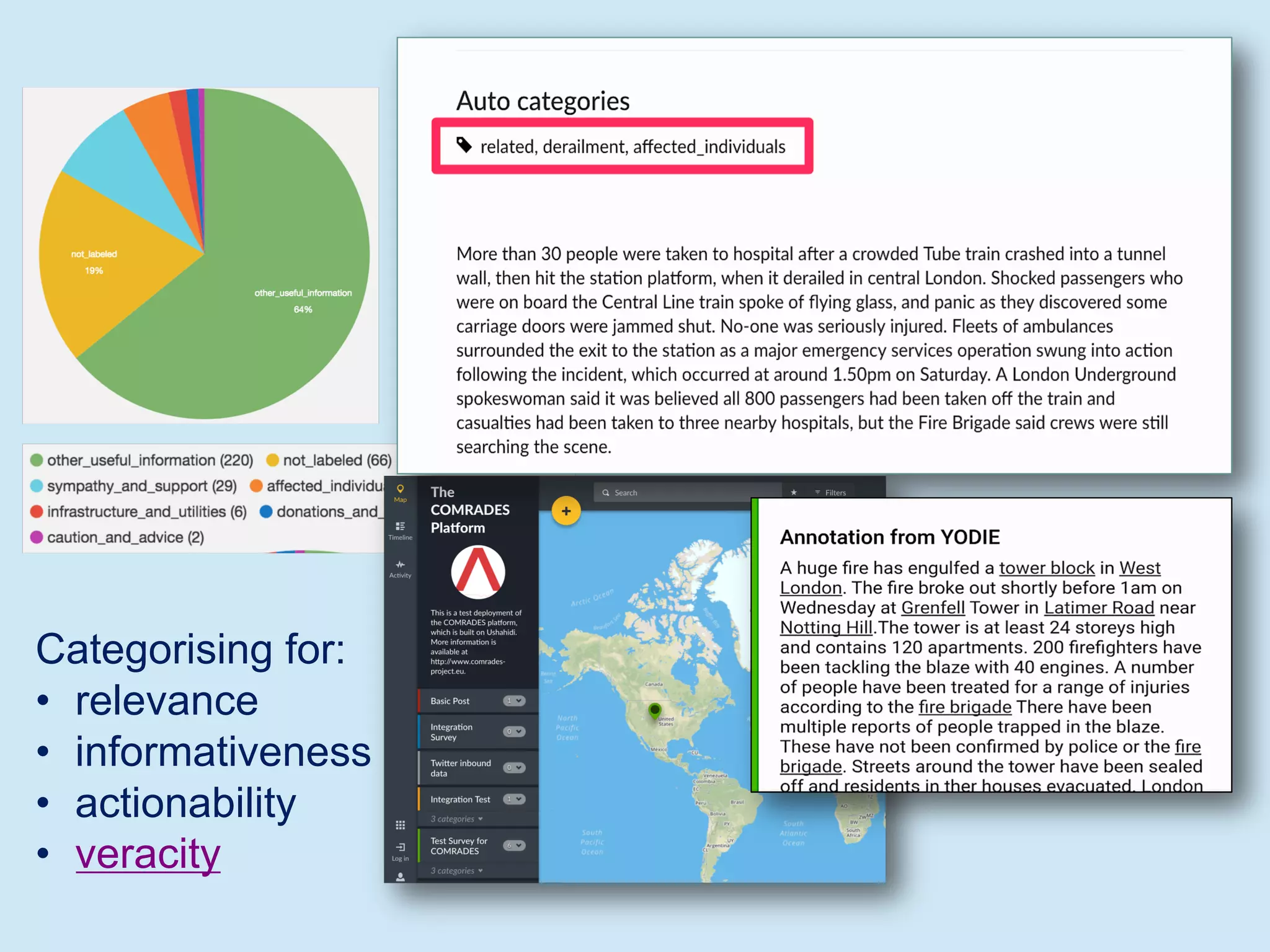




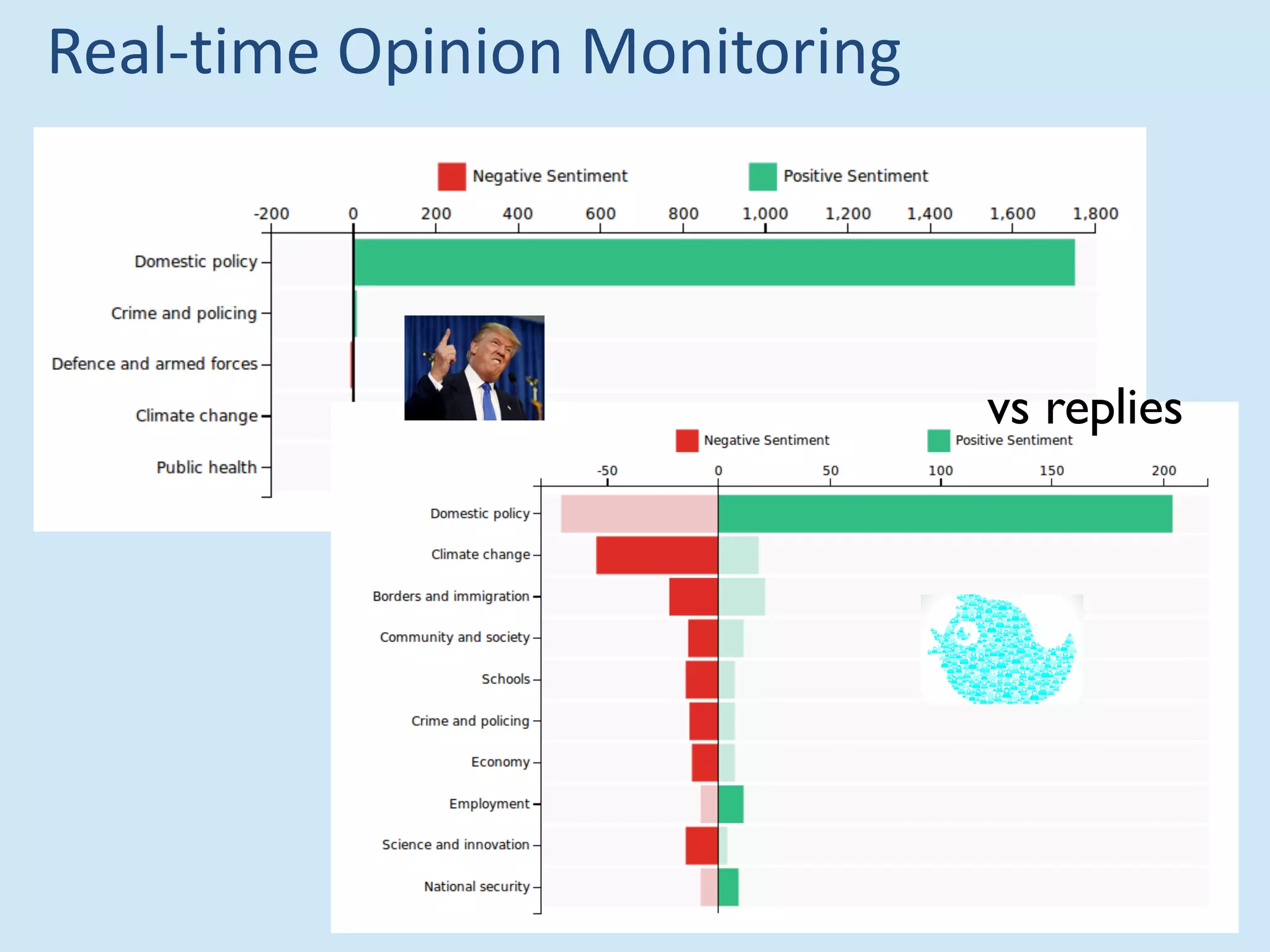

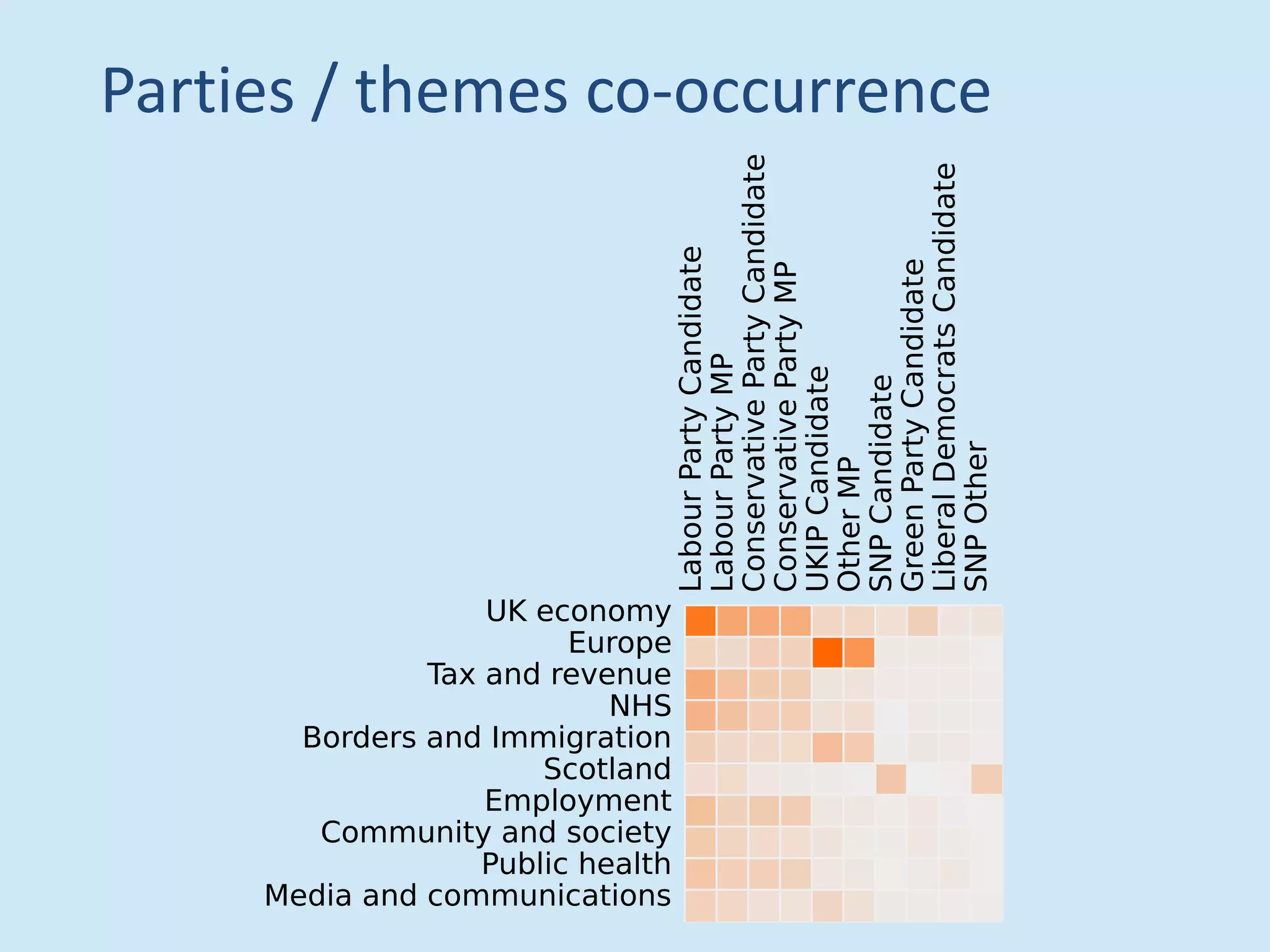



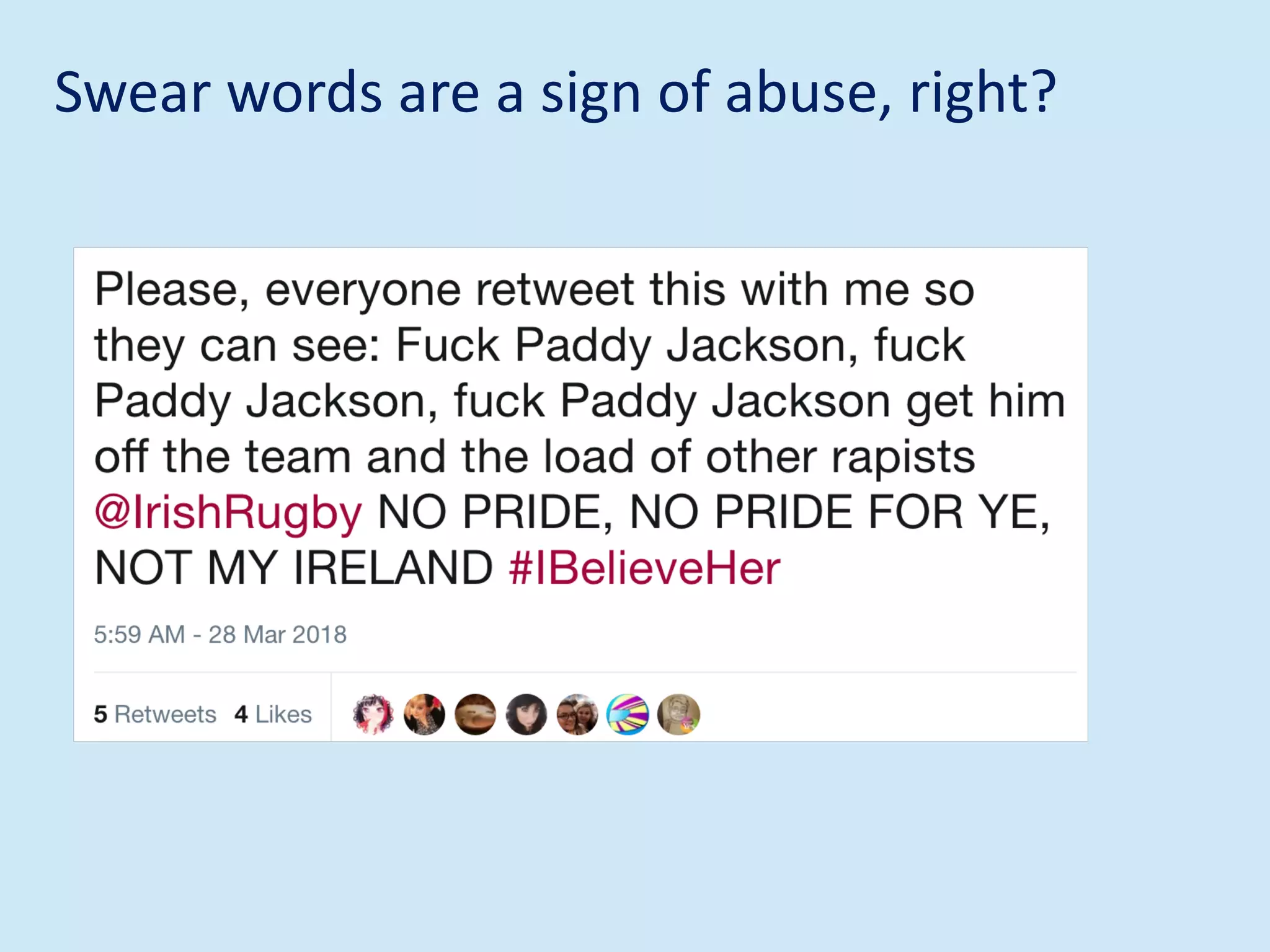






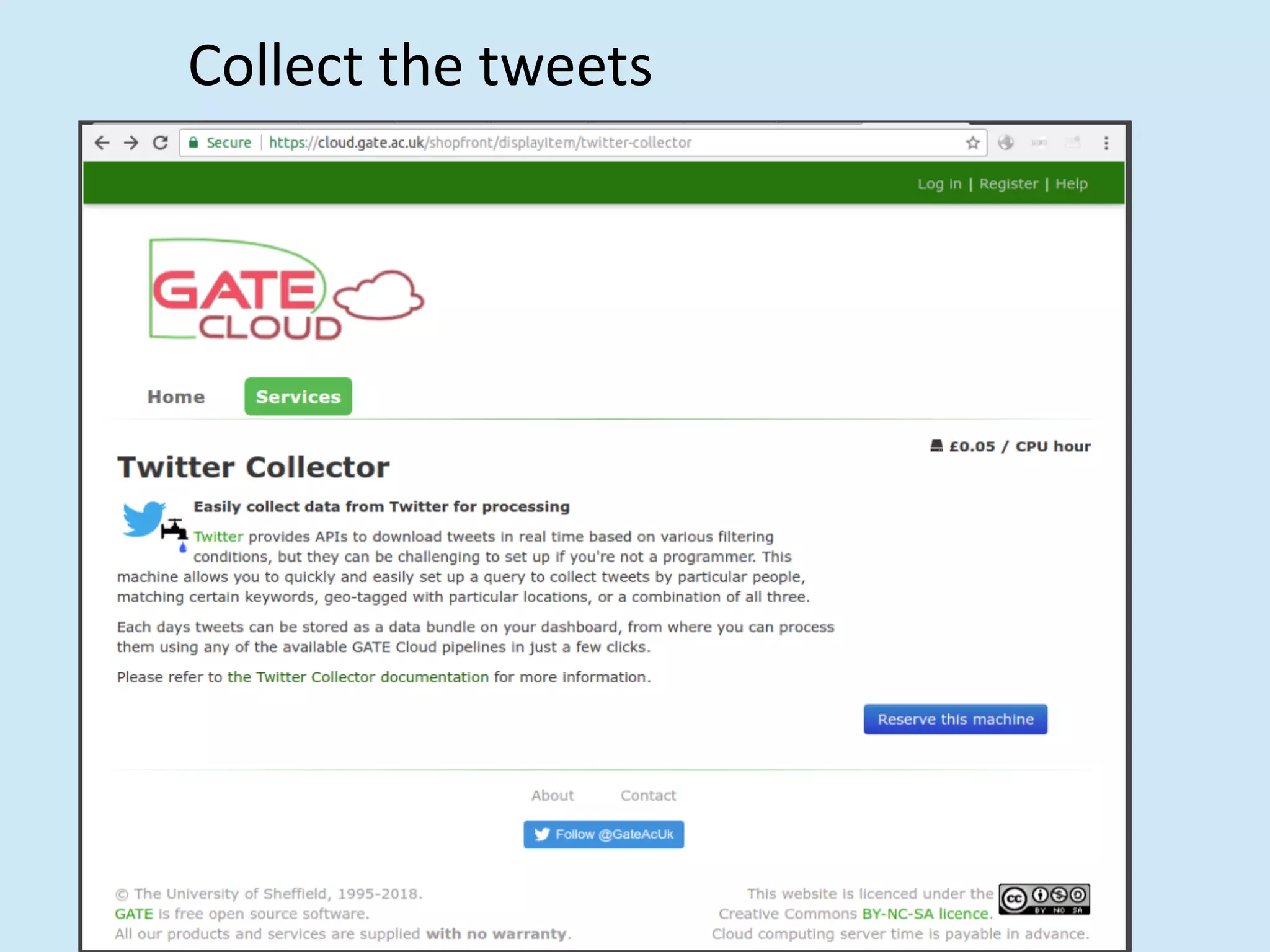
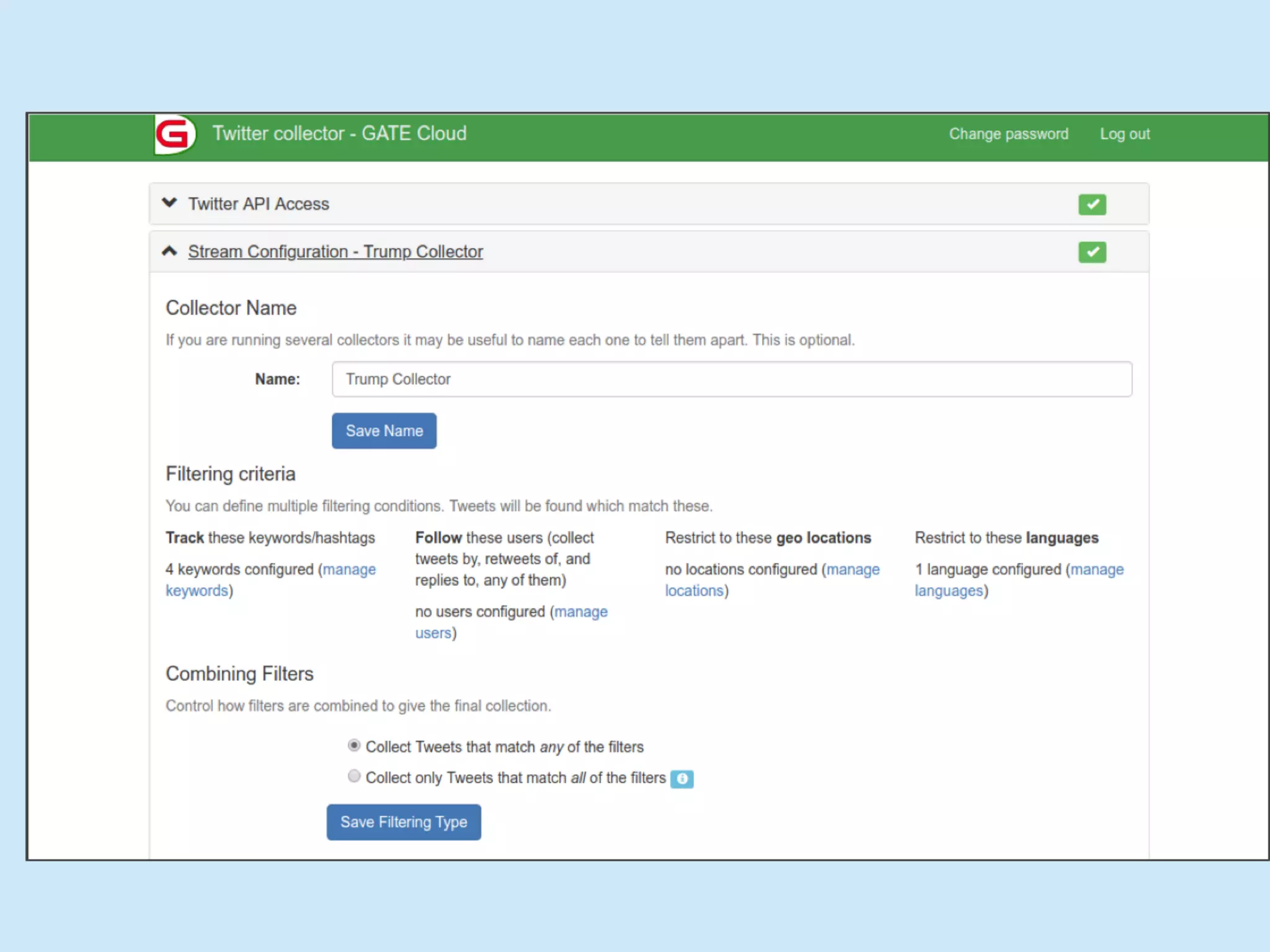
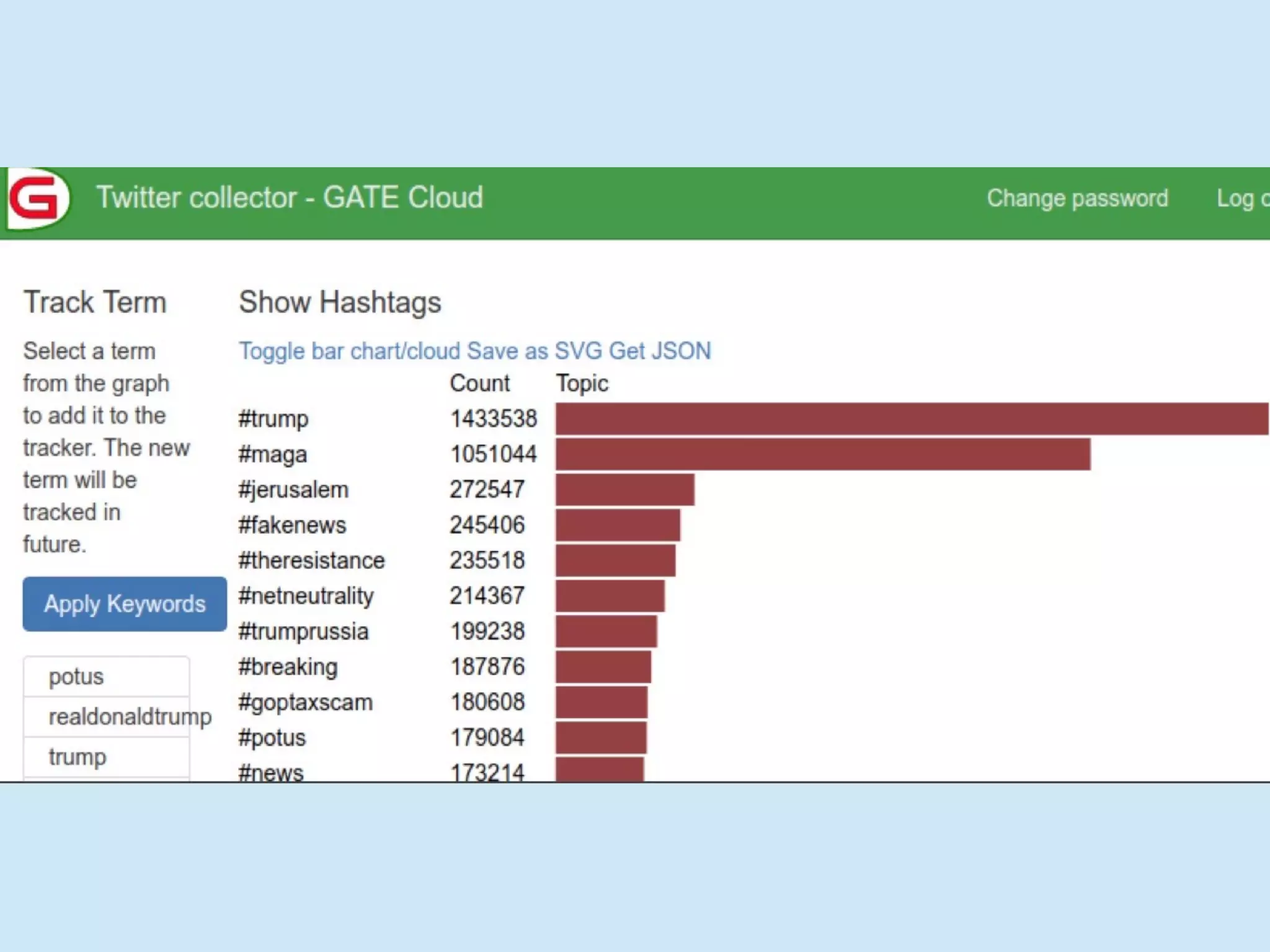

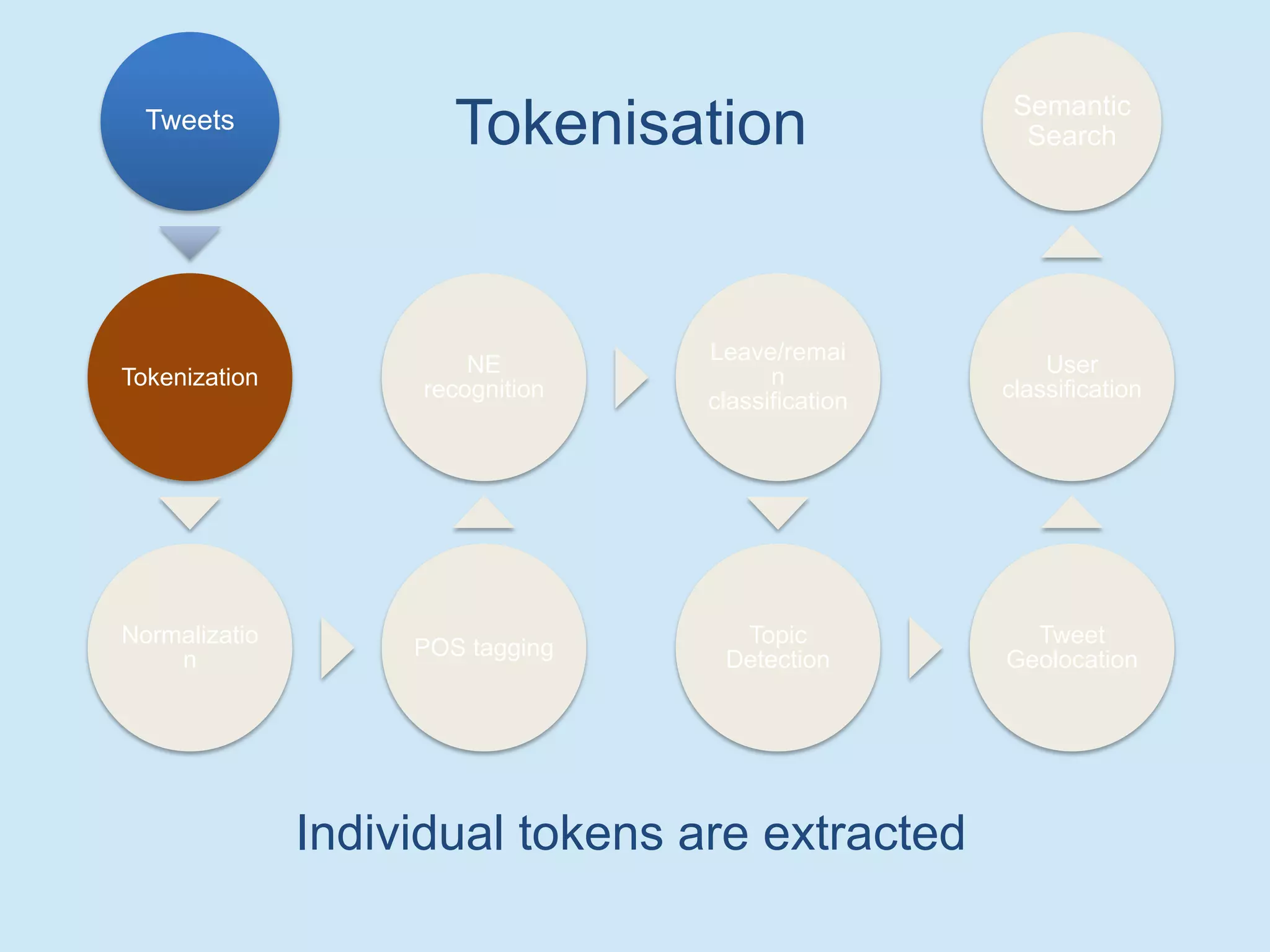


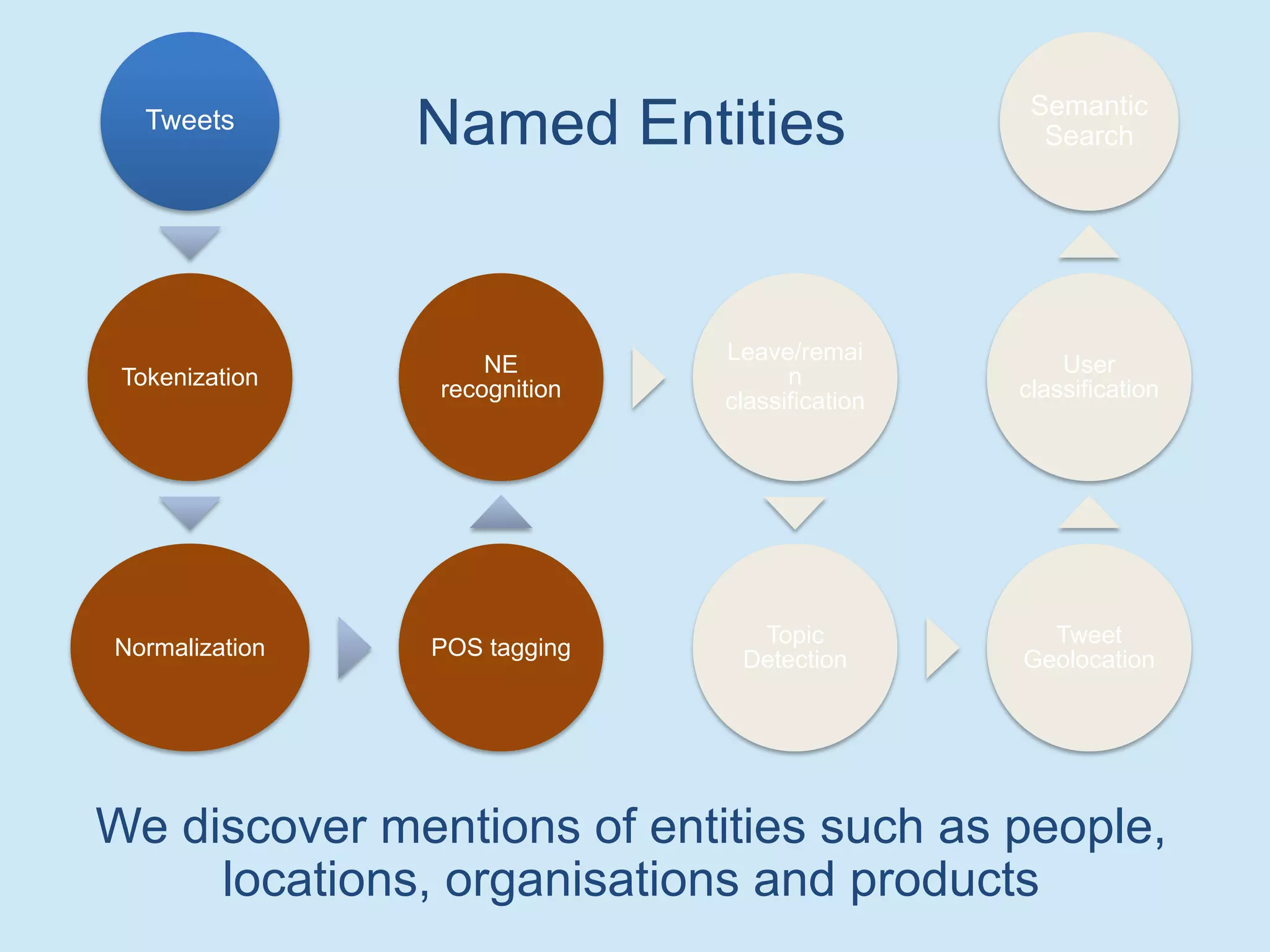
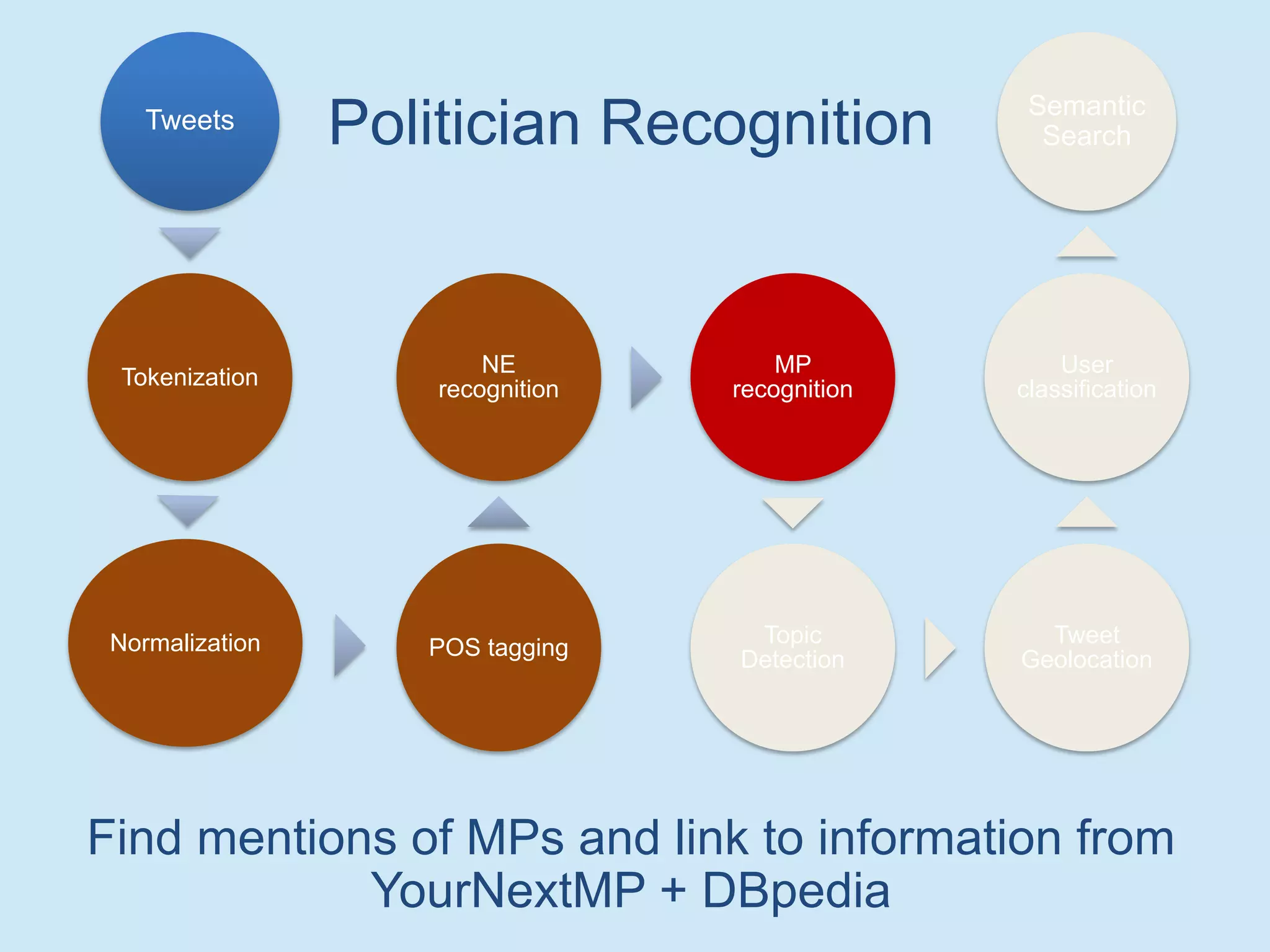
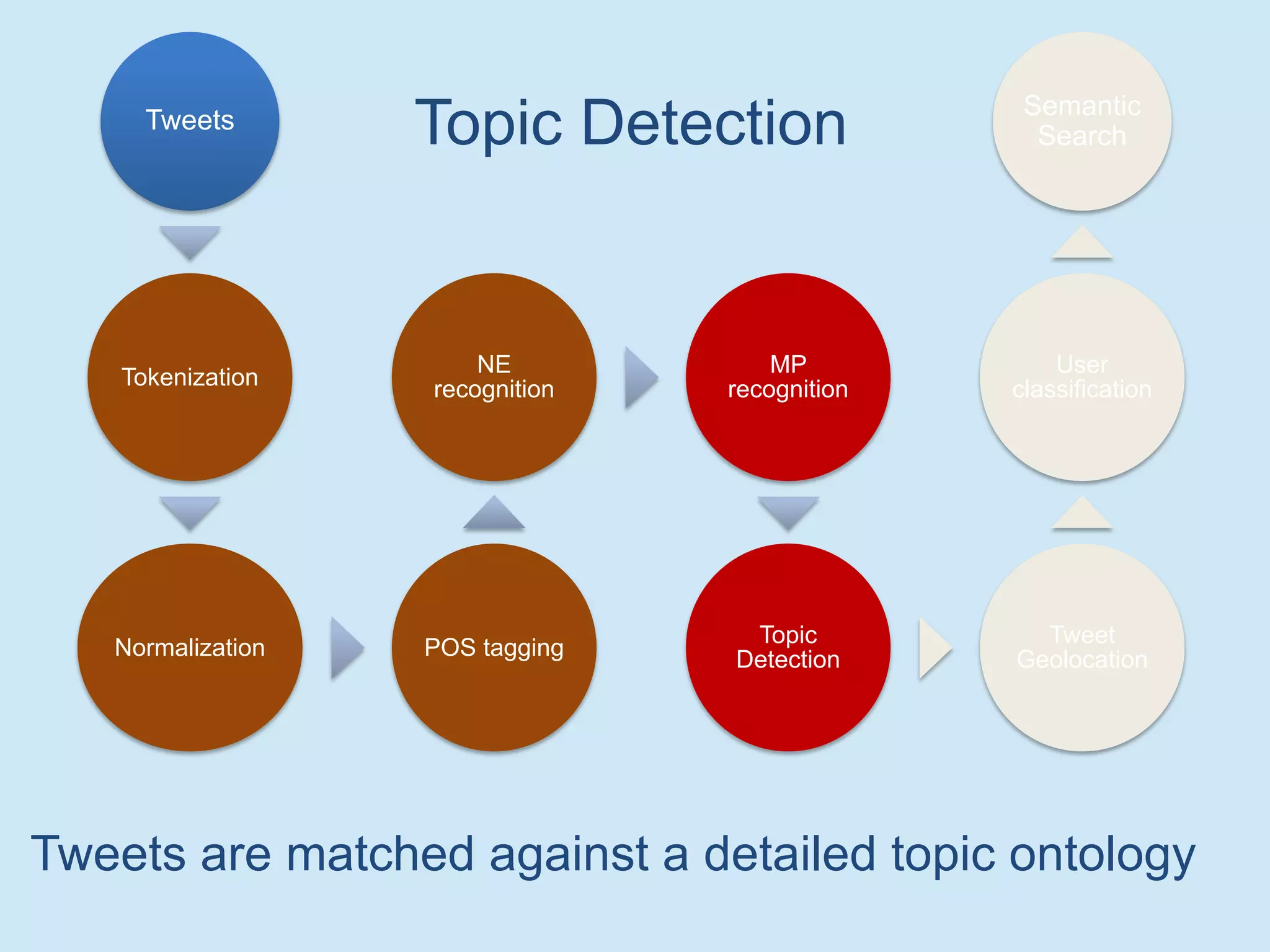
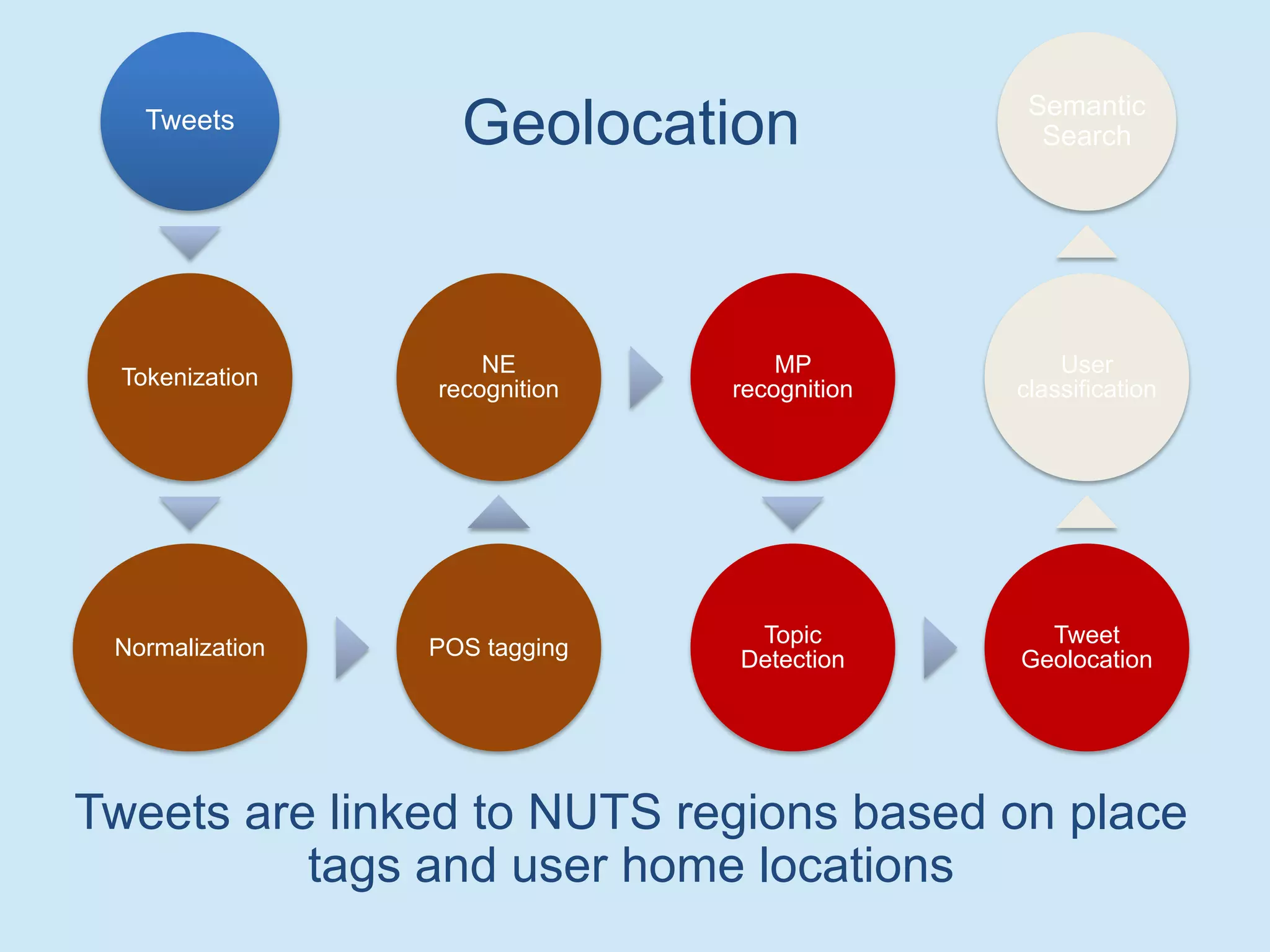
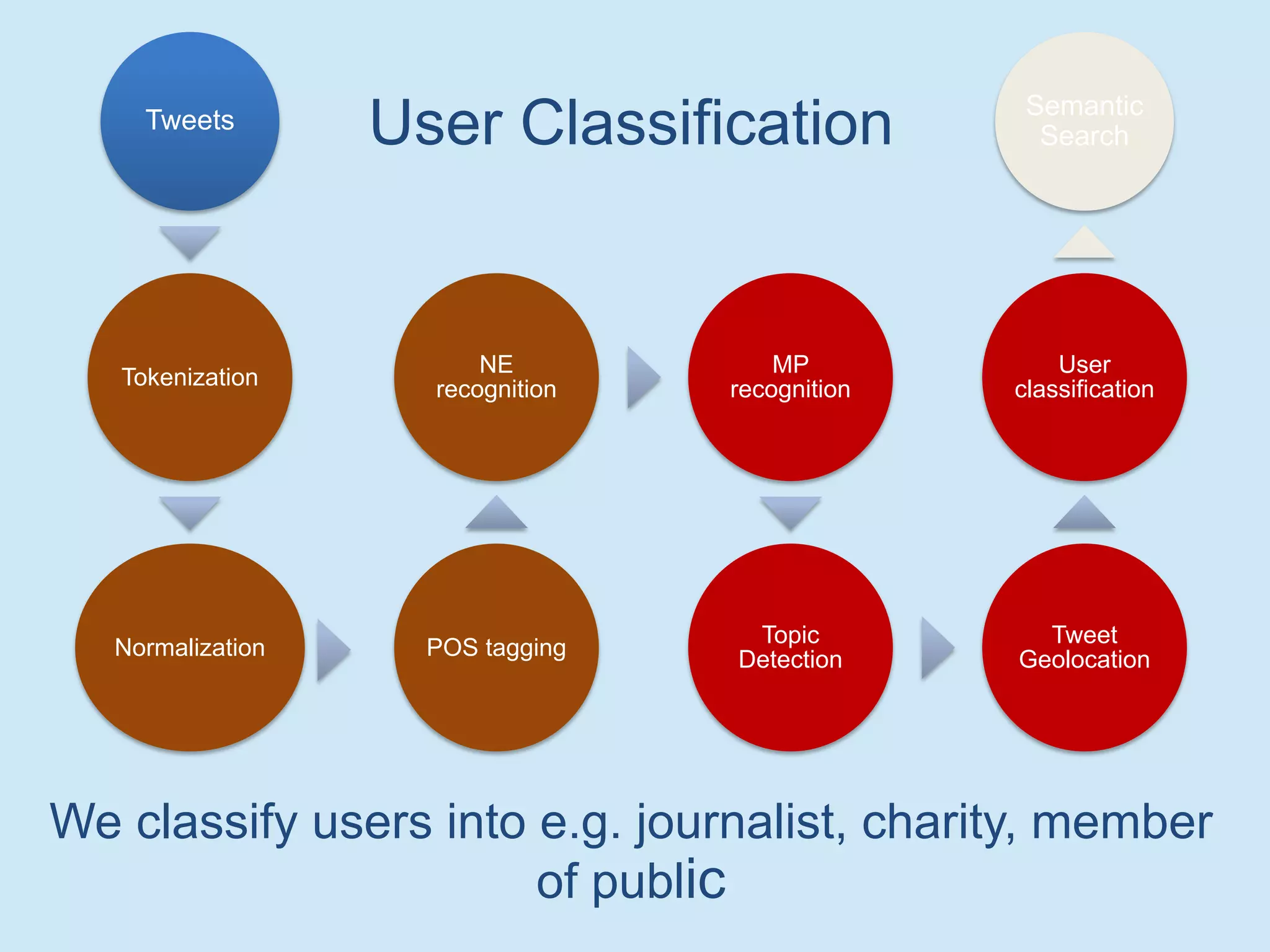
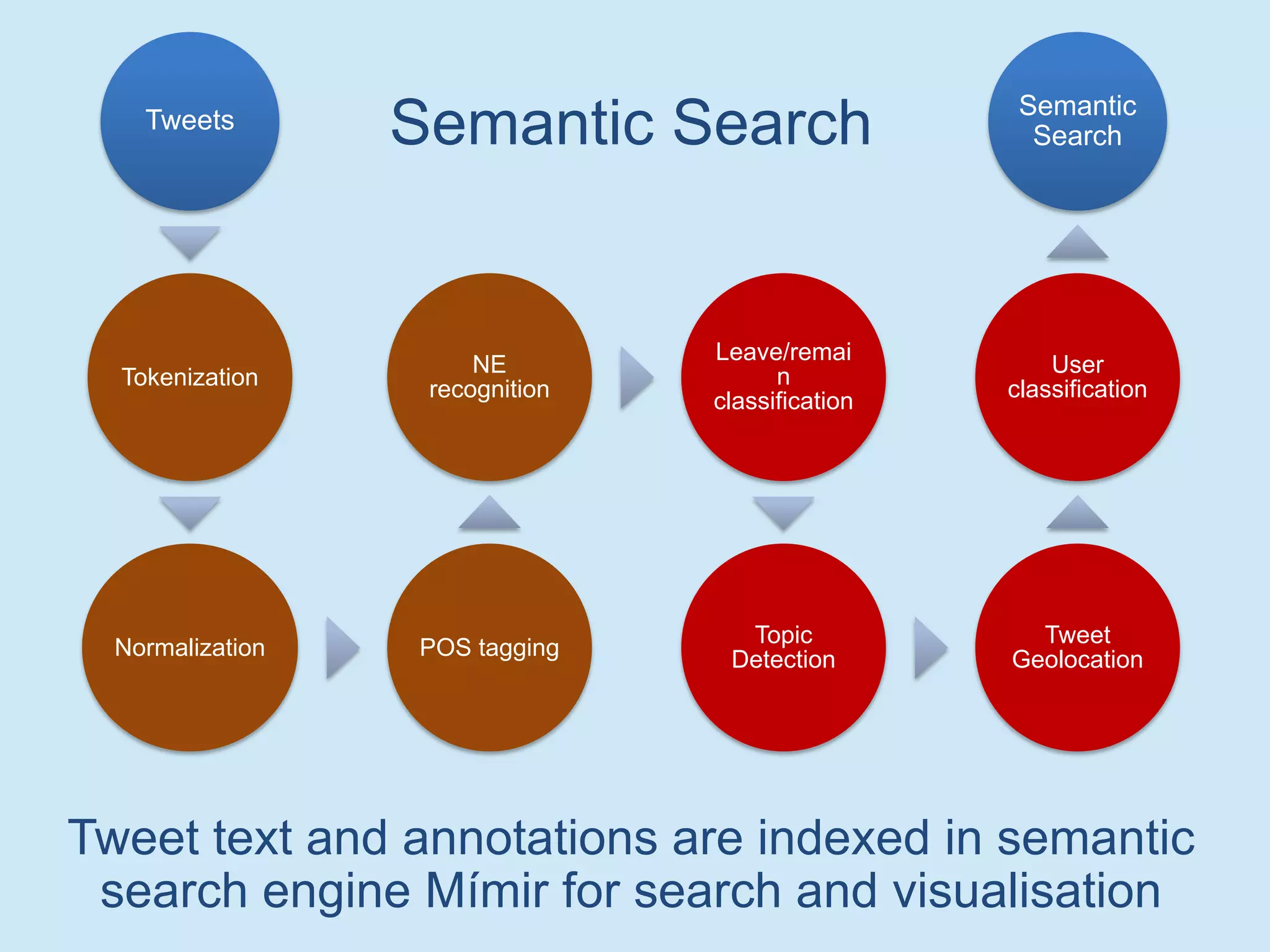
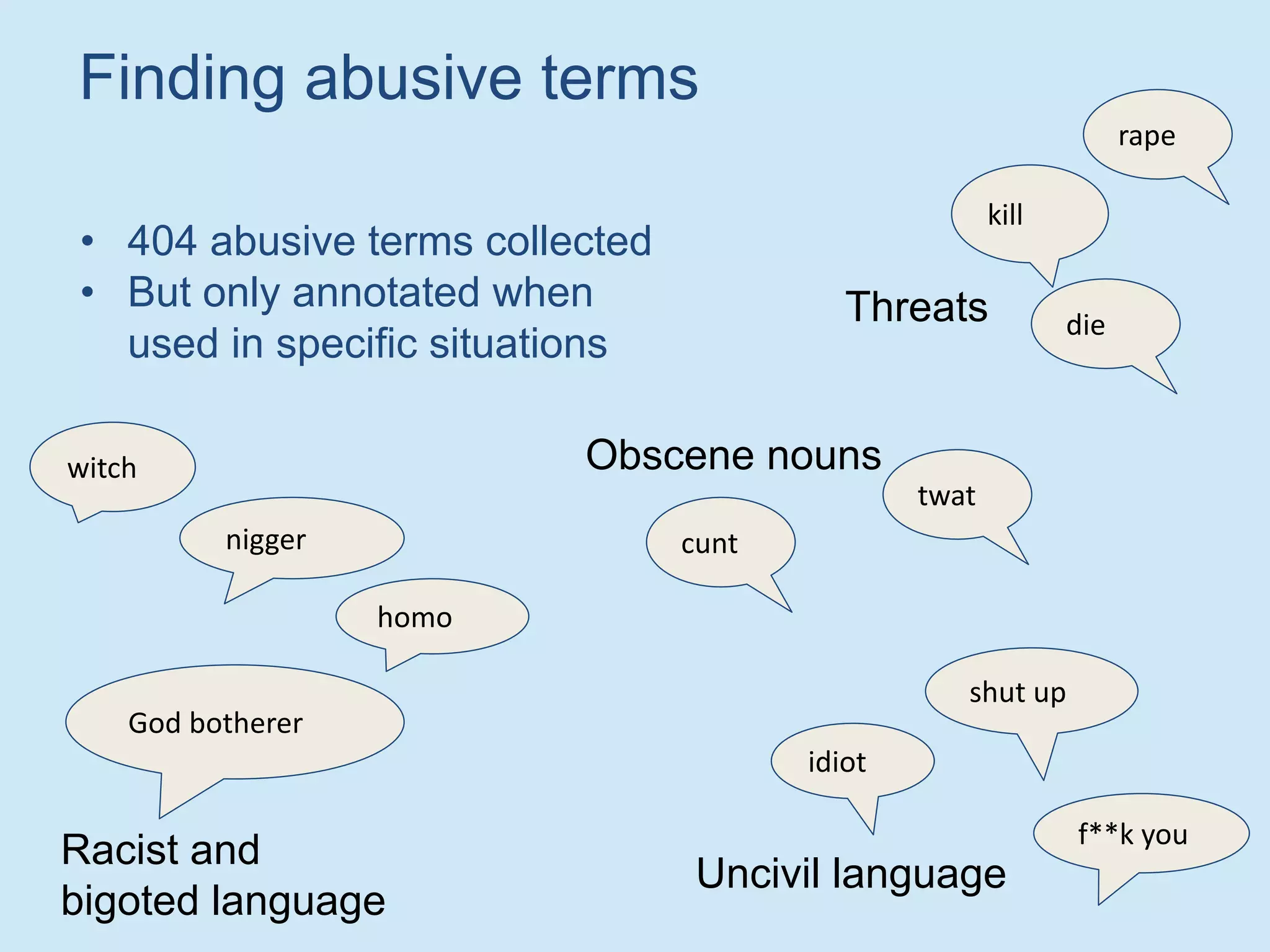
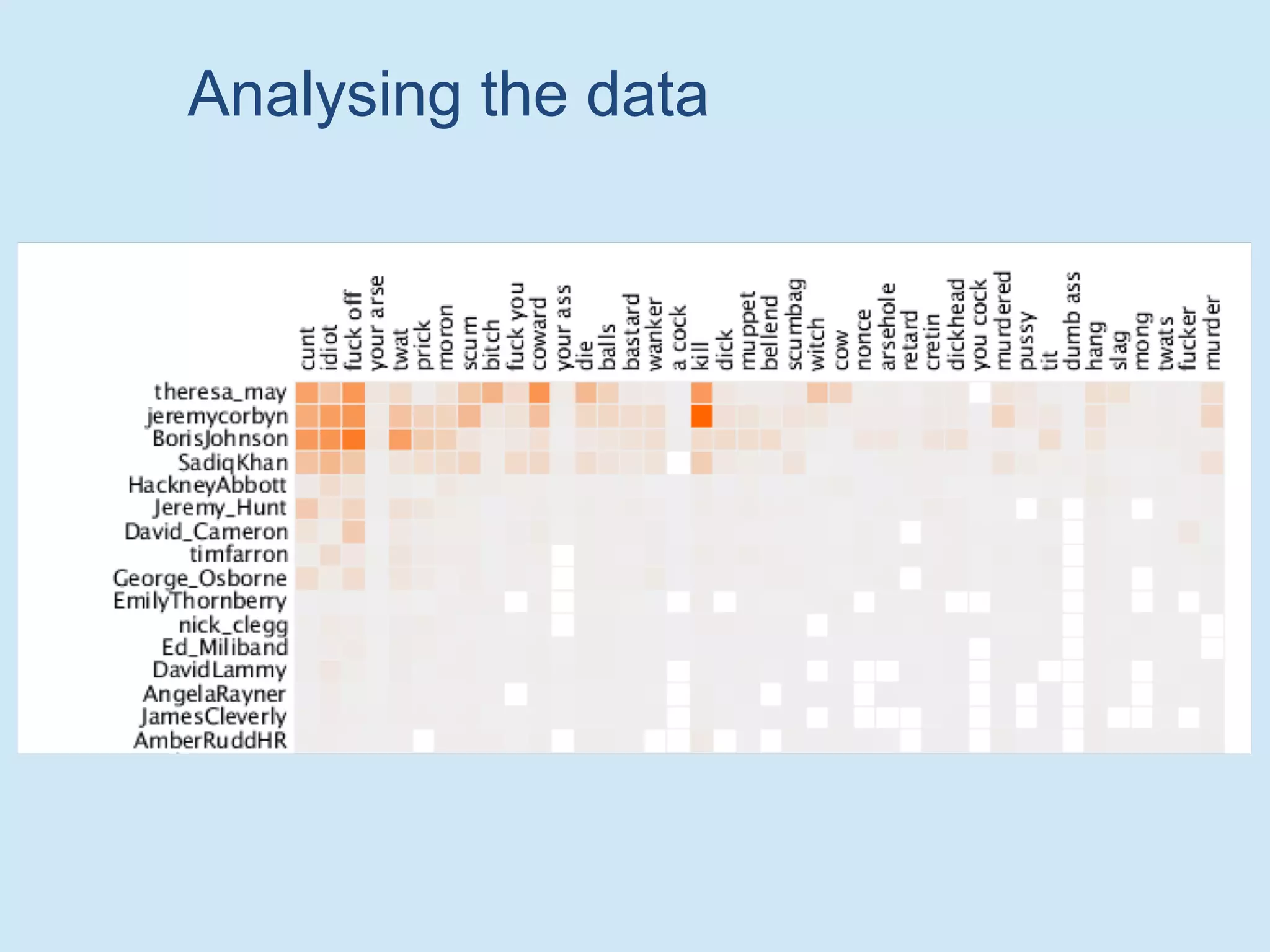
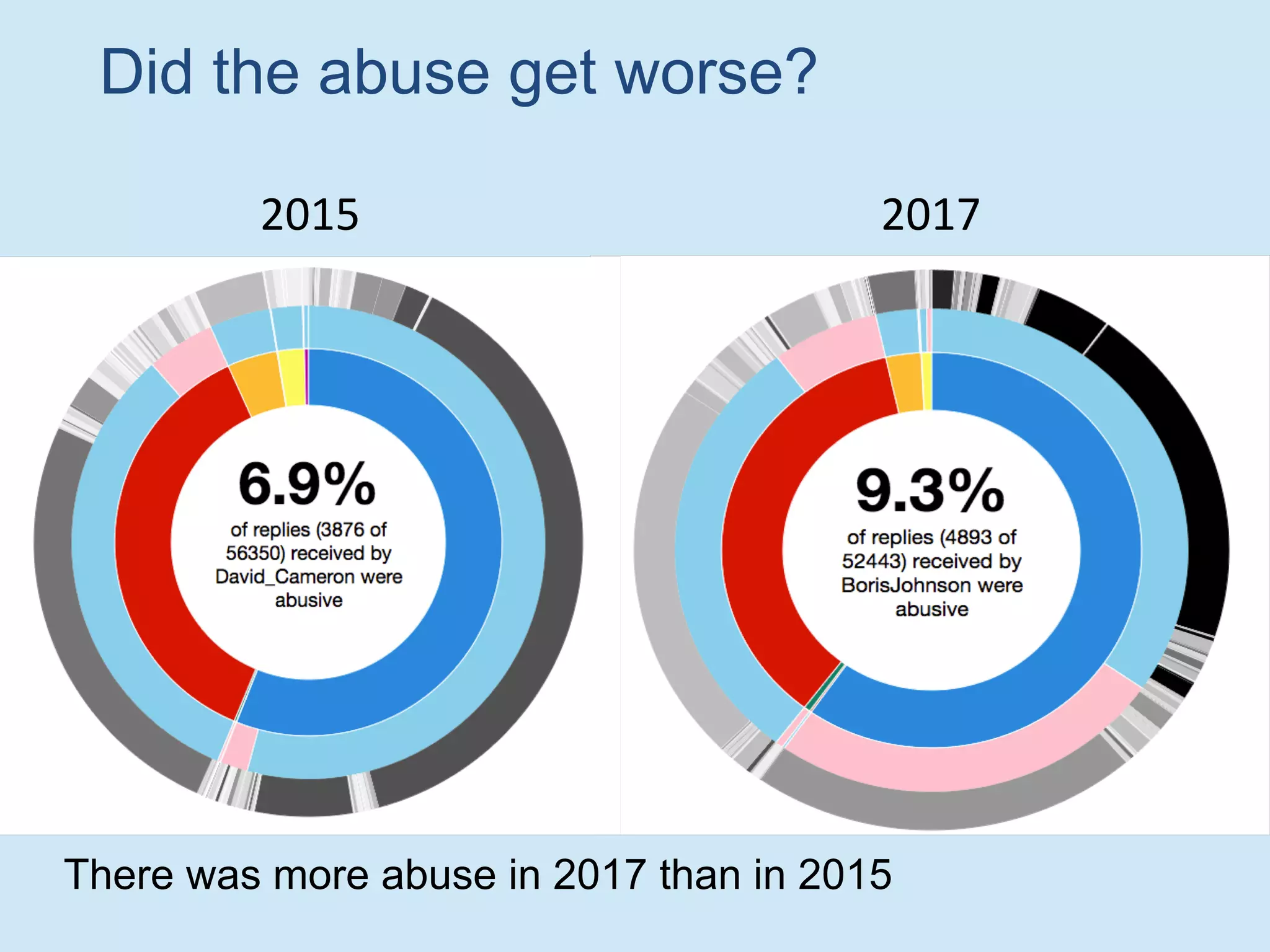
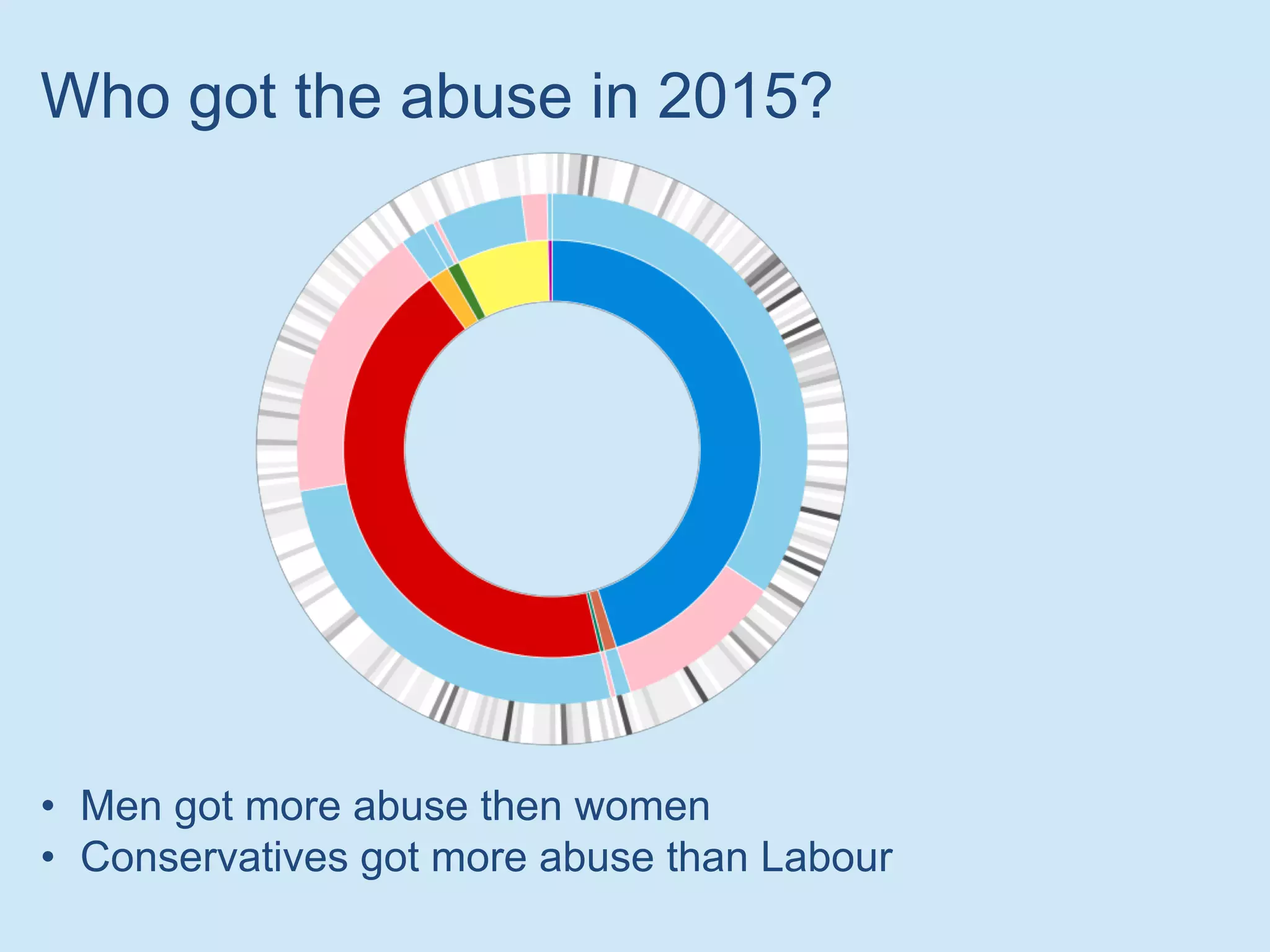
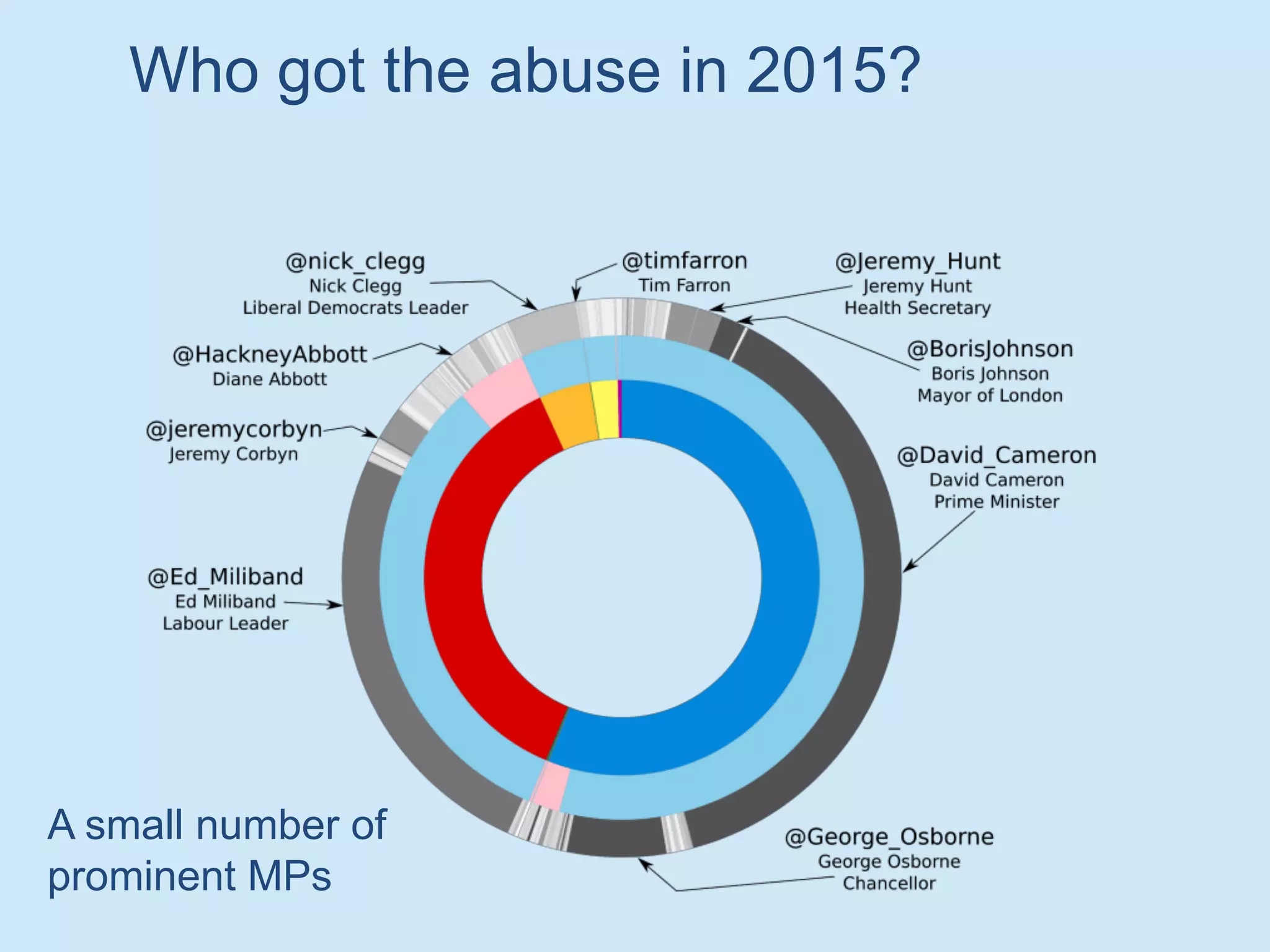
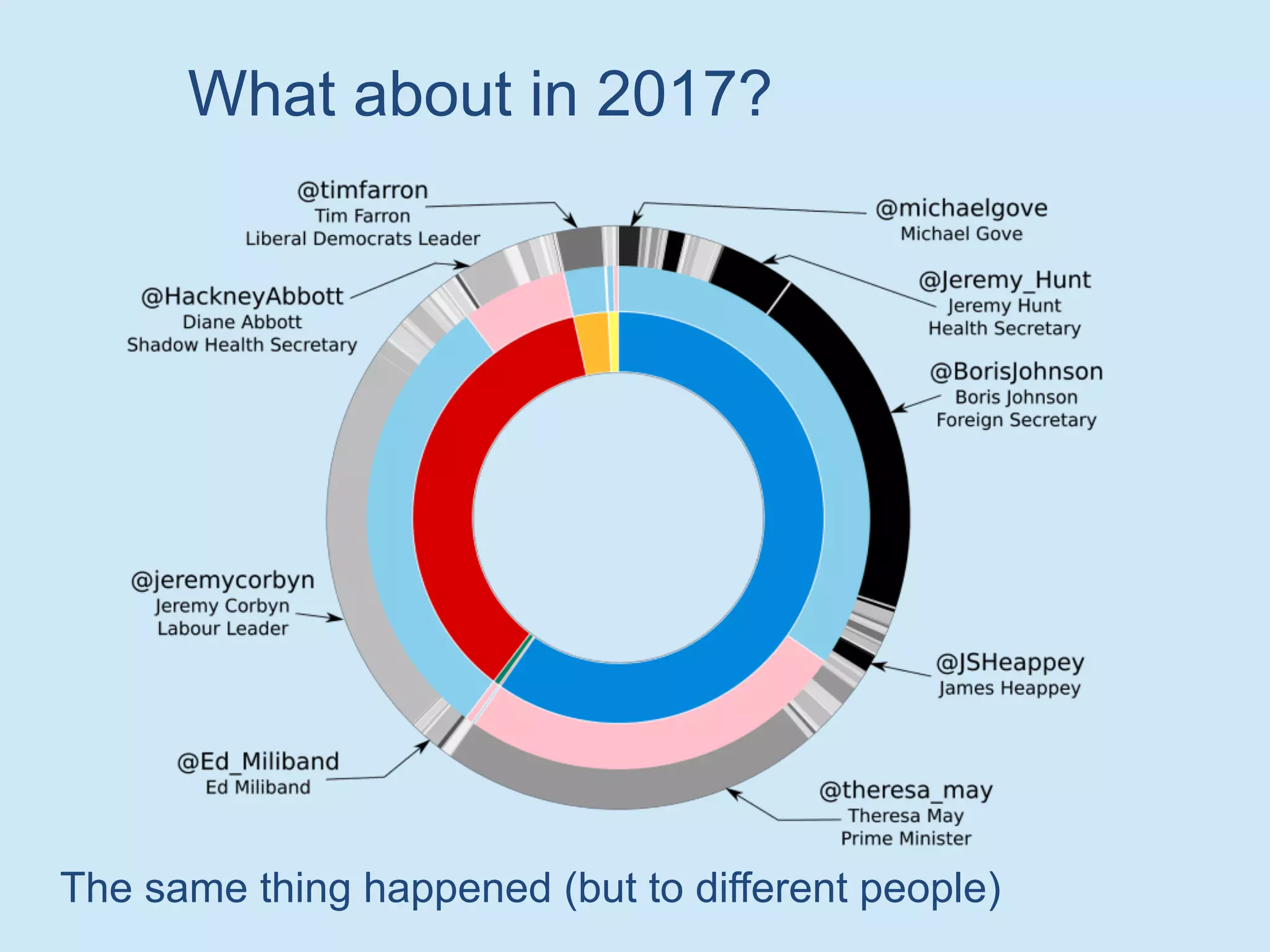
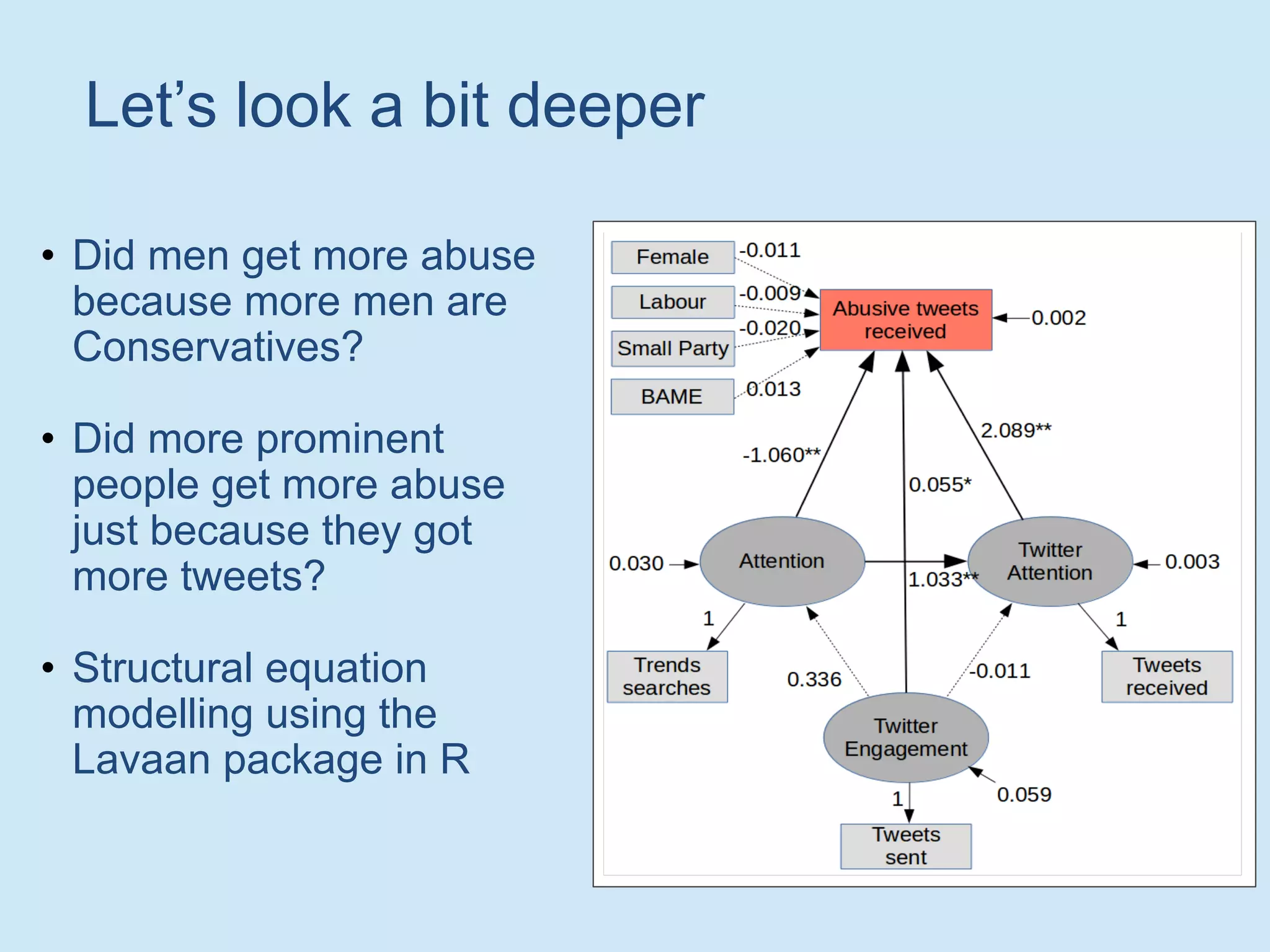






The document discusses analyzing social media data, particularly tweets, for natural language processing tasks. It provides examples of analyzing tweets to understand information sharing during disasters, monitor opinions in real-time, detect topics and analyze political discussions. It also discusses challenges in analyzing tweets like informal language, ambiguity and misleading contexts or hashtags. Precise information extraction and annotation of tweets is needed to accurately identify hate speech, abuse and analyze its targets and changes over time. A multi-step pipeline including collection, preprocessing, information extraction and classification is proposed to understand abuse toward politicians from tweets surrounding UK elections.














































































