Download as PDF, PPTX





![Controlling Instances
root@node1:~# gnt-instance start instance1
Waiting for job 10 for instance1.example.org ...
root@node1:~# gnt-instance console instance1
login as 'vagrant' user. default password: 'vagrant'. use 'sudo' for root.
cirros login:
# Press crtl+] to escape console.
root@node1:~# gnt-instance shutdown instance1
Waiting for job 11 for instance1.example.org ...](https://image.slidesharecdn.com/ganetihands-onwalk-thrupart2-linuxcon-120902133323-phpapp02/75/Ganeti-Hands-on-Walk-thru-part-2-LinuxCon-2012-14-2048.jpg)
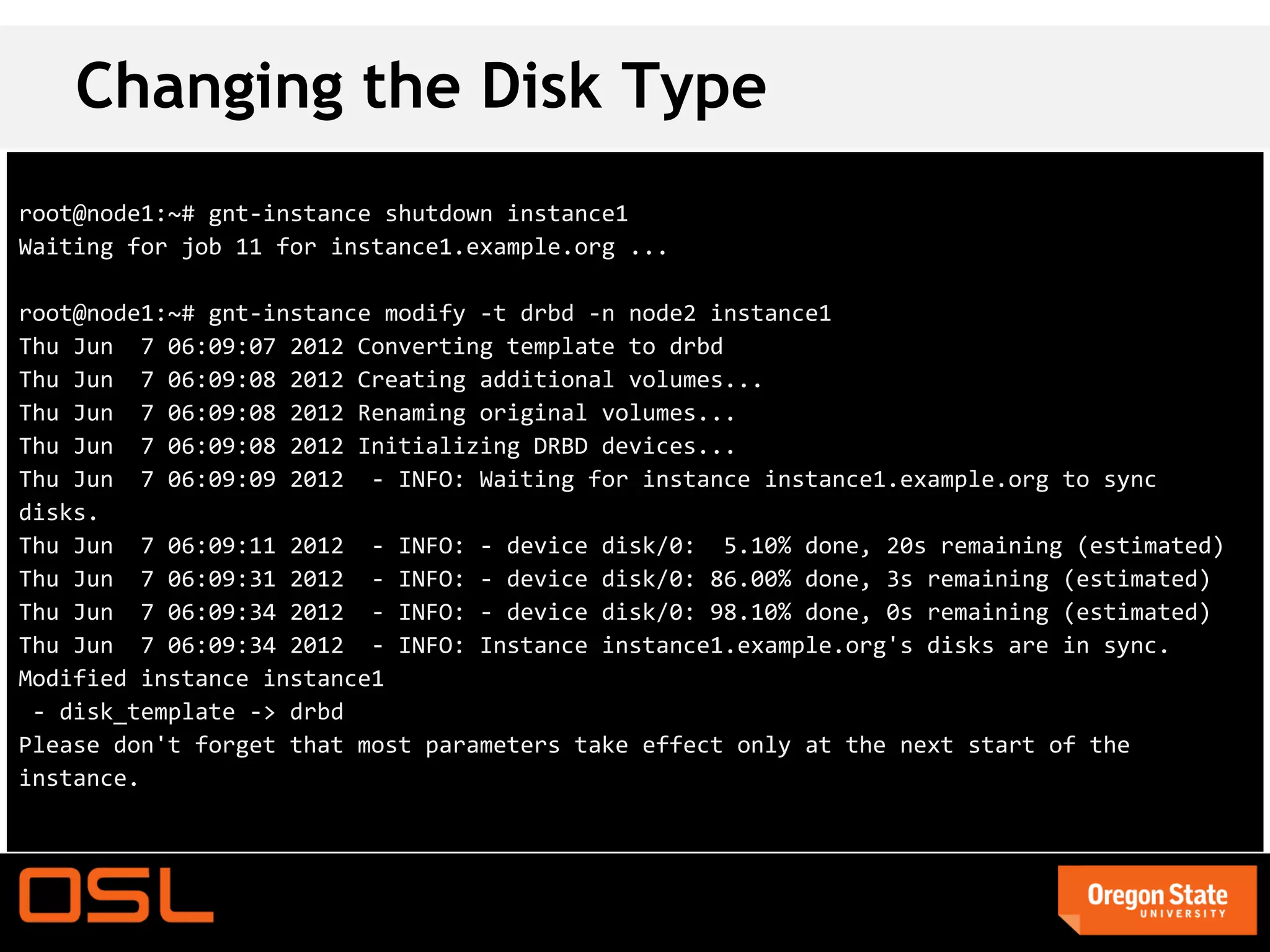
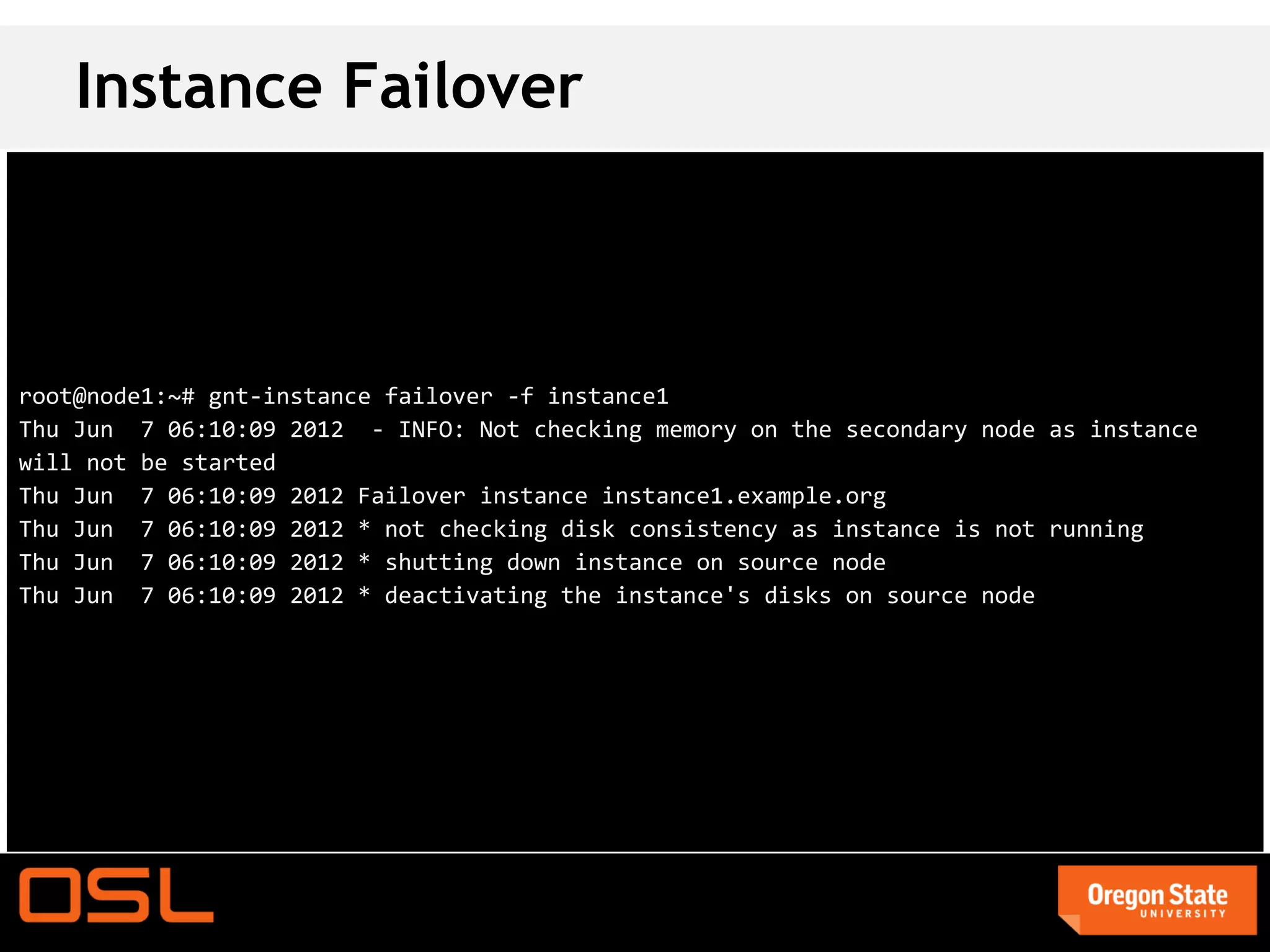
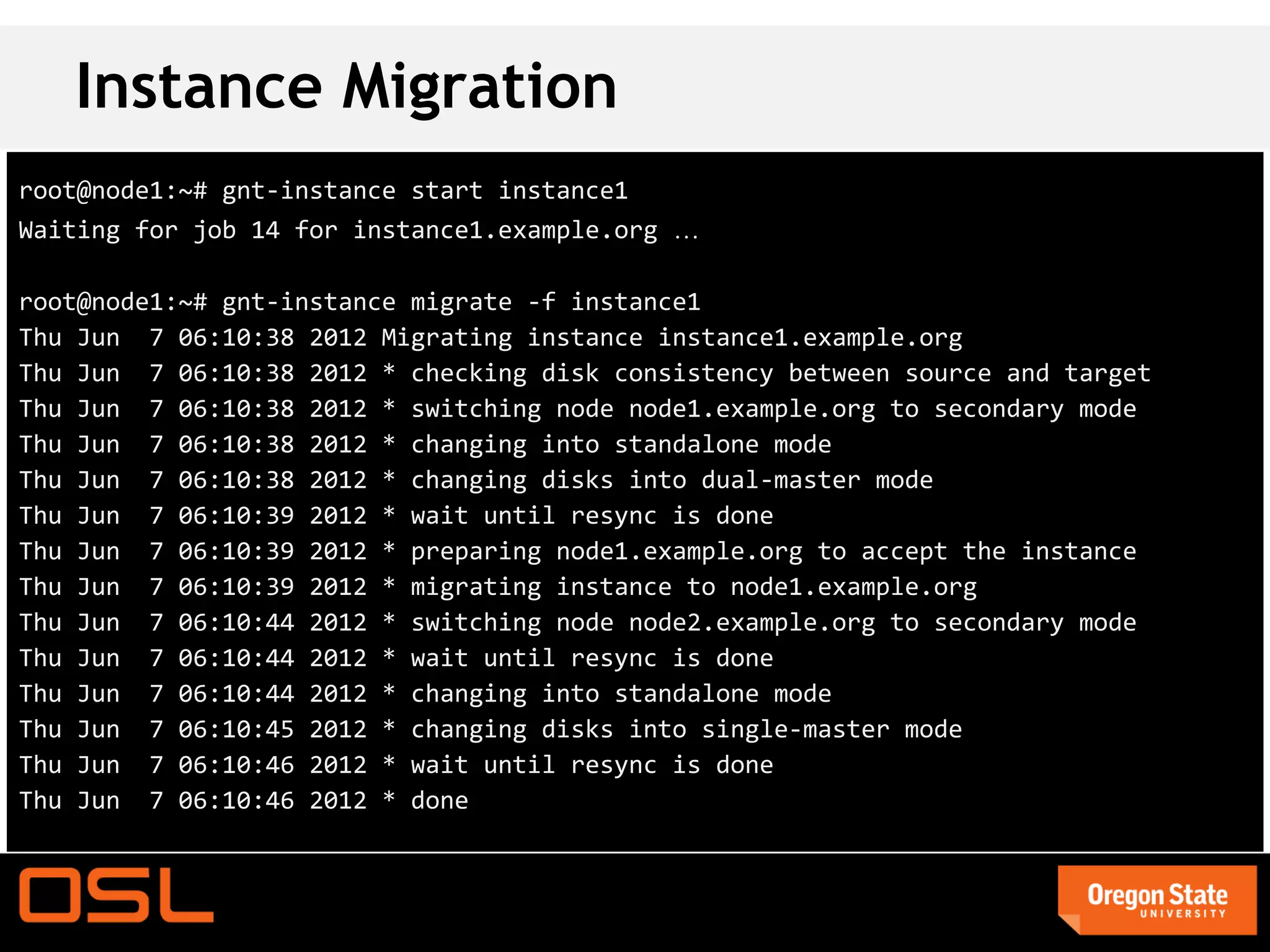
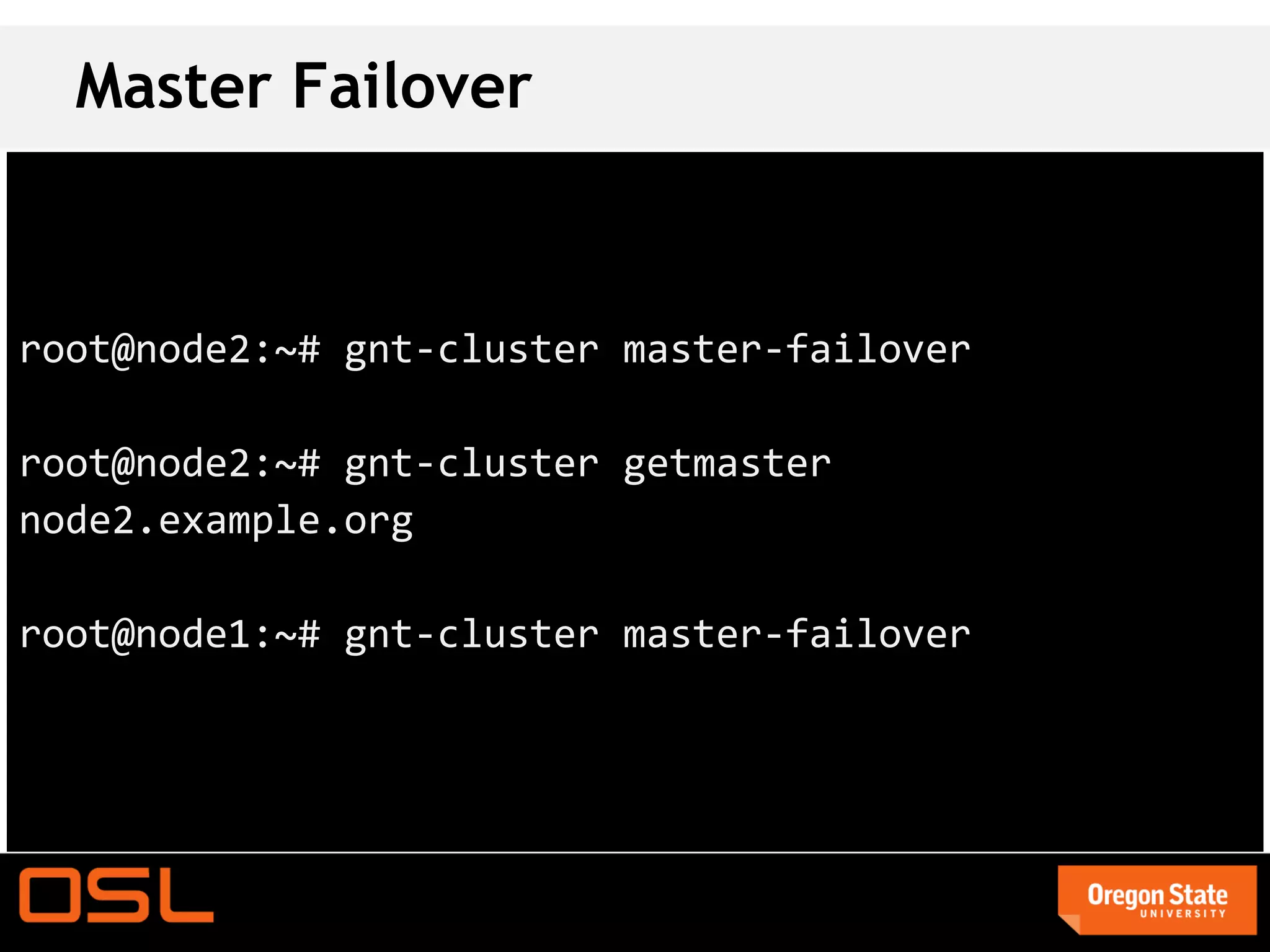
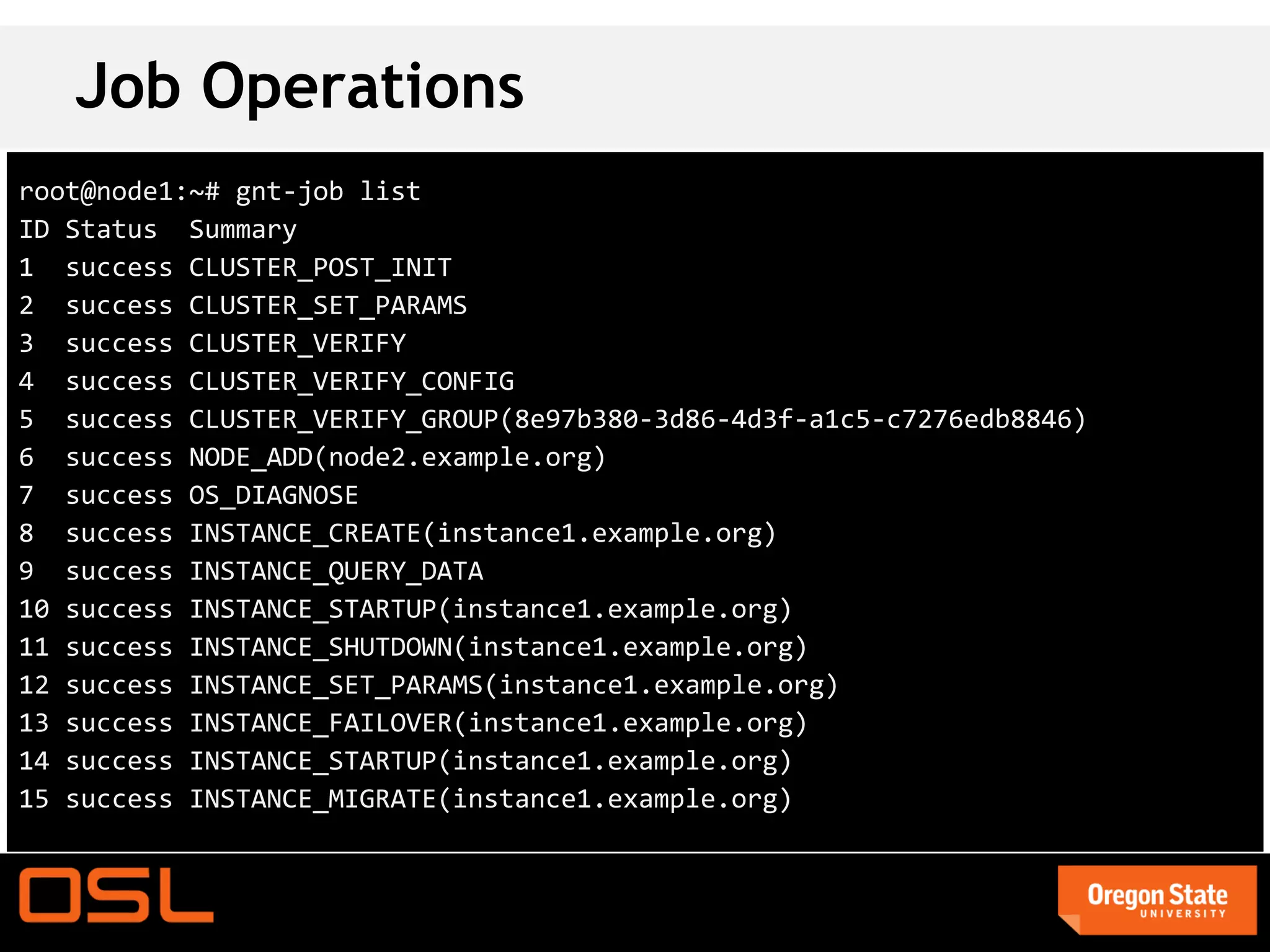
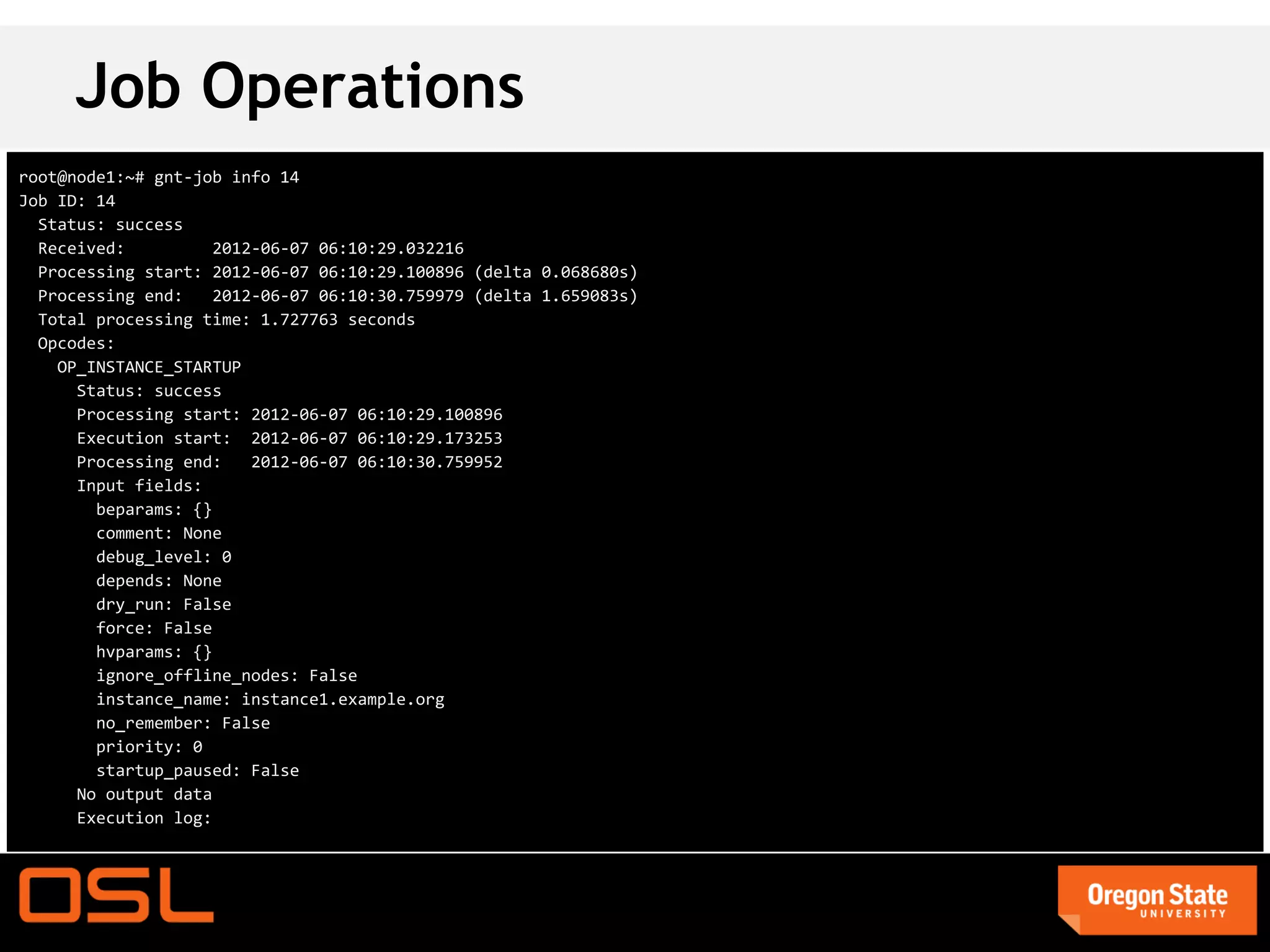
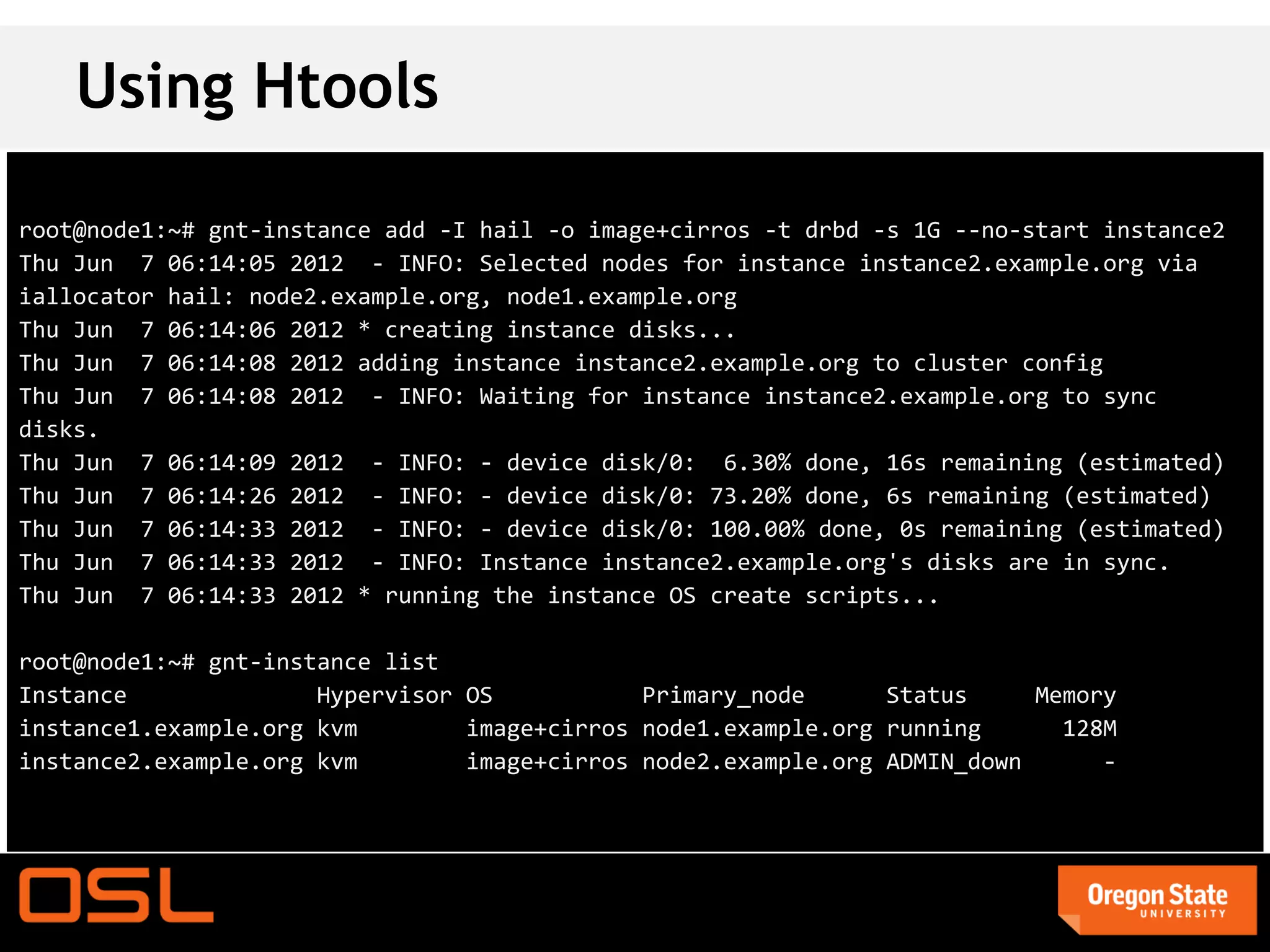
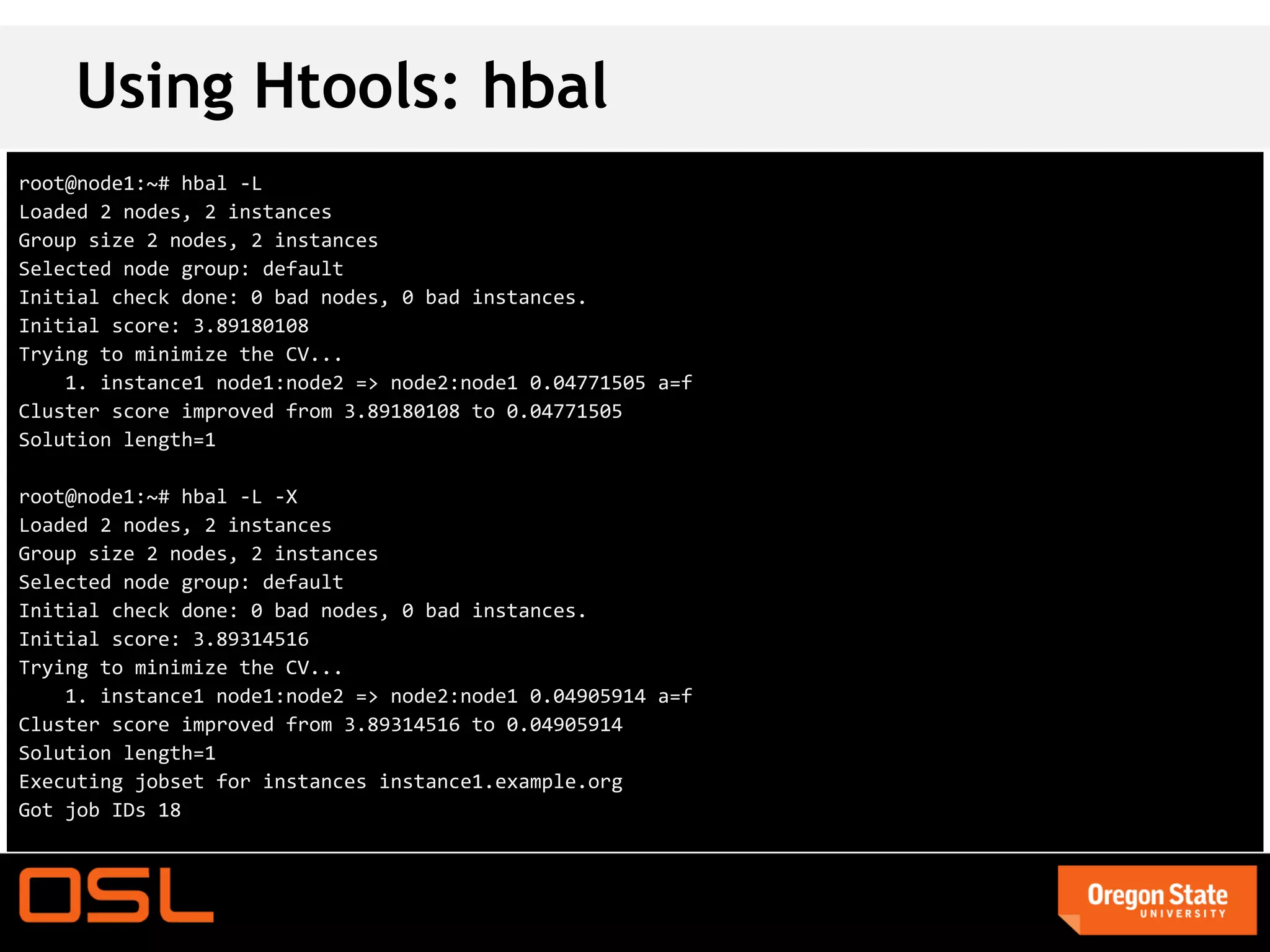
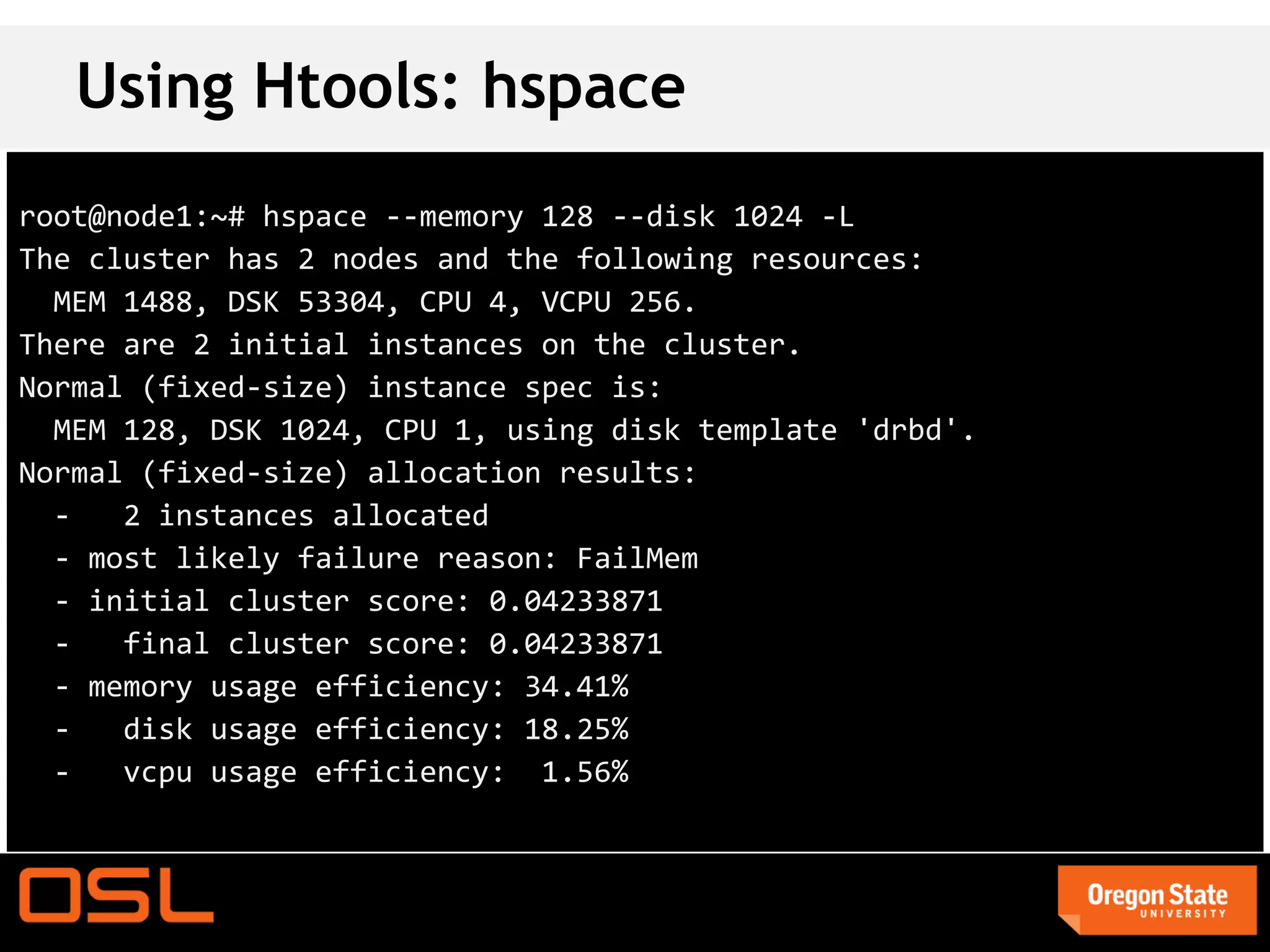
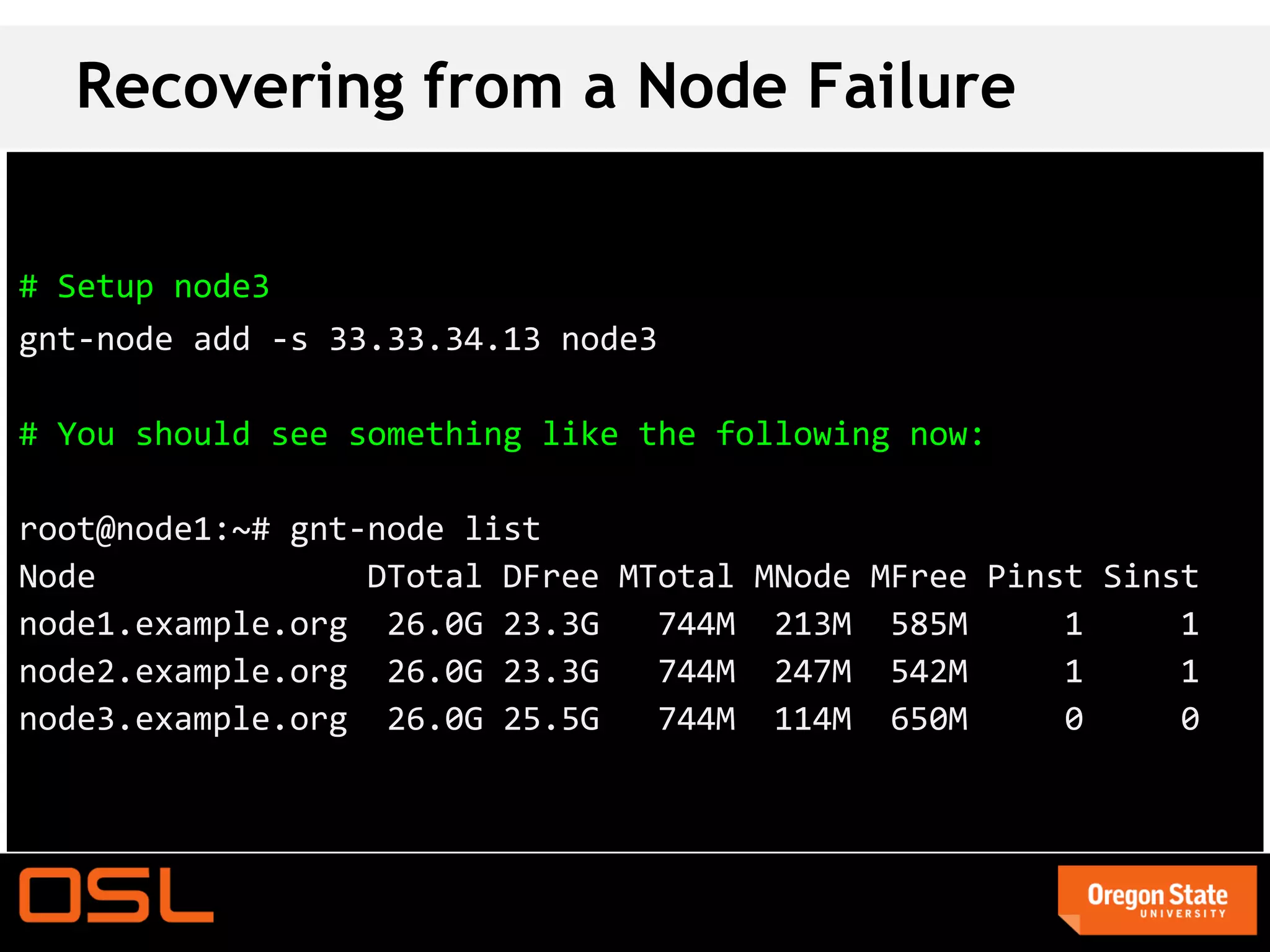
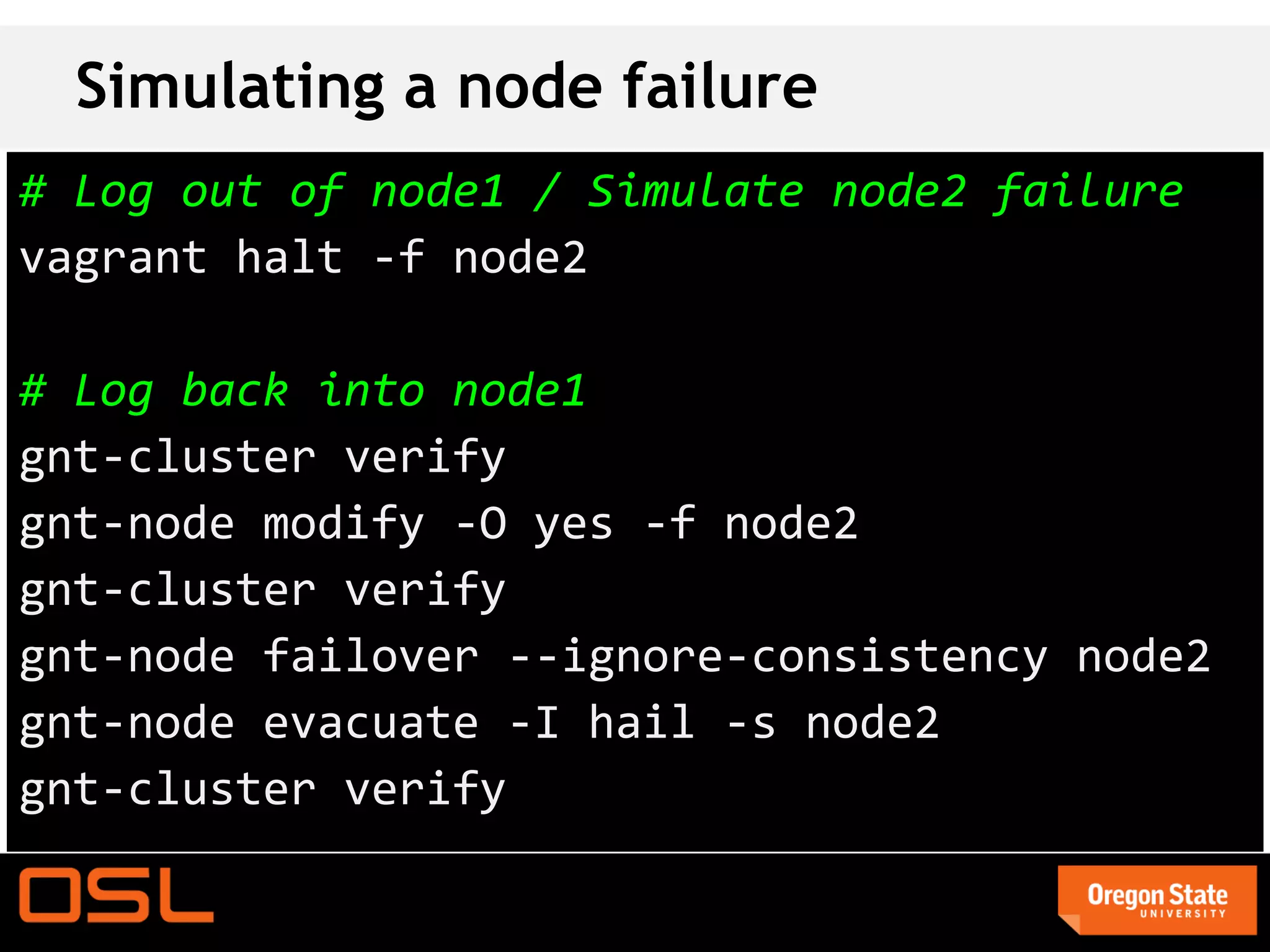
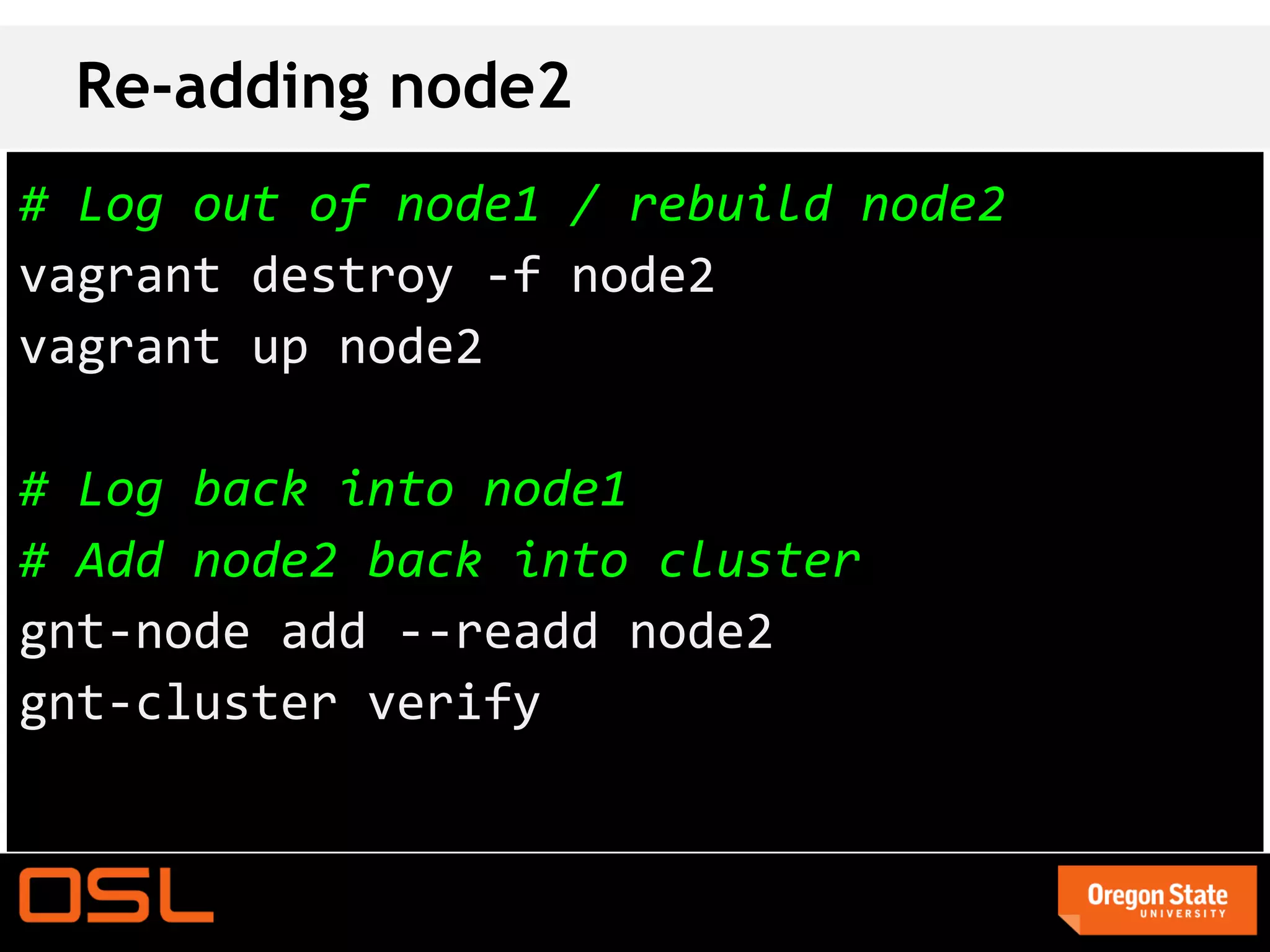


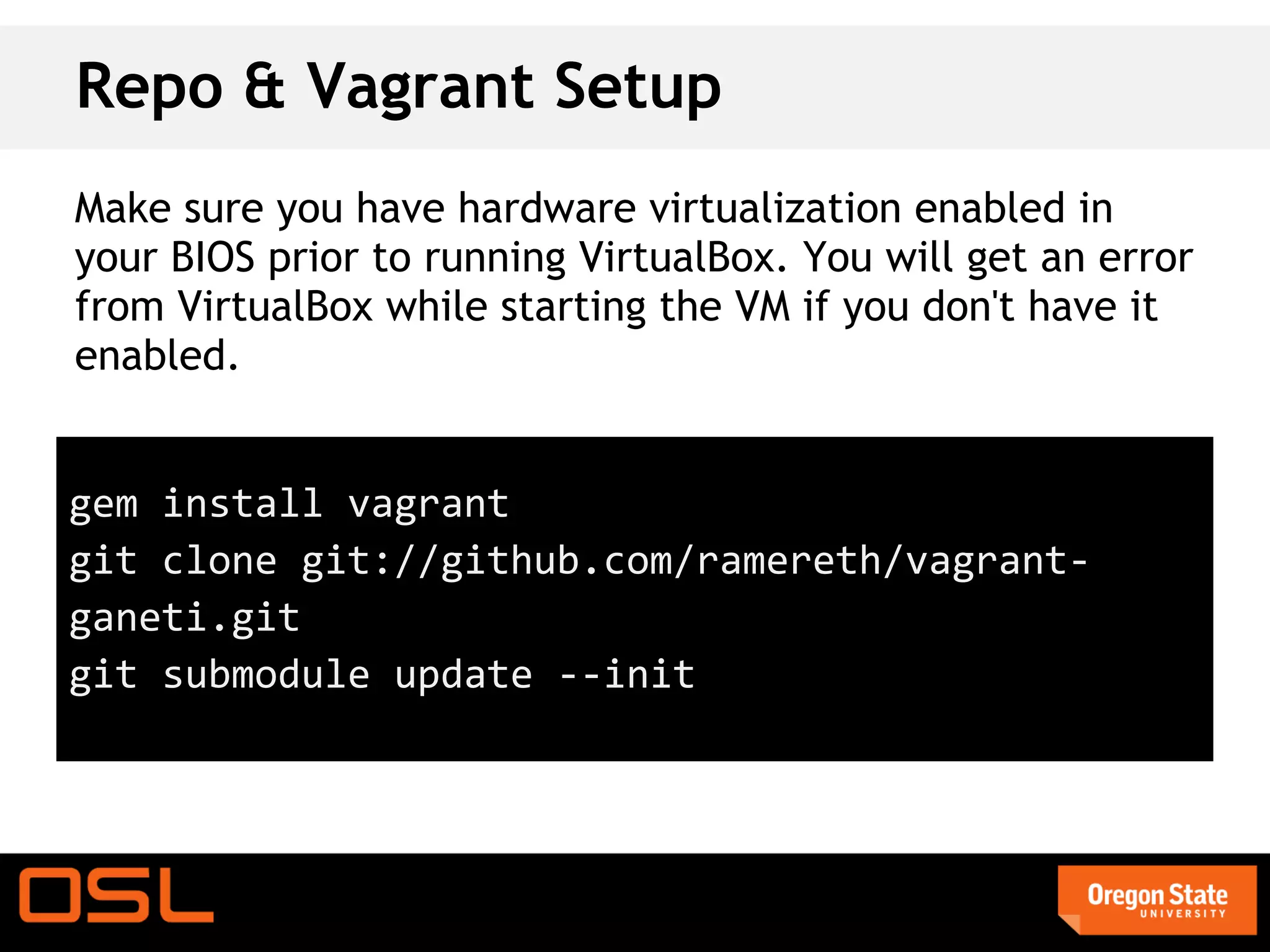
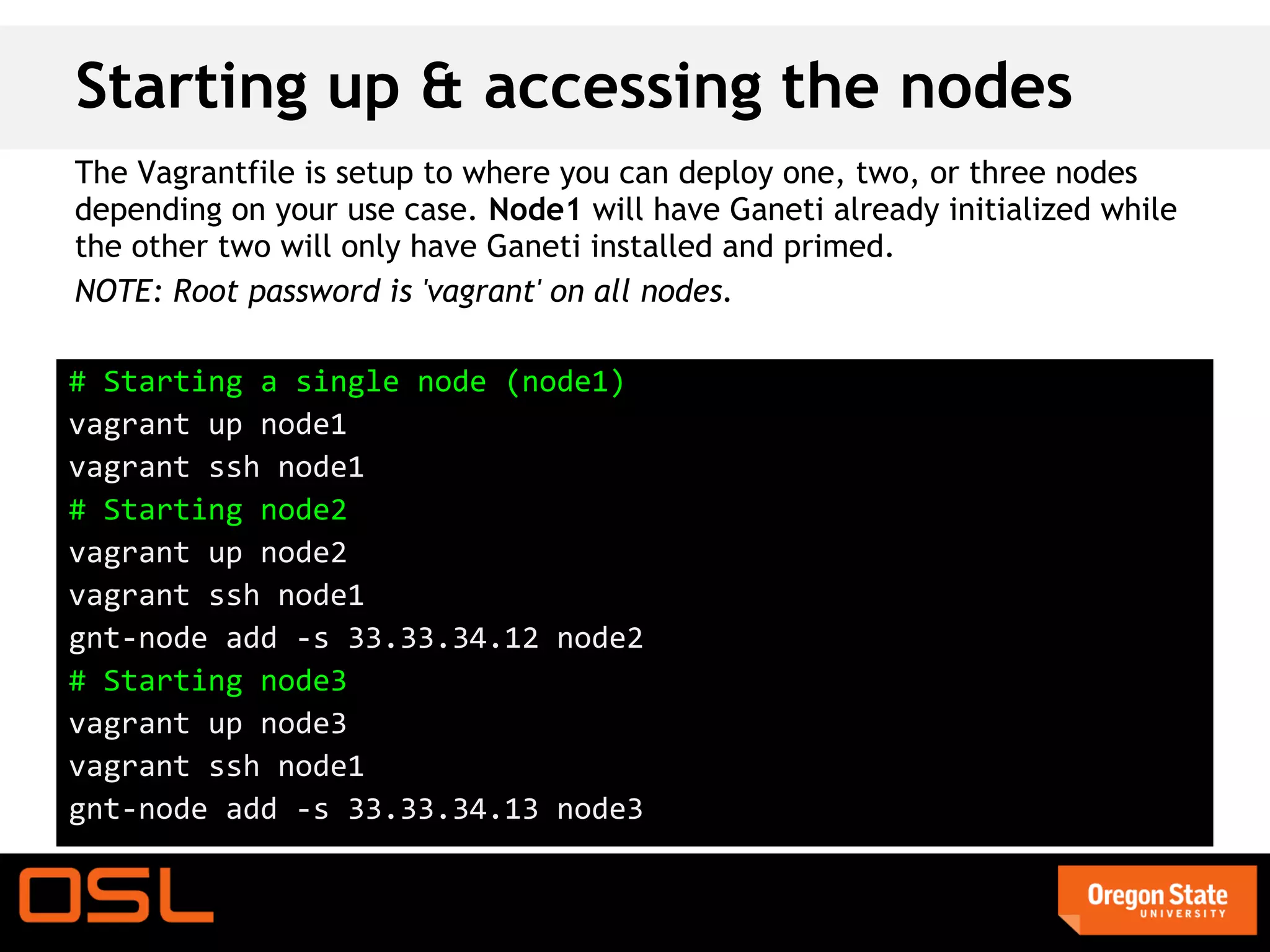
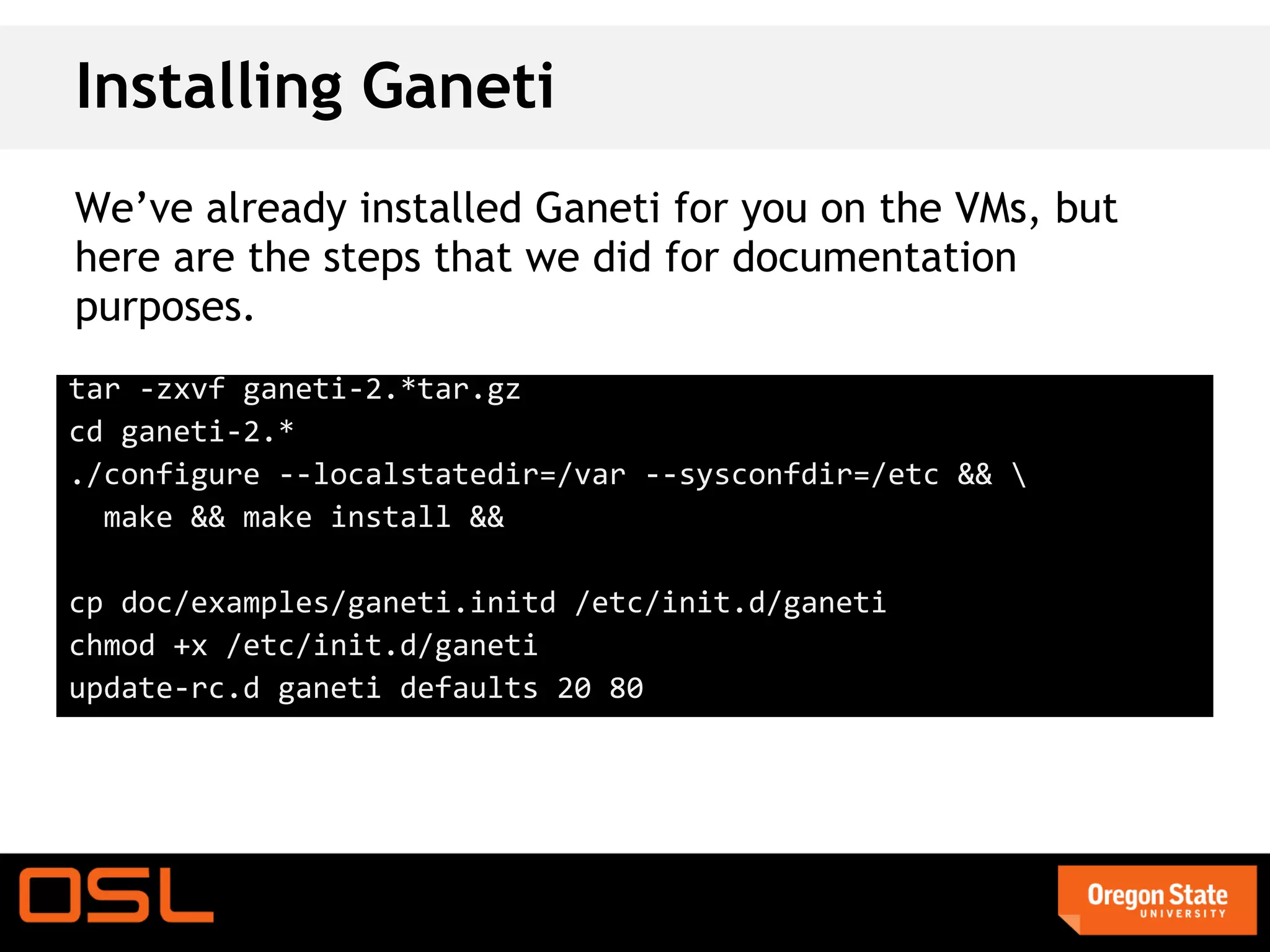
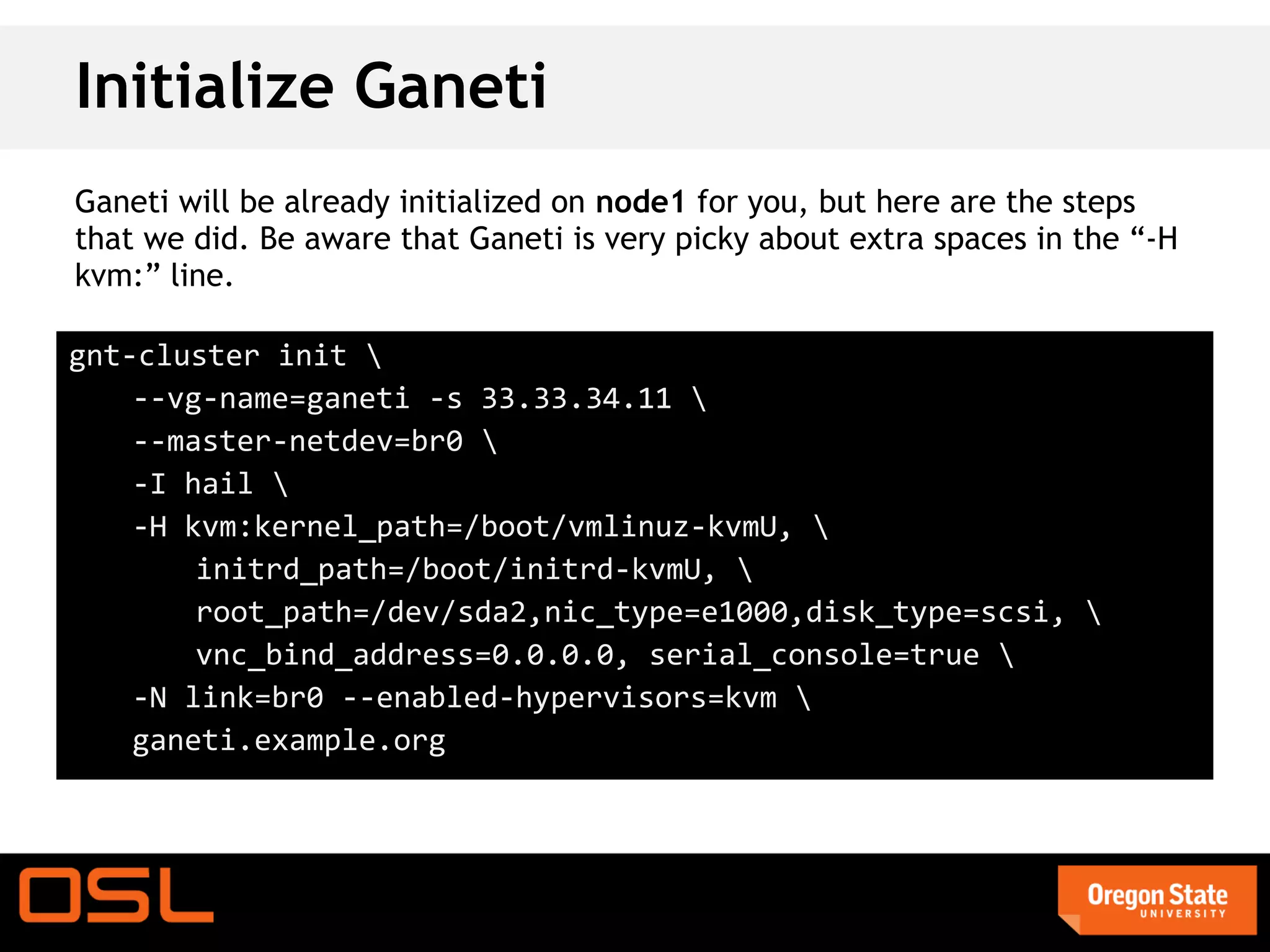
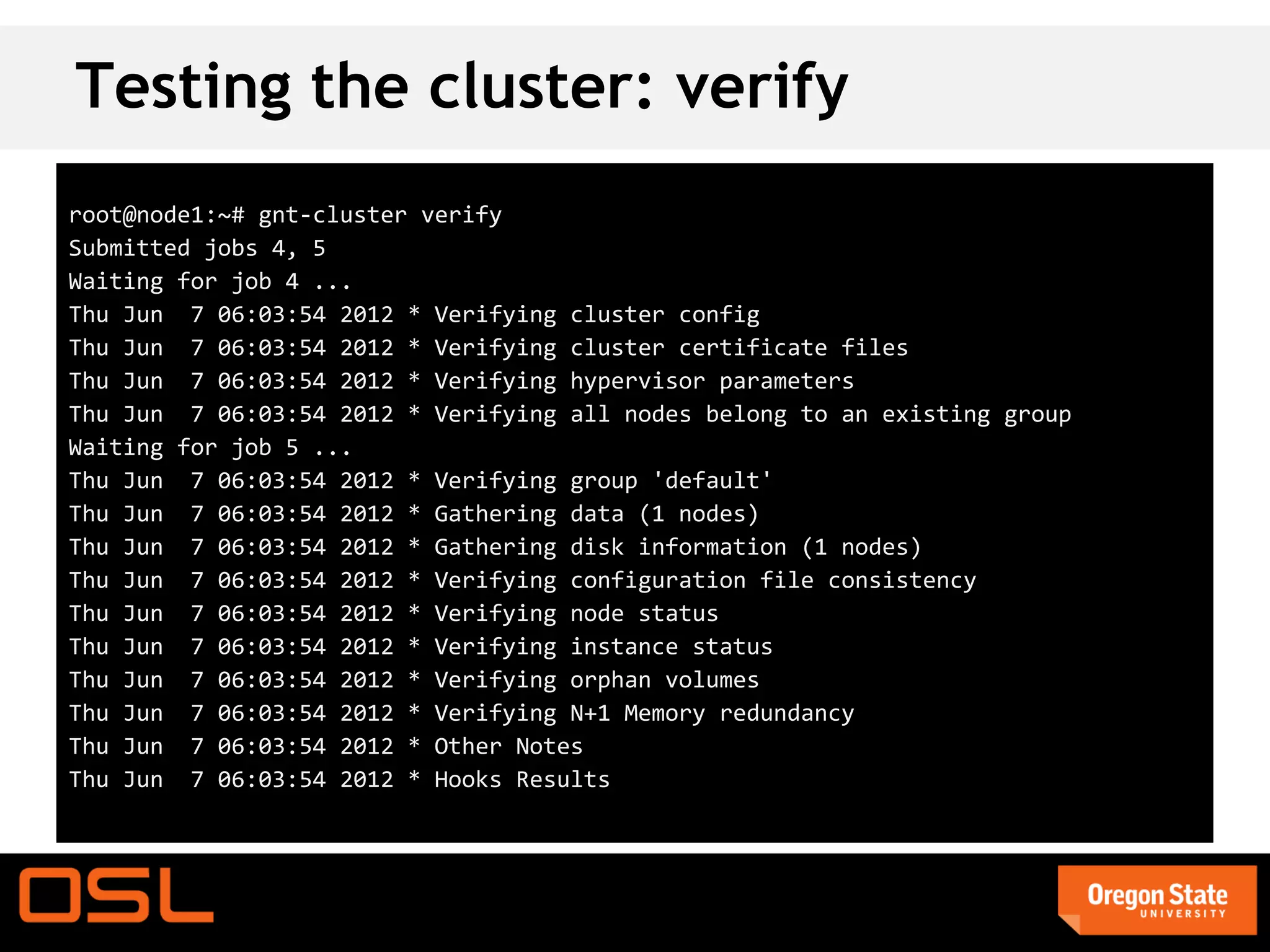
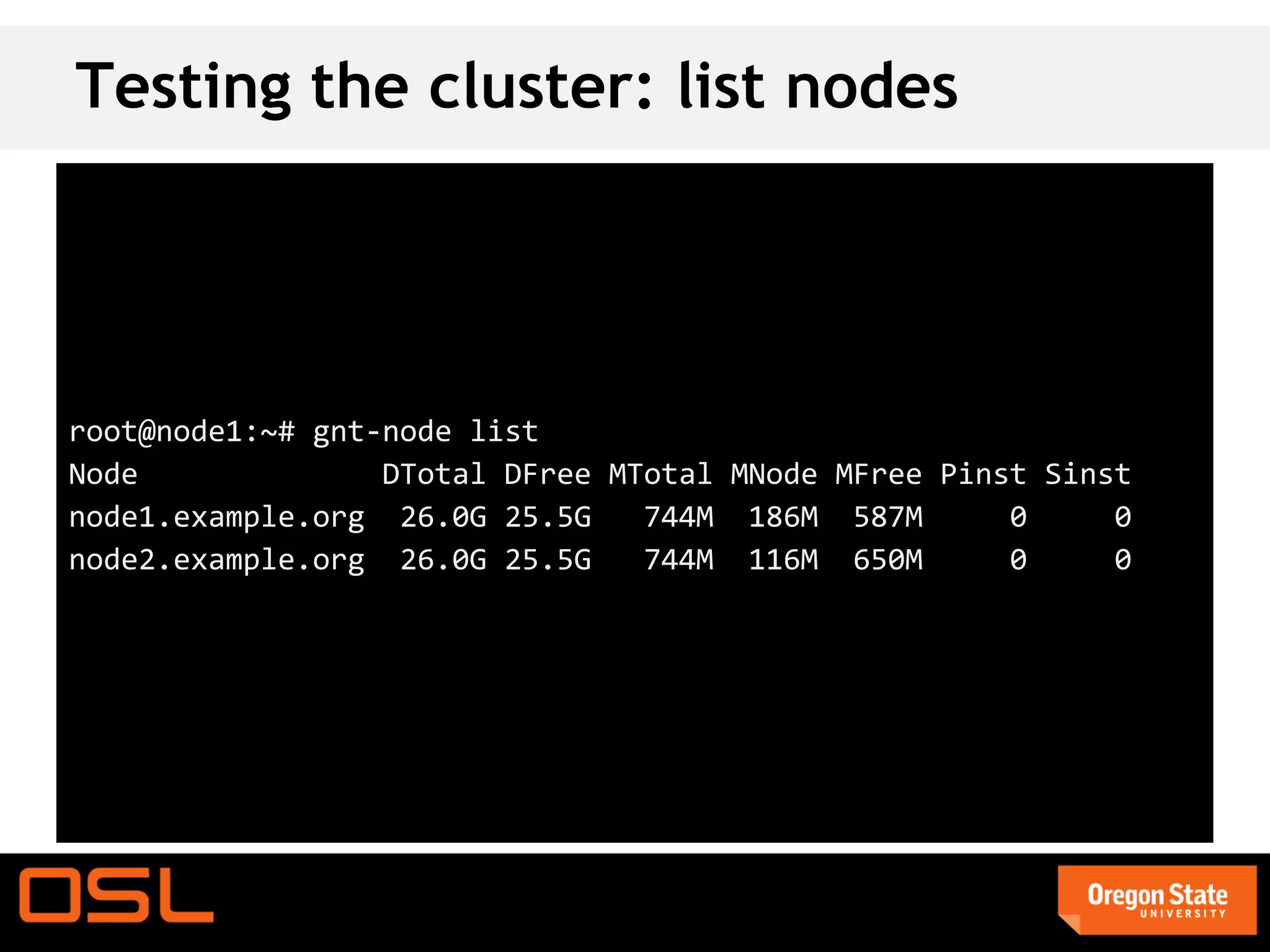
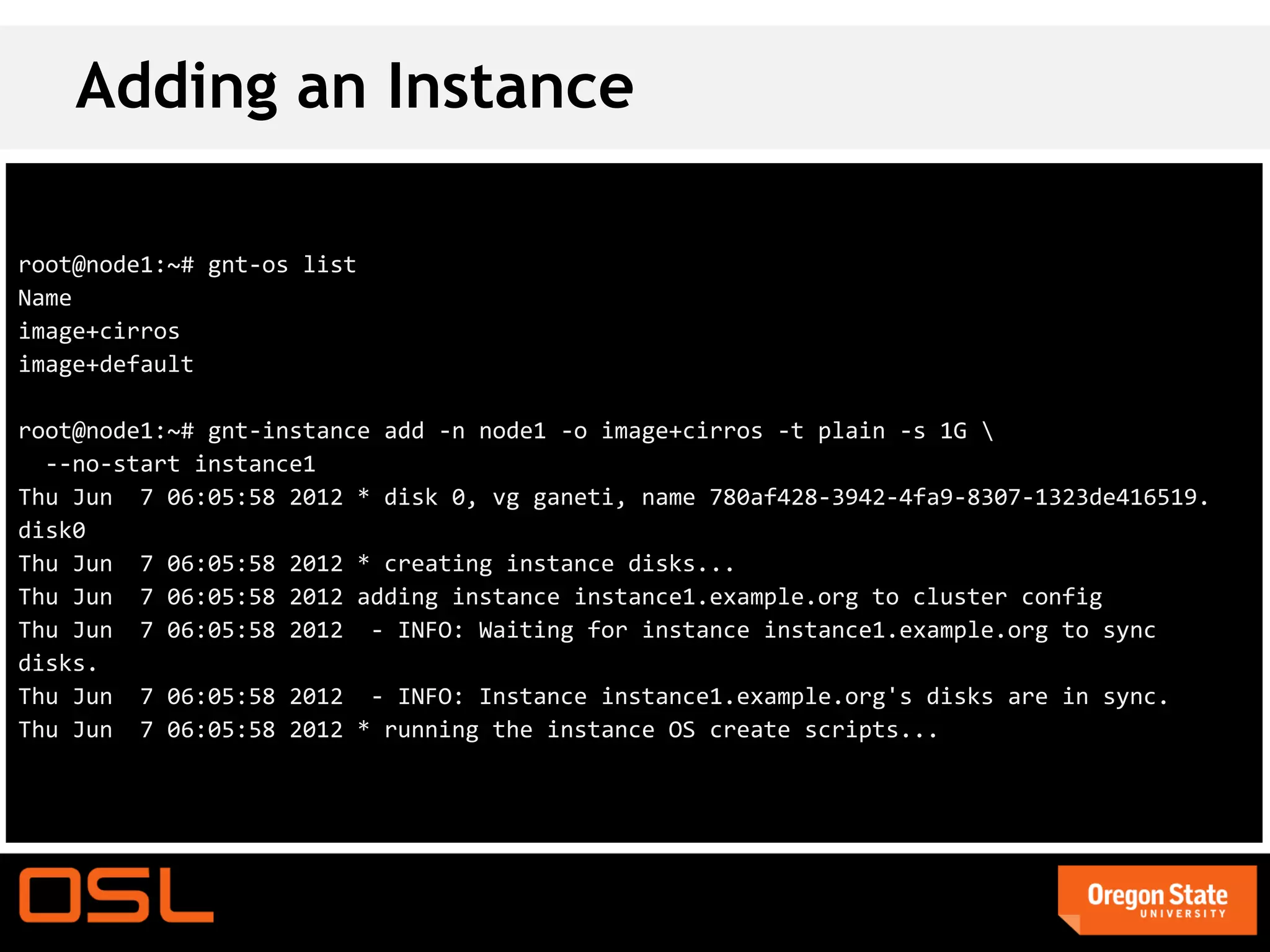
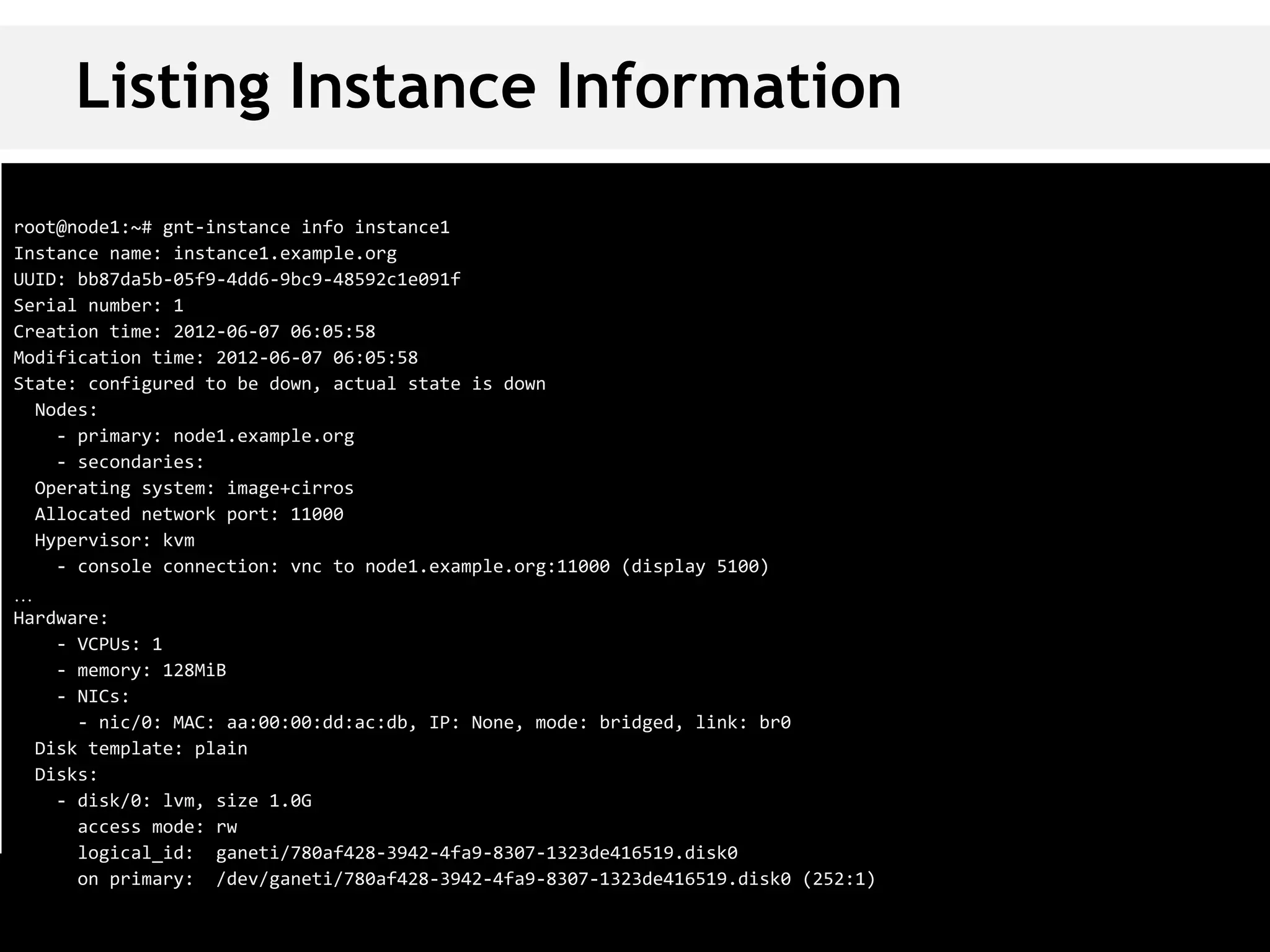
This document is a guide for setting up and managing a Ganeti cluster using Vagrant and VirtualBox, covering installation, initialization, instance management, and handling node failures. It includes detailed instructions for configuring nodes, adding instances, and performing operations such as failover and migration. The guide emphasizes the need for specific software and configurations before running the virtual environment, ensuring users can effectively test Ganeti on their laptops.


























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)





