Recommended
PPT
PDF
PDF
111015 tokyo scipy2_ディスカッション
PDF
PDF
PDF
110828 tokyo scipy1_hido_dist
PDF
Student Cup 2020 2nd(?) solution LT
PDF
PPTX
PPTX
PPTX
Knowledge_graph_alignment_with_entity-pair_embedding
PPTX
PDF
PDF
PDF
PDF
PDF
Encoder-decoder 翻訳 (TISハンズオン資料)
PDF
PDF
Acl yomikai, 1016, 20110903
PPTX
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」
PDF
再帰型ニューラルネット in 機械学習プロフェッショナルシリーズ輪読会
PDF
PDF
PDF
PDF
PDF
日本音響学会2017秋 ビギナーズセミナー "深層学習を深く学習するための基礎"
PDF
日本語テキスト音声合成のための句境界予測モデルの検討
PPTX
Retrofitting Word Vectors to Semantic Lexicons
PPTX
[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...
PDF
[DL Hacks]BERT: Pre-training of Deep Bidirectional Transformers for Language ...
More Related Content
PPT
PDF
PDF
111015 tokyo scipy2_ディスカッション
PDF
PDF
PDF
110828 tokyo scipy1_hido_dist
PDF
Student Cup 2020 2nd(?) solution LT
PDF
What's hot
PPTX
PPTX
PPTX
Knowledge_graph_alignment_with_entity-pair_embedding
PPTX
PDF
PDF
PDF
PDF
PDF
Encoder-decoder 翻訳 (TISハンズオン資料)
PDF
PDF
Acl yomikai, 1016, 20110903
PPTX
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」
PDF
再帰型ニューラルネット in 機械学習プロフェッショナルシリーズ輪読会
PDF
PDF
PDF
PDF
PDF
日本音響学会2017秋 ビギナーズセミナー "深層学習を深く学習するための基礎"
PDF
日本語テキスト音声合成のための句境界予測モデルの検討
PPTX
Retrofitting Word Vectors to Semantic Lexicons
Similar to [FUNAI輪講] BERT
PPTX
[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...
PDF
[DL Hacks]BERT: Pre-training of Deep Bidirectional Transformers for Language ...
PDF
PPTX
PPTX
Bert(transformer,attention)
PDF
[DL Hacks]Pretraining-Based Natural Language Generation for Text Summarizatio...
PDF
Distilling Knowledge Learned in BERT �for Text Generation
PDF
Derivative models from BERT
PDF
PPTX
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-D...
PDF
PDF
PDF
transformer解説~Chat-GPTの源流~
PDF
Linguistic Knowledge as Memory for Recurrent Neural Networks_論文紹介
PDF
PPTX
A primer in bertology what we know about how bert works
PDF
PPTX
PDF
[ML論文読み会資料] Teaching Machines to Read and Comprehend
PDF
Facebookの人工知能アルゴリズム「memory networks」について調べてみた
[FUNAI輪講] BERT 1. 2. 3. 論文概要 正式名称 : Pre-training of Deep
Bidirectional Transformers for
Language Understanding
BERT = Bidirectional Encoder
Representations from
Transformers
2018 年 10 月の SOTA 論文
自然言語処理のモデル
Transformer が使われている
大規模な事前学習モデル
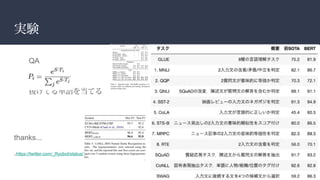
7 つの NLP タスクにて SOTA
4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14.
![[ 論文紹介 ] BERT
学部3年 海老原](https://image.slidesharecdn.com/bert-190625044118/85/FUNAI-BERT-1-320.jpg)
![[ 論文紹介 ] BERT
学部3年 海老原](https://image.slidesharecdn.com/bert-190625044118/75/FUNAI-BERT-1-2048.jpg)


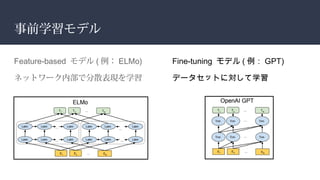
![復習: transformer
encoder: self-attention
入力 X
Q,K,V = X*W[q],*W[k],*W[v]
softmax(Q*K)*V
Q: 検索クエリ
K: 文字
V: データ](https://image.slidesharecdn.com/bert-190625044118/85/FUNAI-BERT-6-320.jpg)
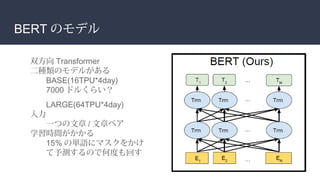
![BERT のモデル
インプットは 512 になるように切る
必ず最初に [CLS] を使う
2 つの文を使うとき [SEP] を使うか、 AB をつける](https://image.slidesharecdn.com/bert-190625044118/85/FUNAI-BERT-8-320.jpg)































![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks]BERT: Pre-training of Deep Bidirectional Transformers for Language ...](https://cdn.slidesharecdn.com/ss_thumbnails/20181129suzukibert1-181204064830-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL Hacks]Pretraining-Based Natural Language Generation for Text Summarizatio...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspretraining-basednaturallanguagegenerationfortextsummarization-190422070150-thumbnail.jpg?width=640&height=640&fit=bounds)












![[ML論文読み会資料] Teaching Machines to Read and Comprehend](https://cdn.slidesharecdn.com/ss_thumbnails/ml2-171222014201-thumbnail.jpg?width=640&height=640&fit=bounds)
