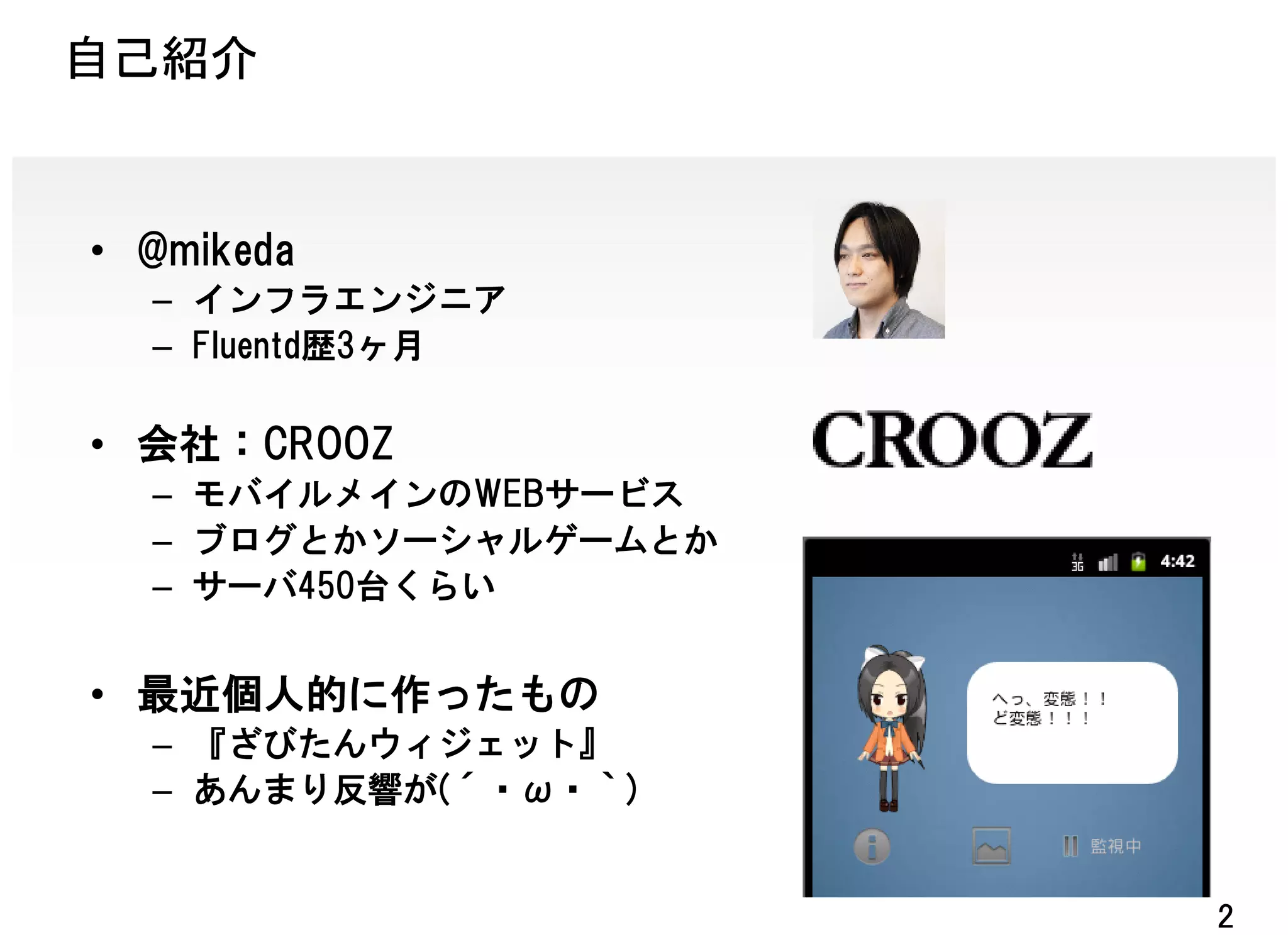
exec_filterの例
• モバイルサイトのアクセスログフィルタ
– キャリアごとのUID→統合UID、静的ファイルの除外
#!/usr/lib64/fluent/ruby/bin/ruby
require 'digest/sha1‘
path_filter = Regexp.new "^/(img|swf|css|js|healthcheck)/"
while line = STDIN.gets
line.chomp!
host,method,path,code,size,referer,agent,dcmuid,auuid,sbuid,spuid = line.split("¥t")
next if path_filter =~ path
uid = ""
[dcmuid, auuid, sbuid,spuid].each do |id|
if id != "-"
uid = Digest::SHA1.hexdigest id
break
end
end
puts [host,method,path,code,size,referer,agent,uid].join("¥t")
end
32
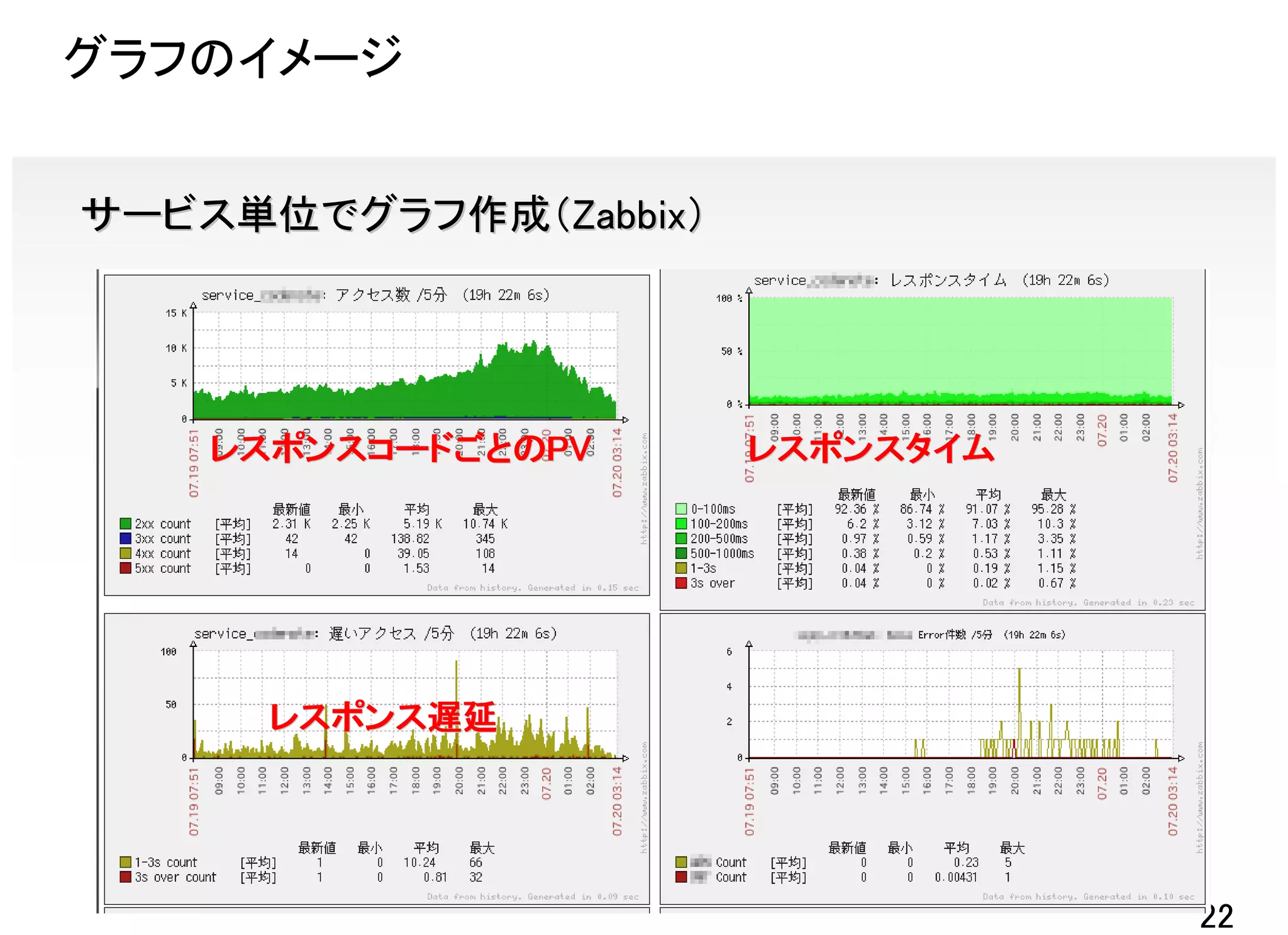
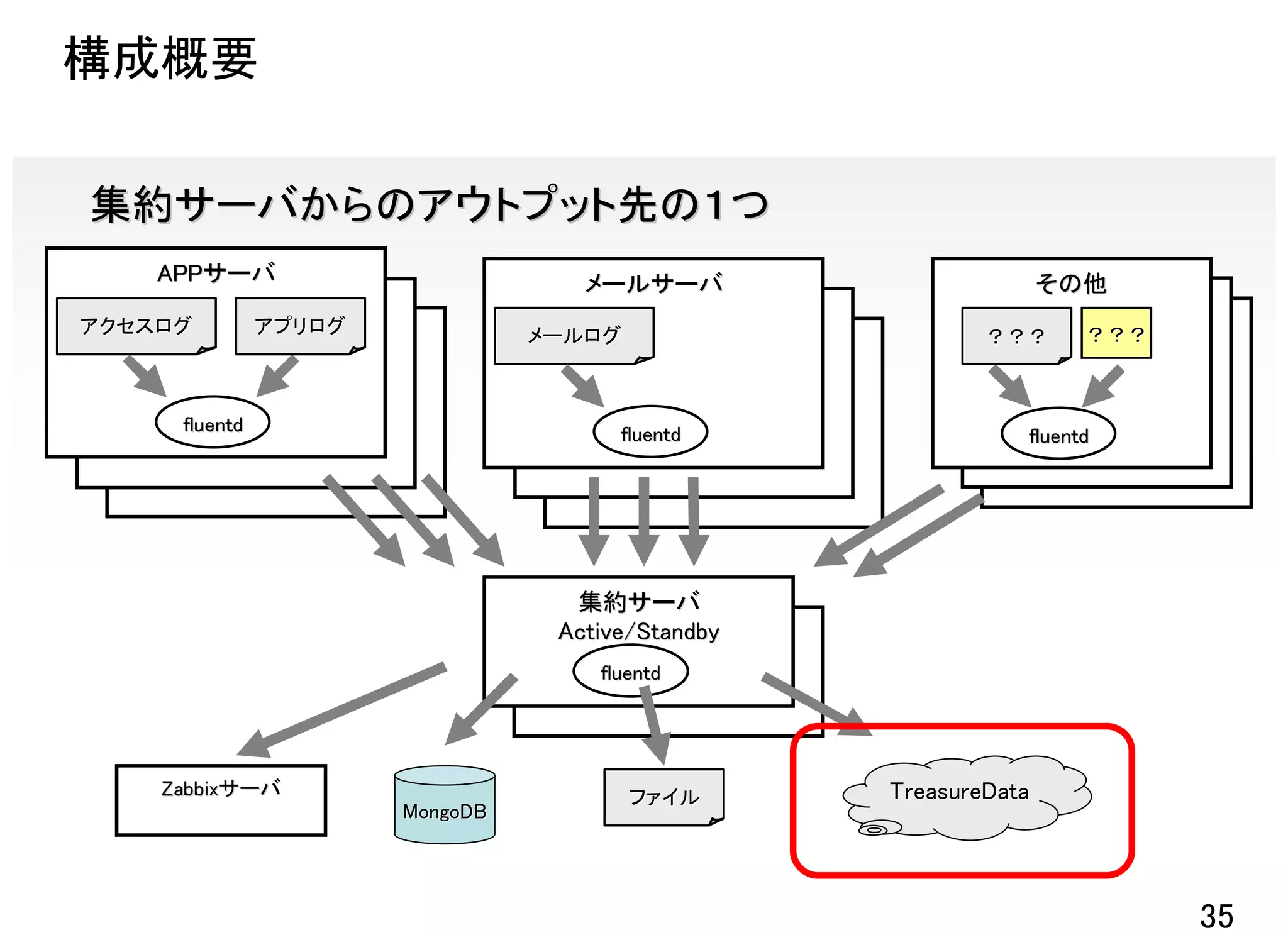
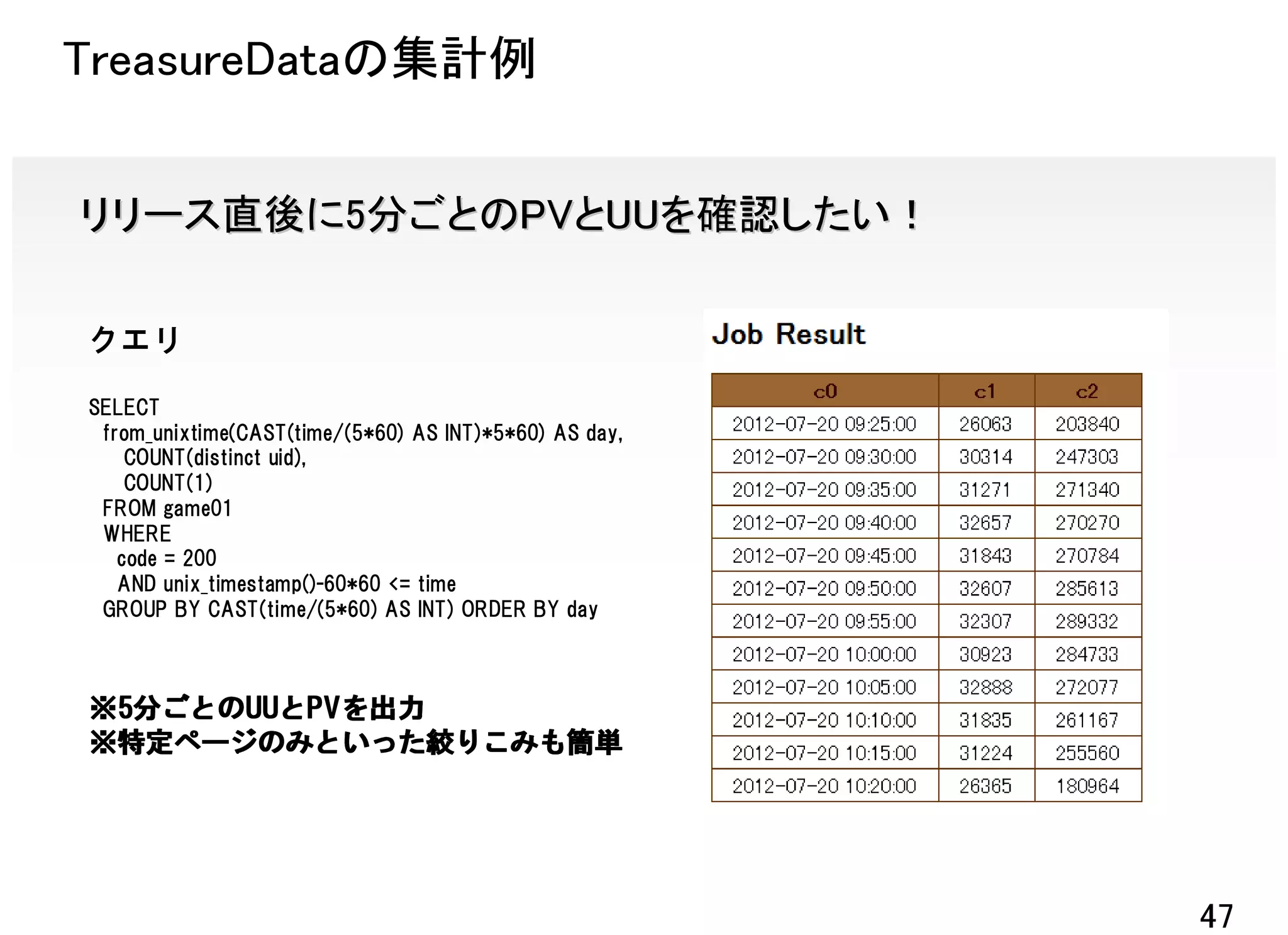
TreasureDataの集計例
問合せ調査 「タイムアウトばっかりでアクセスできません」
クエリ
SELECT time,restime, path
FROM game01
WHERE
unix_timestamp()-24*60*60 < time
AND uid = XXXXXXX
ORDER BY time
マイページアクセスが5秒以上かかっている
マイページアクセスが5
※指定ユーザのアクセスパスと処理 →特定ユーザの場合のみ
時間を時系列で出力 タイムアウトが発生するバグがあった
46





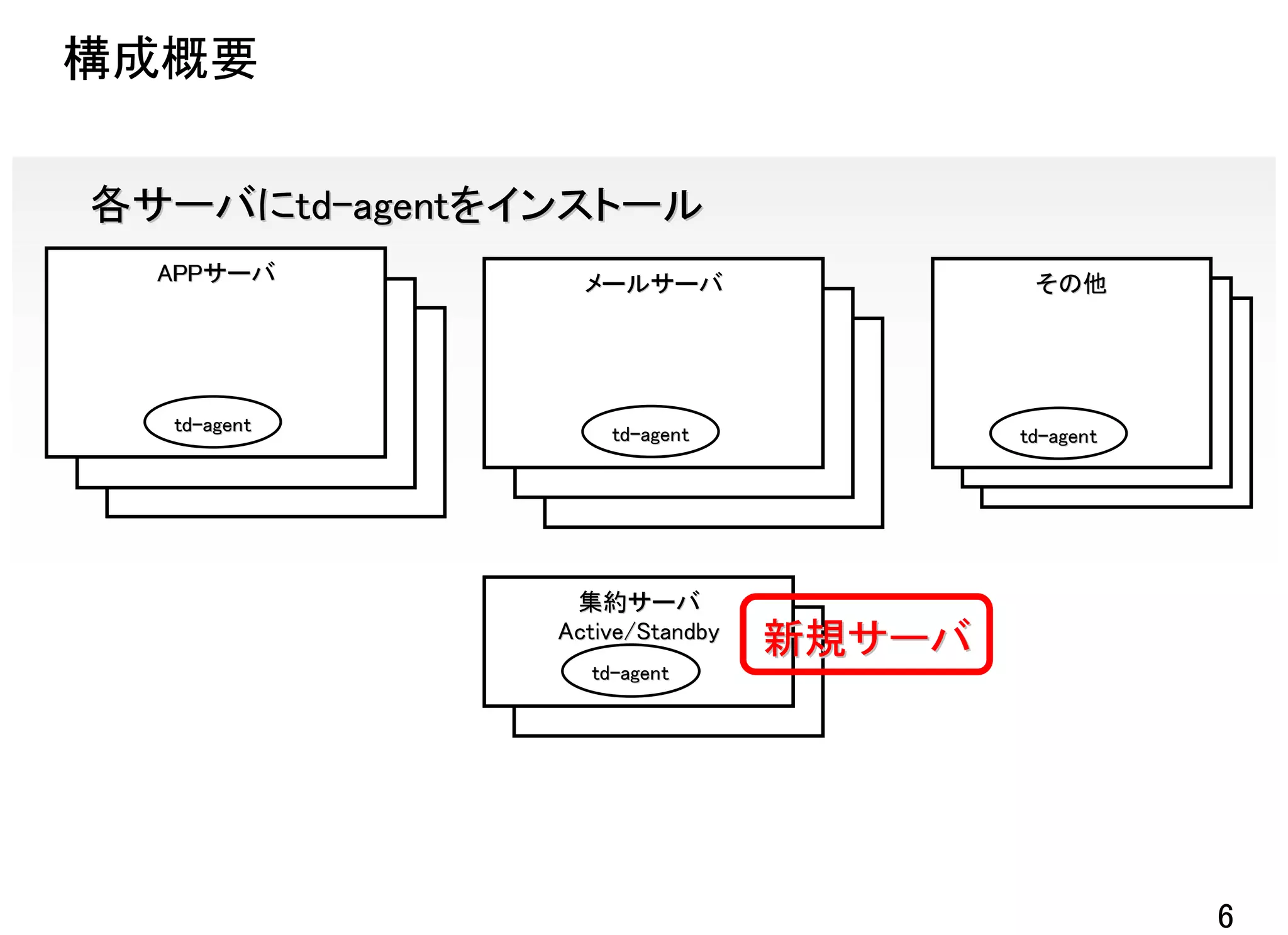
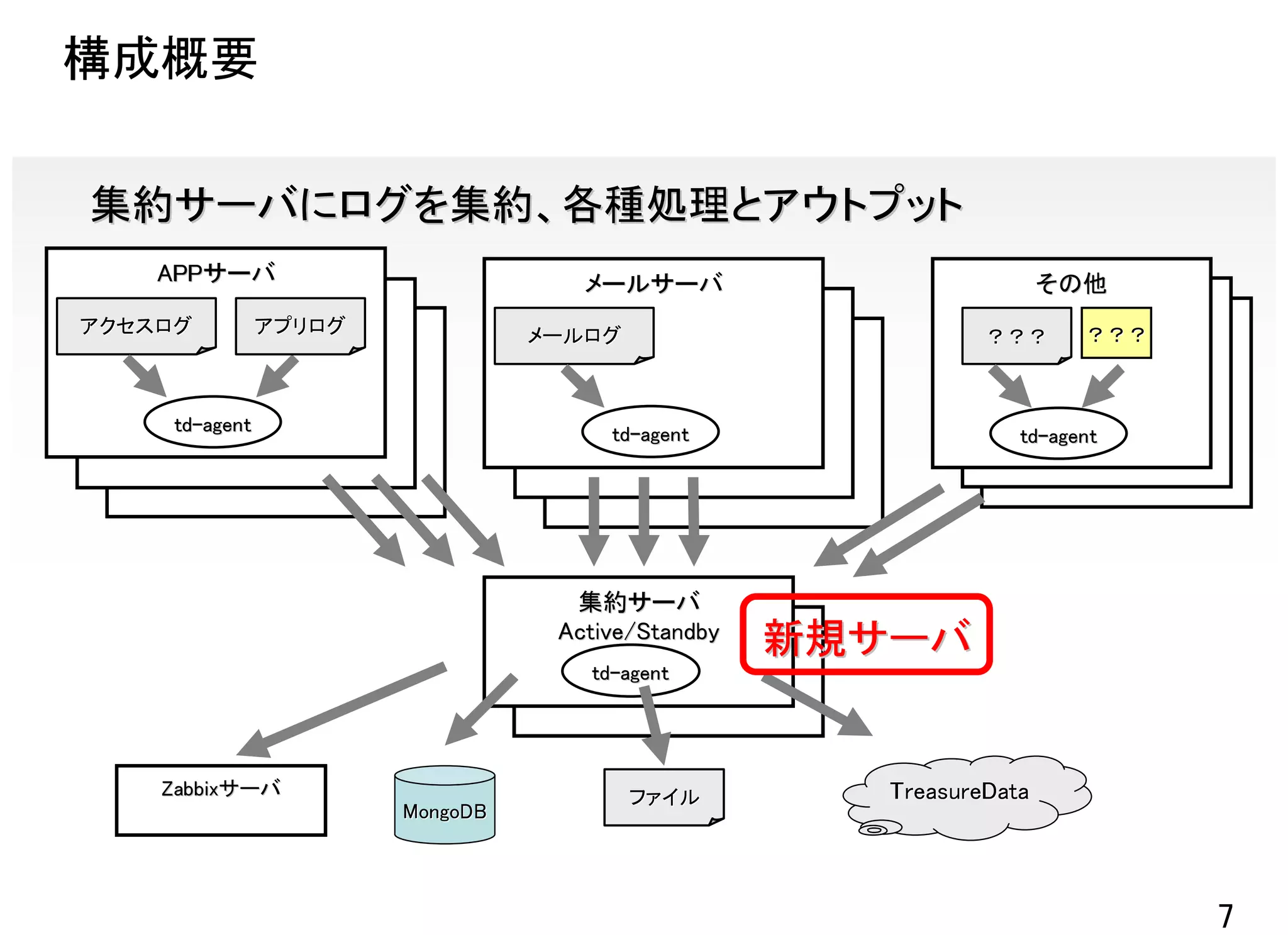
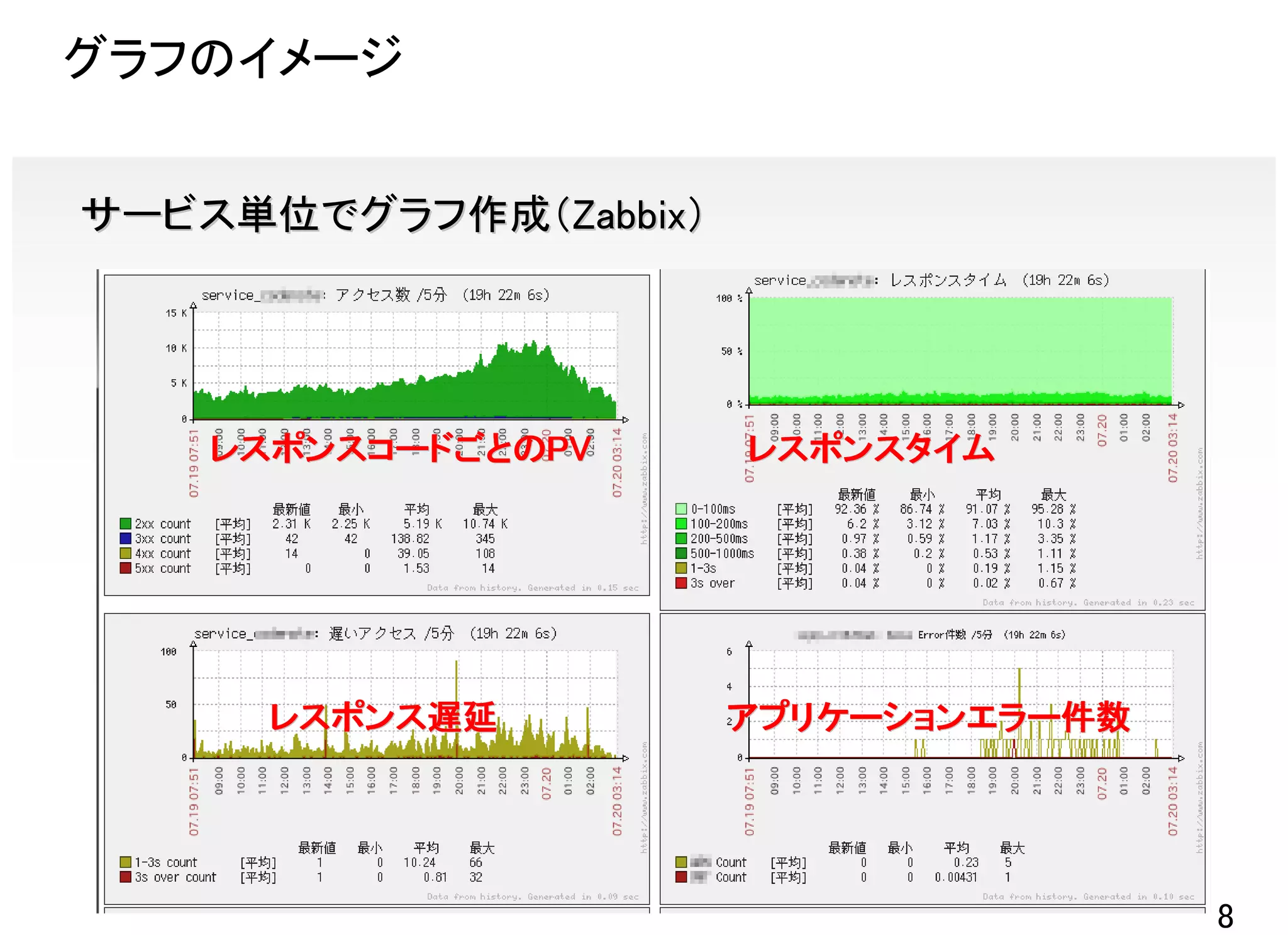











![APPサーバ側設定 サービスごとの設定
• conf.d/site01.conf
– アクセスログのtail
<source>
type tail
format format /^(?<host>[^ ]*) [^ ]* [^ ]* ¥[(?<time>[^¥]]*)¥]
"(?<method>¥S+) +(?<path>[^ ]+) +¥S*" (?<code>[^ ]*) (?<size>[^ ]*)
"(?<referer>[^¥"]*)" "(?<agent>[^¥"]*)" (?<restime>[^ ]*)/
time_format %d/%b/%Y:%H:%M:%S %z
path /var/log/httpd/site01-access_log.link
tag forward.access.site01
pos_file /var/log/td-agent/site01-access_log.pos
</source>
25](https://image.slidesharecdn.com/fluentdmeetup-120826034556-phpapp01/75/Fluentd-meetup-2-25-2048.jpg)



![集約サーバ側設定 サービスごとの設定2段目
• 2段目:カウンティングとTreasureDataへのデータ送信
<match filtered.access.game01>
type copy
<store>
type tdlog
apikey XXXXXXXXXXXXXXXXXXXXXXX
buffer_type file
buffer_path /var/log/td-agent/buffer/game01/td
use_ssl true
auto_create_table
flush_interval 300s
TreasureDataに送信
</store>
<store>
type datacounter
count_key code
aggregate all
tag count.access.game01.code
count_interval 300
pattern1 2xx ^2¥d¥d$
pattern2
pattern3
3xx
4xx
^3¥d¥d$
^4¥d¥d$
レスポンスコードごとにカウント
pattern4 5xx ^5¥d¥d$
</store>
<store>
type datacounter
count_key restime
aggregate all
tag count.access.game01.restime
count_interval 300
pattern1 0to100ms ^¥d{1,5}$
pattern2 100to200ms ^1¥d{5}$
pattern3
pattern4
200to500ms ^[2-4]¥d{5}$
500to1000ms ^[5-9]¥d{5}$
レスポンスタイムごとにカウント
pattern5 1000to4000ms ^[0-3]¥d{6}$
pattern6 over4000ms ^([4-9]¥d{6}|¥d{8,})$
</store>
</match>
29](https://image.slidesharecdn.com/fluentdmeetup-120826034556-phpapp01/75/Fluentd-meetup-2-29-2048.jpg)


![exec_filterの例
• モバイルサイトのアクセスログフィルタ
– キャリアごとのUID→統合UID、静的ファイルの除外
#!/usr/lib64/fluent/ruby/bin/ruby
require 'digest/sha1‘
path_filter = Regexp.new "^/(img|swf|css|js|healthcheck)/"
while line = STDIN.gets
line.chomp!
host,method,path,code,size,referer,agent,dcmuid,auuid,sbuid,spuid = line.split("¥t")
next if path_filter =~ path
uid = ""
[dcmuid, auuid, sbuid,spuid].each do |id|
if id != "-"
uid = Digest::SHA1.hexdigest id
break
end
end
puts [host,method,path,code,size,referer,agent,uid].join("¥t")
end
32](https://image.slidesharecdn.com/fluentdmeetup-120826034556-phpapp01/75/Fluentd-meetup-2-32-2048.jpg)



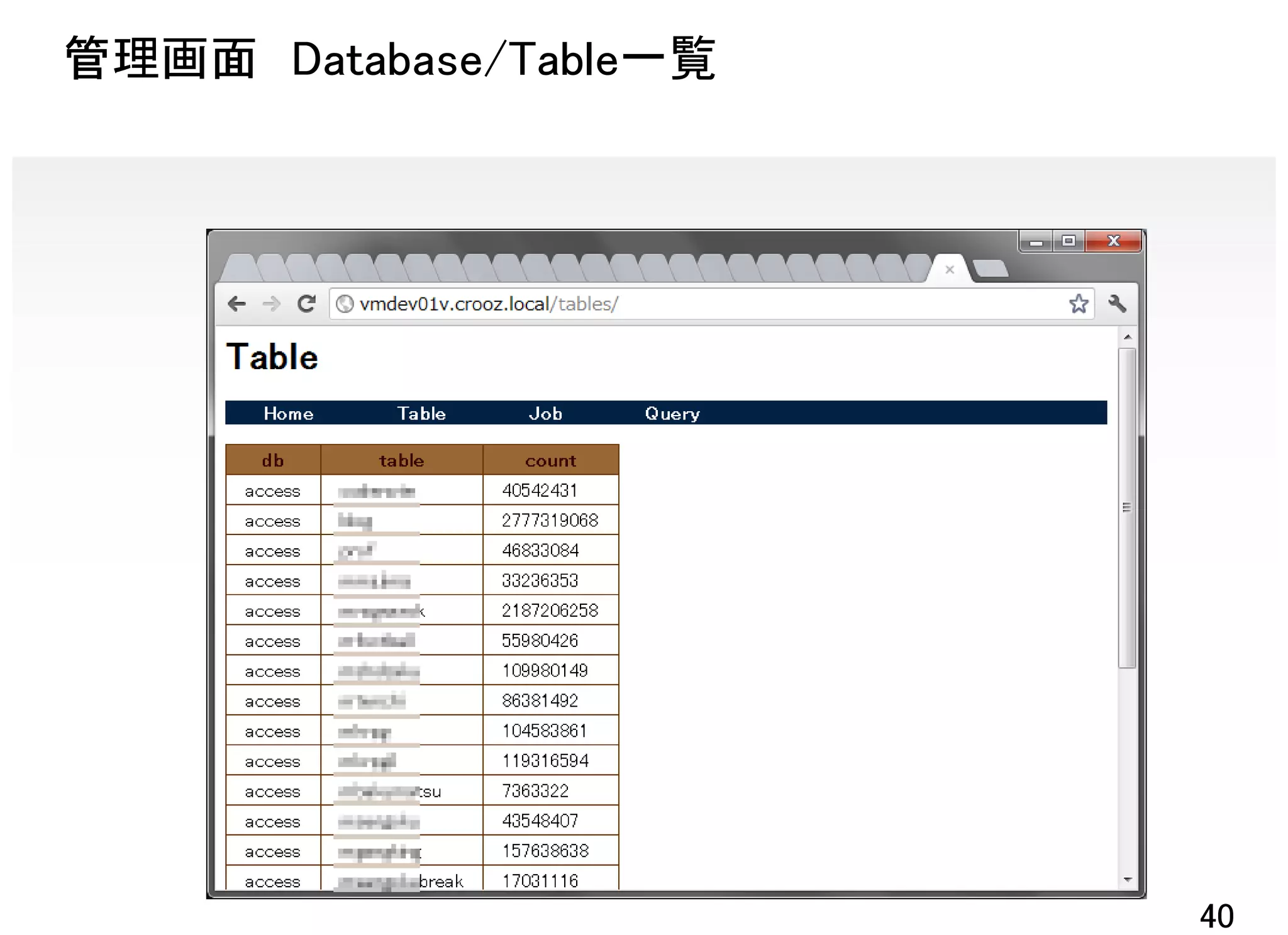
![CLIでデータ参照
• データ確認
$ td table:tail access game01
“size”:“234880”,“uid”:“XXXX”,“host”:“xx.xx.xx.xx”,“restime”:“95961”,
{“referer”:“-”,“time”:1345590016,“method”:“GET”,“code”:“200”,
“agent”:“Mozilla/5.0 ","path":"/mypage/"}
• 集計
$ td query -w -d access
"SELECT COUNT(distinct uid), COUNT(*) ¥
FROM blog ¥
WHERE unix_timestamp()-60*60*24 < time“
+---------+----------+
| _c0 | _c1 |
+---------+----------+
| 1927724 | 70917556 |
+---------+----------+
たいてい数分から十数分で完了(クエリと契約CPU数に依存)
※ td schema:setを実行するとv[‘uid’]じゃなくuidと書けるようになる
37](https://image.slidesharecdn.com/fluentdmeetup-120826034556-phpapp01/75/Fluentd-meetup-2-37-2048.jpg)

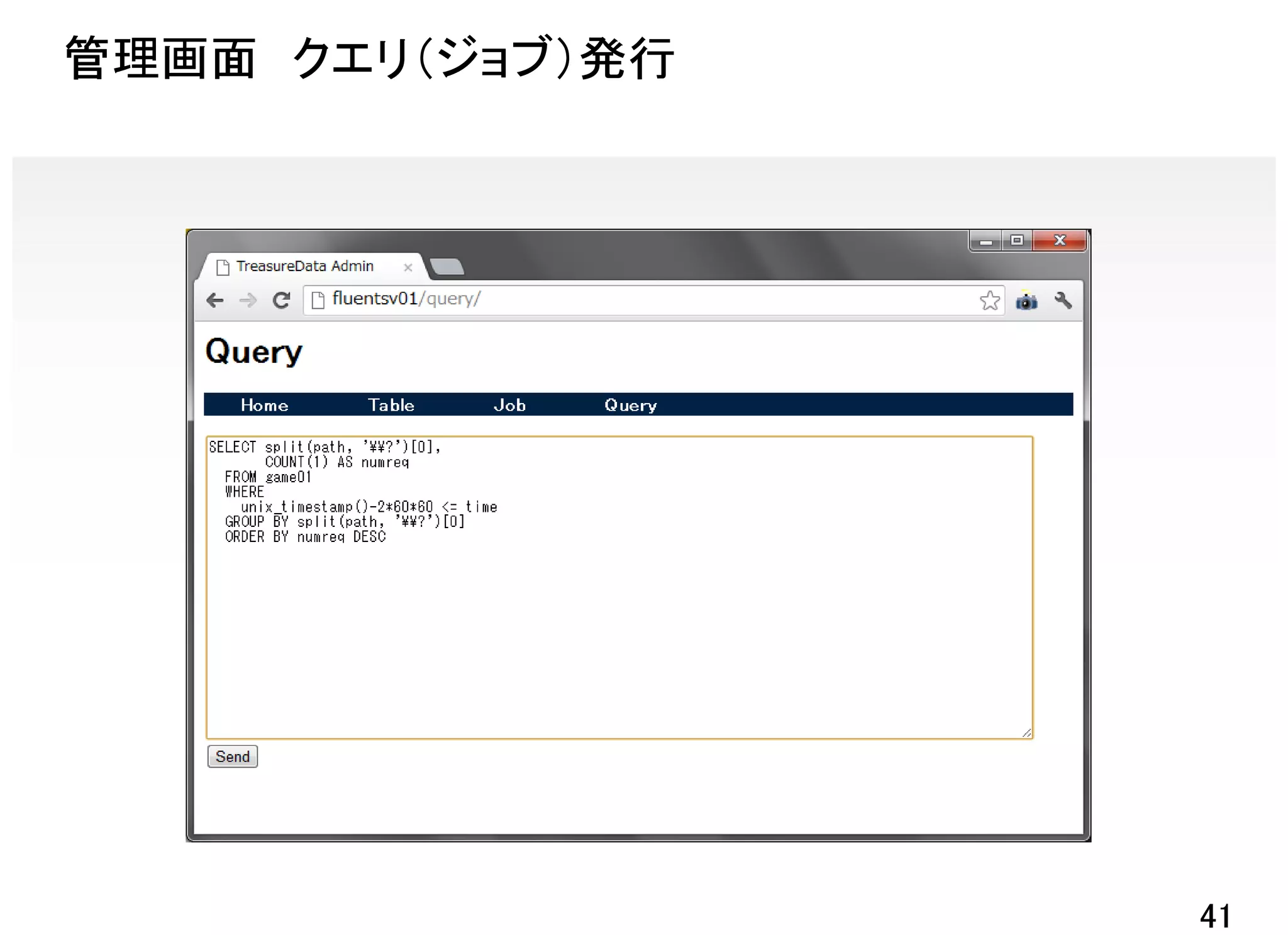
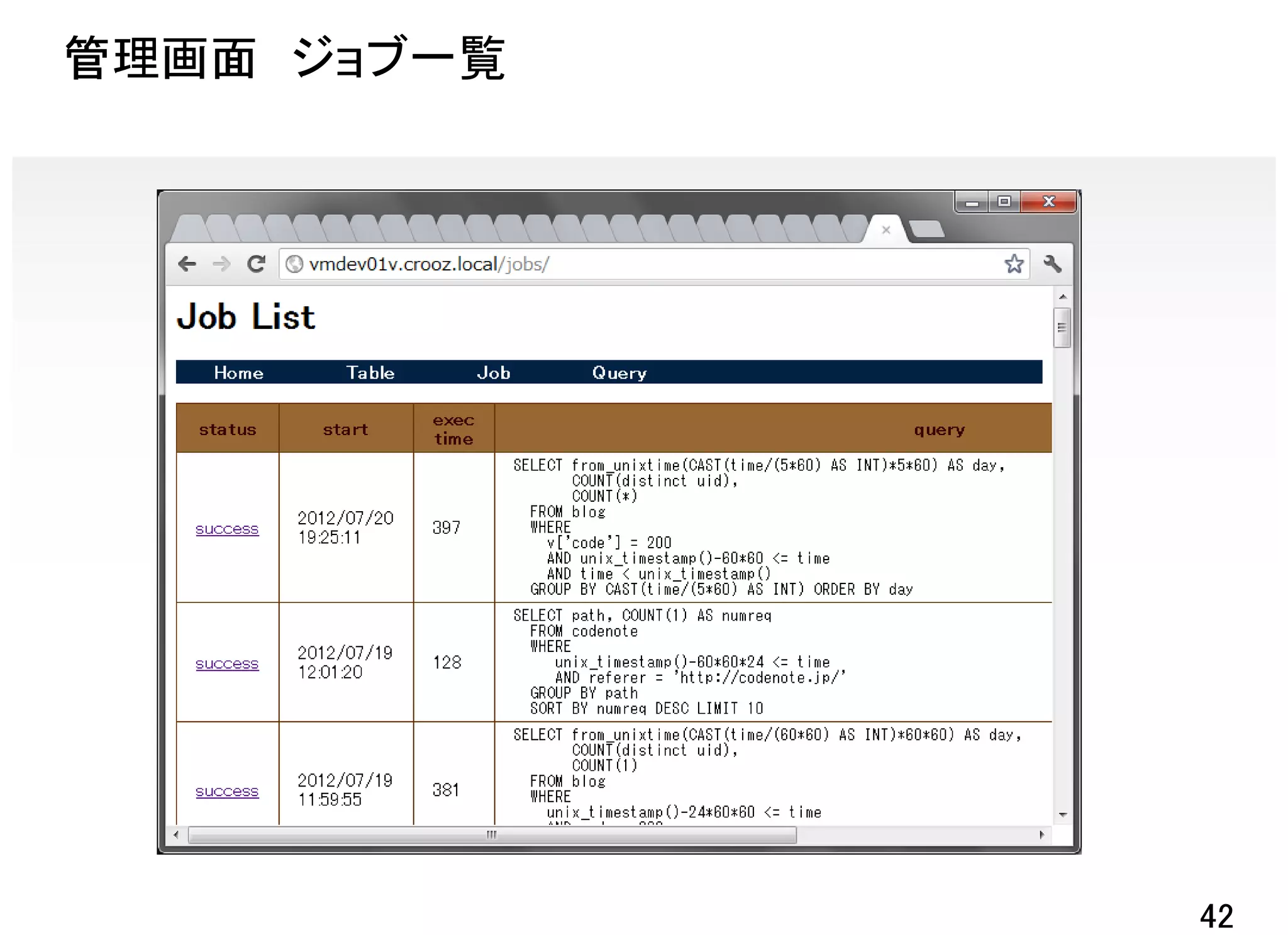
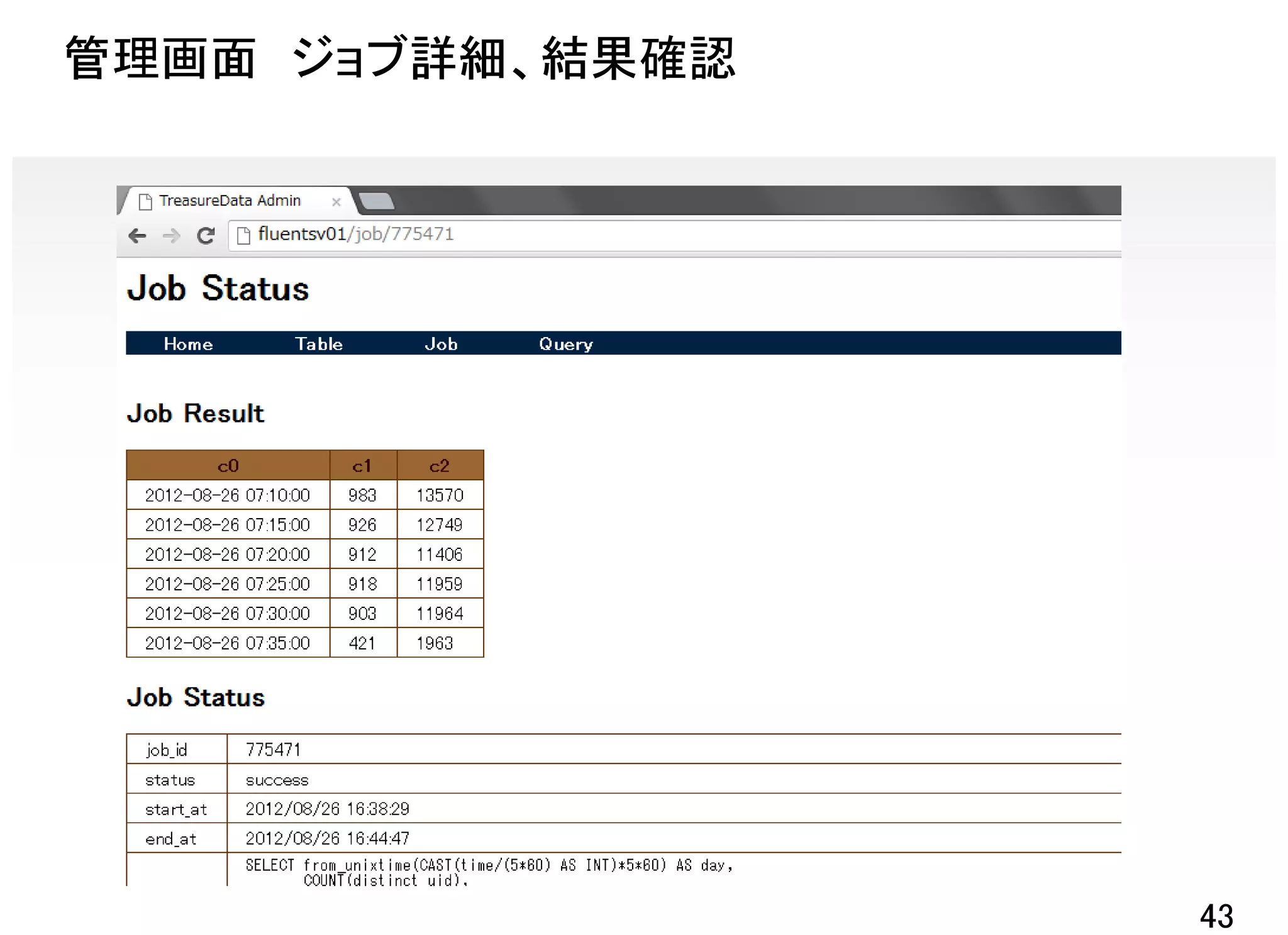

![TreasureDataの集計例
レスポンス遅延が発生してるのはどのページ!?
クエリ
SELECT split(path, '¥¥?')[0],
COUNT(1) AS numreq
FROM game01
WHERE
unix_timestamp()-1*60*60 <= time
AND restime > 3000000
GROUP BY split(path, '¥¥?')[0]
ORDER BY numreq DESC
※直近1時間で3秒以上かかっている件数
をパスごとに出力
45](https://image.slidesharecdn.com/fluentdmeetup-120826034556-phpapp01/75/Fluentd-meetup-2-45-2048.jpg)

![TreasureDataの集計例
チュートリアルの離脱ポイントはどこ?
クエリ
SELECT split(path, '¥¥?')[0],
COUNT(1) AS numreq
FROM game01
WHERE
unix_timestamp()-15*60 <= time
AND path LIKE '/tutorial/%'
GROUP BY split(path, '¥¥?')[0]
ORDER BY numreq DESC
※/tutorial/から始まるパスをアクセス数
順に出力
48](https://image.slidesharecdn.com/fluentdmeetup-120826034556-phpapp01/75/Fluentd-meetup-2-48-2048.jpg)








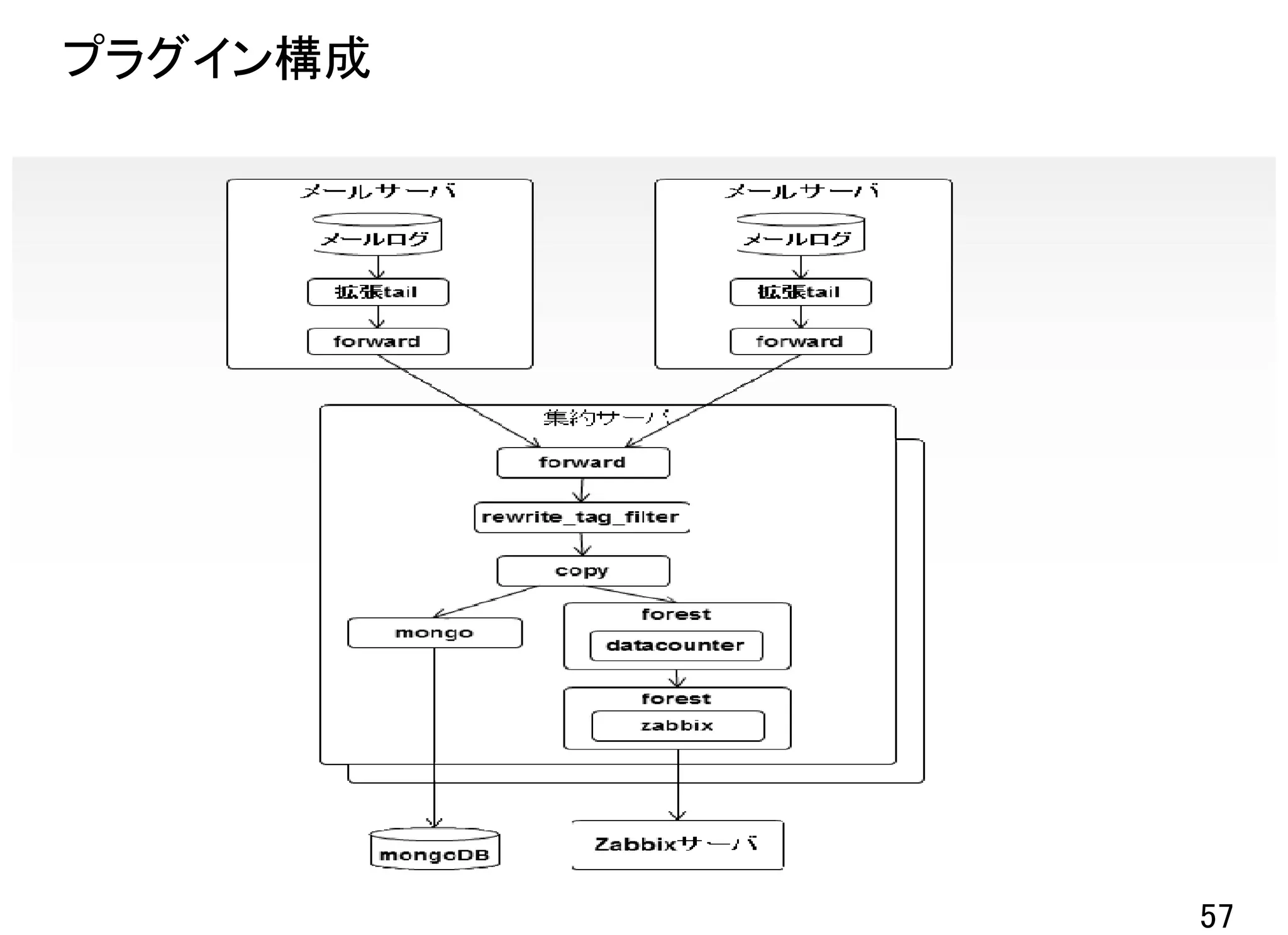



![集約サーバ側の設定 2段目
• 2段目:各種キーでカウンティング&mongodbにデータ投入
<match filtered.mail.rcv.*>
type copy
<store>
type forest
subtype datacounter
remove_prefix filtered.mail.rcv
<template>
count_key from
aggregate all
tag count.mail.rcv.__TAG__
count_interval 300
pattern1 docomo [@.]docomo¥.ne¥.jp$
pattern2 au [@.]ezweb¥.ne¥.jp$
pattern3 softbank [@.](softbank¥.ne¥.jp|vodafone¥.ne¥.jp)$
</template>
</store>
<store>
type mongo
61](https://image.slidesharecdn.com/fluentdmeetup-120826034556-phpapp01/75/Fluentd-meetup-2-61-2048.jpg)




































![[AWS初心者向けWebinar] AWSを活用したモバイルアプリの開発と運用](https://cdn.slidesharecdn.com/ss_thumbnails/20151117-mobile-151117052058-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)









![DB技術[実践]入門を読んだ](https://cdn.slidesharecdn.com/ss_thumbnails/mysqlcasual-130224090642-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[AWS Summit 2012] クラウドデザインパターン#7 CDP キャンペーンサイト編 (Wordpress)](https://cdn.slidesharecdn.com/ss_thumbnails/aws-summit-cdp-07-121002233247-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























