Downloaded 176 times






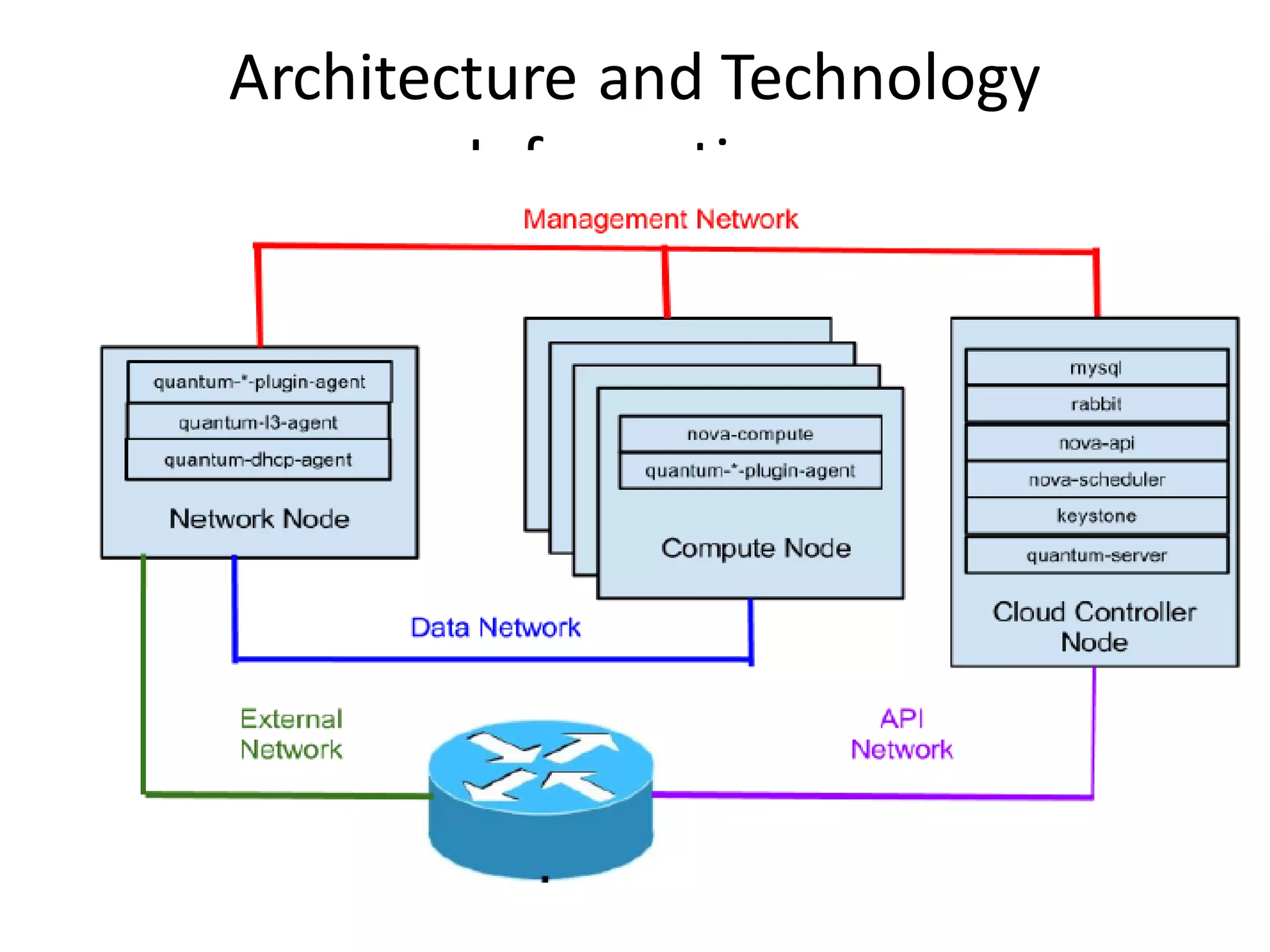
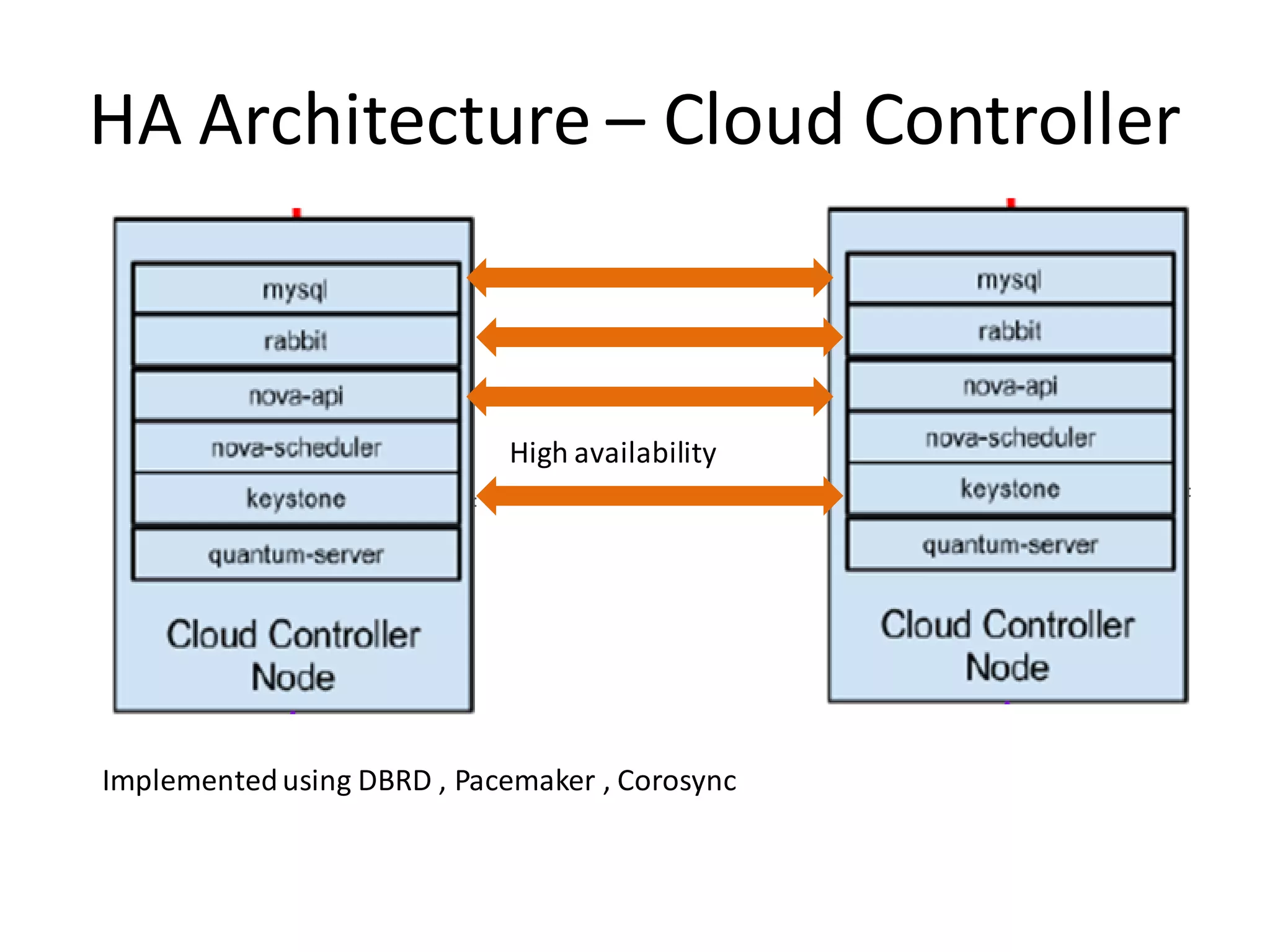
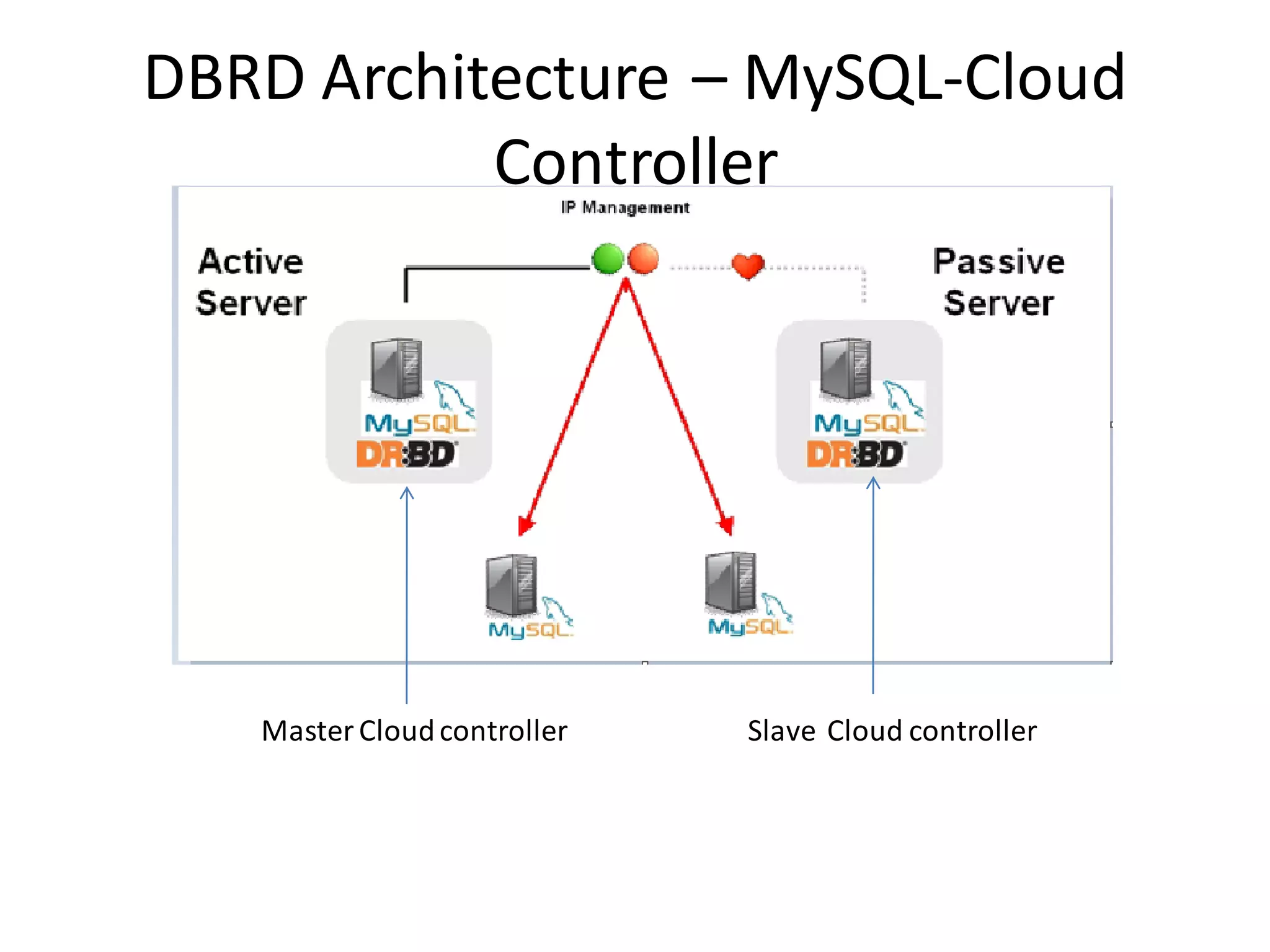
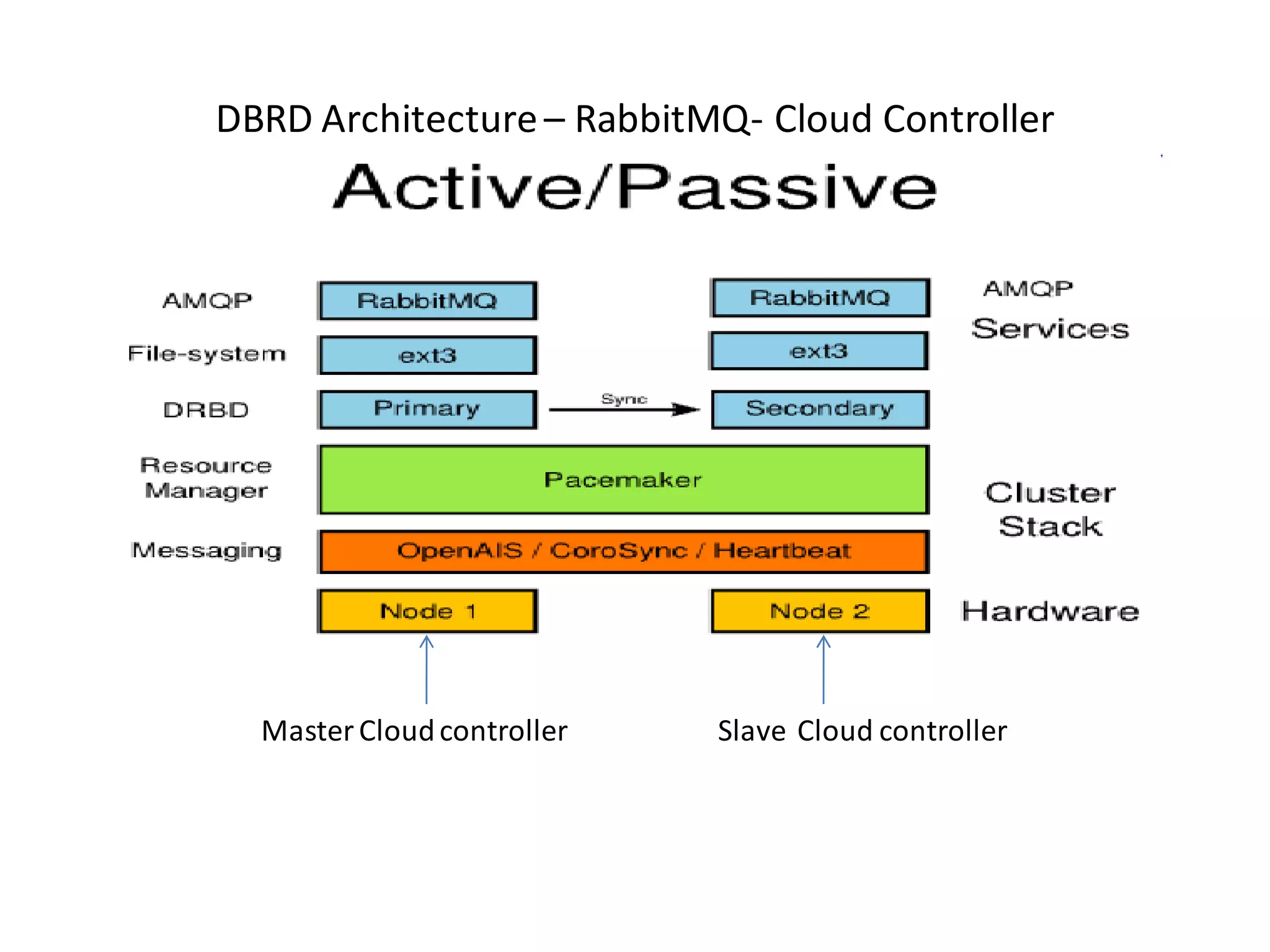
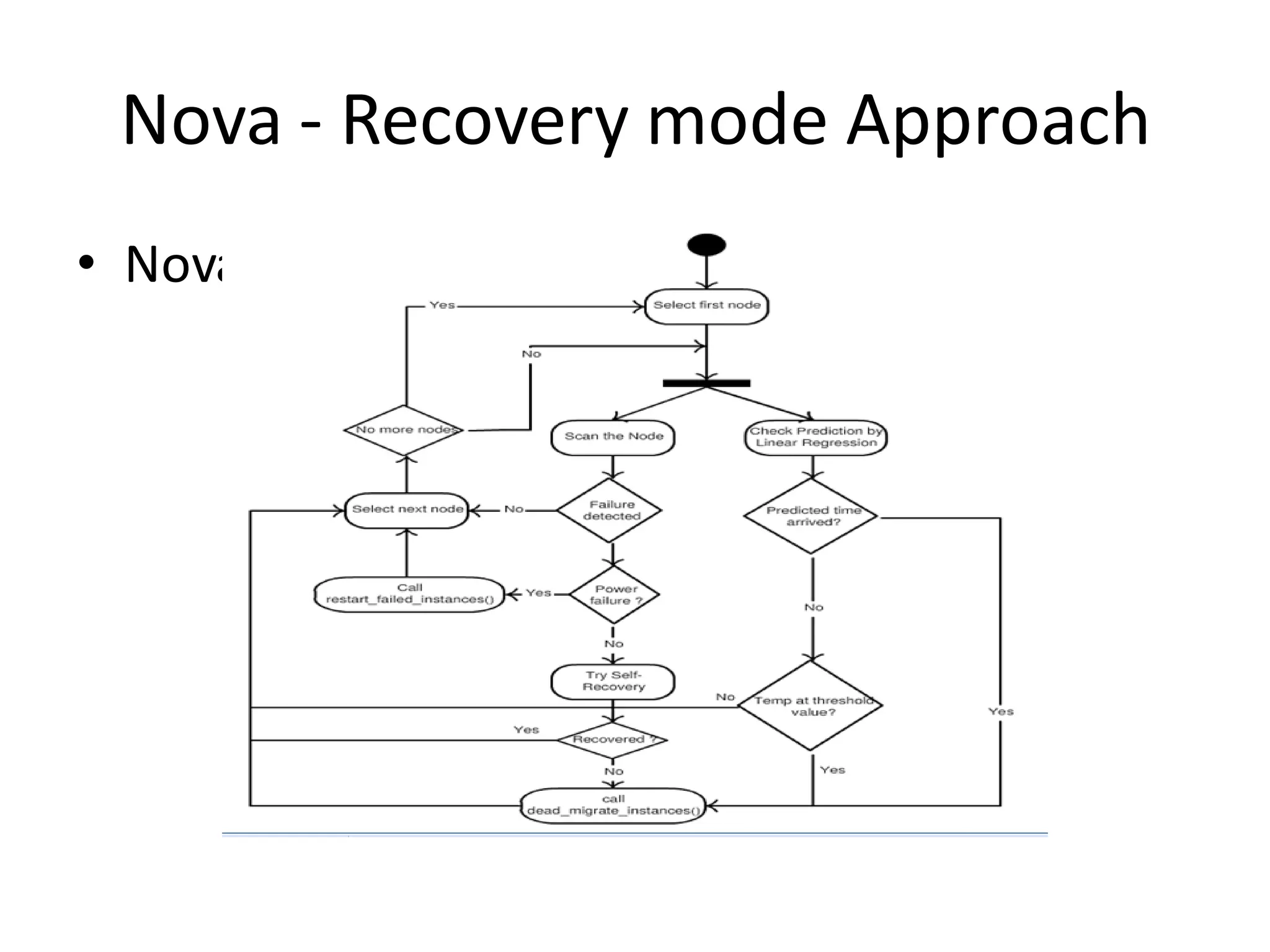
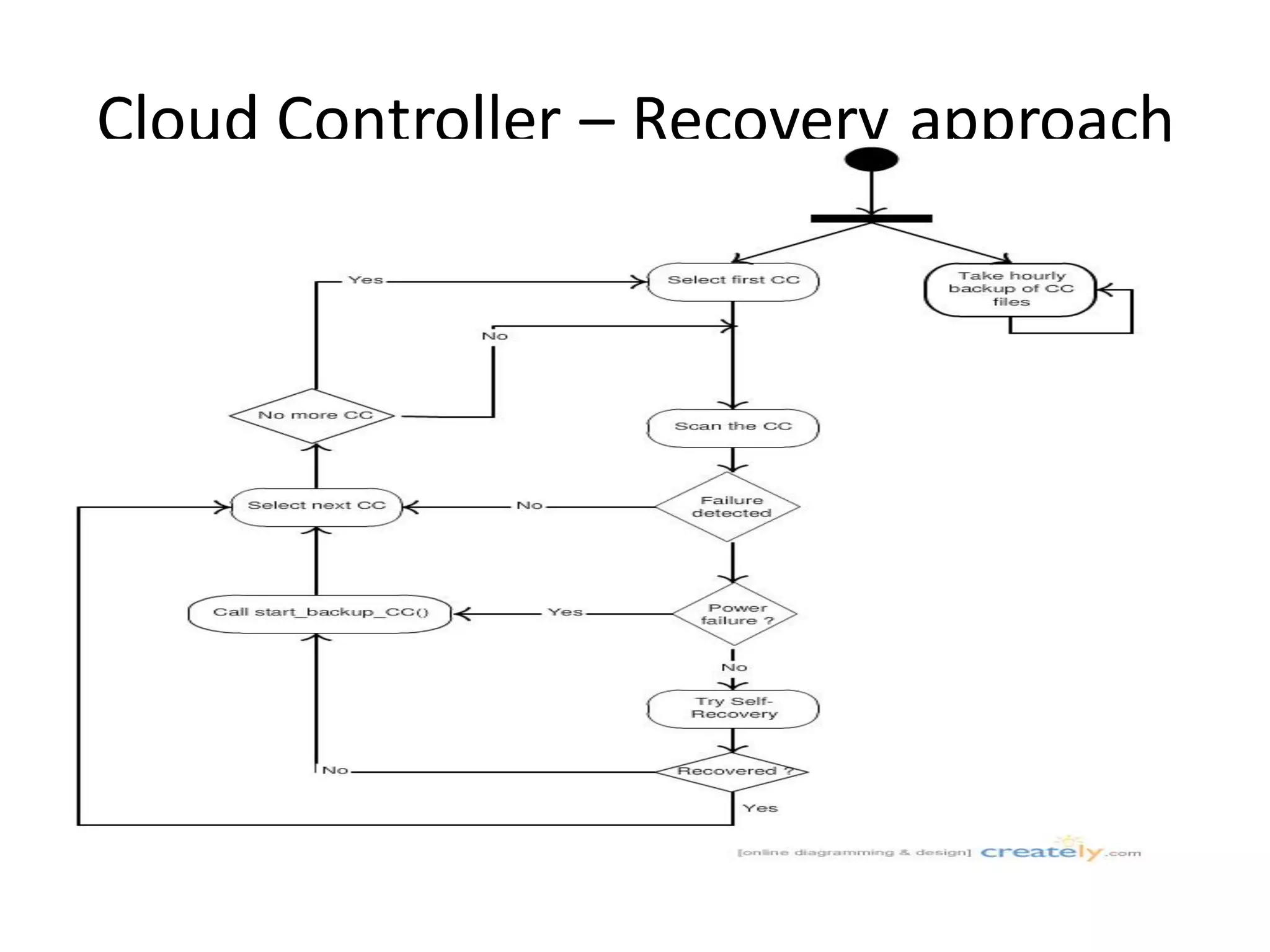

This document discusses building a fault tolerant and highly available architecture for OpenStack. It proposes: 1. A master-master cluster architecture for MySQL and session-level replication for RabbitMQ to provide high availability for the database and message broker components. 2. Disk-level replication using DBRD for Glance, Swift, and Cinder to provide redundancy at the storage level. 3. Ensuring high availability for networking and the Horizon dashboard. 4. Developing predictive and reactive models to detect failures in Nova, Swift, and compute instances and enable recovery of all components. The document recommends using Pacemaker for cluster-level management and Corosync for reliable messaging between cluster nodes.



































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













