Download to read offline


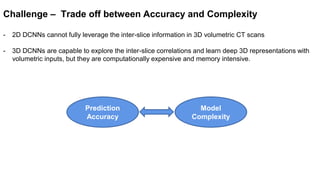


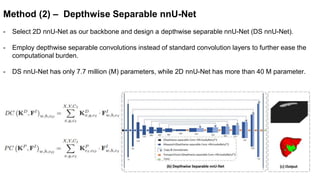






This document presents a novel deep learning framework for efficient liver and tumor segmentation using a multi-slice dense-sparse approach. It highlights the challenges of traditional 2D and 3D networks and introduces a lightweight depthwise separable NNU-Net that offers a significant reduction in parameters while improving accuracy. Extensive experiments validate the effectiveness of the proposed method in both segmentation accuracy and processing efficiency.




























![[IJCAI 2023] SemiGNN-PPI: Self-Ensembling Multi-Graph Neural Network for Effi...](https://cdn.slidesharecdn.com/ss_thumbnails/ijcai23slidesv21-230825071638-d61b8725-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IJCAI 2023 - Poster] SemiGNN-PPI: Self-Ensembling Multi-Graph Neural Network...](https://cdn.slidesharecdn.com/ss_thumbnails/semignnppiposterfinal-zzyv2-230818024445-6f69bd9e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IAIM 2023 - Poster] Label-efficient Generalizable Deep Learning for Medical...](https://cdn.slidesharecdn.com/ss_thumbnails/posteriaim-230807050327-c7b3356b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BMVC 2022 - Spotlight] DA-CIL: Towards Domain Adaptive Class-Incremental 3D ...](https://cdn.slidesharecdn.com/ss_thumbnails/0916spotlight-221108165737-dff72a87-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BMVC 2022] DA-CIL: Towards Domain Adaptive Class-Incremental 3D Object Detec...](https://cdn.slidesharecdn.com/ss_thumbnails/0916slides-221108165348-620eaec7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ICIP 2022] ACT-NET: Asymmetric Co-Teacher Network for Semi-Supervised Memory...](https://cdn.slidesharecdn.com/ss_thumbnails/1990-221030123438-d0ac6cdd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ICIP 2022] MMGL: Multi-Scale Multi-View Global-Local Contrastive learning fo...](https://cdn.slidesharecdn.com/ss_thumbnails/1311-221030123159-eabe0147-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ICIP 2022 - Poster] MMGL: Multi-Scale Multi-View Global-Local Contrastive le...](https://cdn.slidesharecdn.com/ss_thumbnails/poster1311-221030122927-fd74c2f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[MICCAI 2022] Meta-hallucinator: Towards Few-Shot Cross-Modality Cardiac Imag...](https://cdn.slidesharecdn.com/ss_thumbnails/presentation-copy-220925094724-ff51f7fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[EMBC 2022] Self-supervised Assisted Active Learning for Skin Lesion Segmenta...](https://cdn.slidesharecdn.com/ss_thumbnails/frbt95zhaoziyuan-220901164713-ee979d46-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ICME 2022] Adaptive Mean-Residue Loss for Robust Facial Age Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/icme2022858-copy-220901163731-39b6fba1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[MICCAI 2021] MT-UDA: Towards unsupervised cross-modality medical image segme...](https://cdn.slidesharecdn.com/ss_thumbnails/mt-udamiccai2021-220901163232-97bf56d1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[EMBC 2021] Hierarchical Consistency Regularized Mean Teacher for Semi-superv...](https://cdn.slidesharecdn.com/ss_thumbnails/embc211049-copy-220821155725-f6b849d6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ICIP 2020] SEA-Net: Squeeze-and-Excitation Attention Net for Diabetic Retino...](https://cdn.slidesharecdn.com/ss_thumbnails/presentationicip-220821154140-453da360-thumbnail.jpg?width=640&height=640&fit=bounds)
![[MICCAI 2021 - Poster] MT-UDA: Towards unsupervised cross-modality medical im...](https://cdn.slidesharecdn.com/ss_thumbnails/poster678-220821153313-833a0777-thumbnail.jpg?width=640&height=640&fit=bounds)



















