Download as PDF, PPTX



























![46
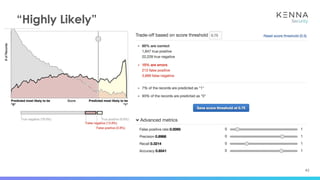
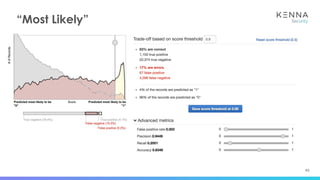
● CVE-2016-10372 - cpe:/o:eir:d1000_modem_firmware:
○ https://www.rapid7.com/db/modules/exploit/linux/http/tr064_ntpserver_cmdinject
● CVE-2017-18046 - cpe:/o:dasannetworks:h640x_firmware:2.77p1-1124
○ https://blogs.securiteam.com/index.php/archives/3552
● CVE-2017-8116 - cpe:/o:teltonika:rut900_firmware:00.03.265
○ https://labs.nettitude.com/blog/cve-2017-8116-teltonika-router-unauthenticated-re
mote-code-execution/
● CVE-2017-16228 - cpe:/a:dulwich_project:dulwich:0.18.4
○ [no exploit exists]
● CVE-2017-17946 - cpe:/a:novosoft:handy_password:4.9.3
○ [no exploit exists]
Machine Learning Has Side Benefits](https://image.slidesharecdn.com/untitledpresentation1-180815144247/85/Effective-Prioritization-Through-Exploit-Prediction-46-320.jpg)
![48
● CVE-2016-10372 - cpe:/o:eir:d1000_modem_firmware:
○ https://www.rapid7.com/db/modules/exploit/linux/http/tr064_ntpserver_cmdinject
● CVE-2017-18046 - cpe:/o:dasannetworks:h640x_firmware:2.77p1-1124
○ https://blogs.securiteam.com/index.php/archives/3552
● CVE-2017-8116 - cpe:/o:teltonika:rut900_firmware:00.03.265
○ https://labs.nettitude.com/blog/cve-2017-8116-teltonika-router-unauthenticated-re
mote-code-execution/
● CVE-2017-16228 - cpe:/a:dulwich_project:dulwich:0.18.4
○ https://twitter.com/jcran/status/1026533985630007296
● CVE-2017-17946 - cpe:/a:novosoft:handy_password:4.9.3
○ [no exploit exists]
Machine Learning Has Side Benefits](https://image.slidesharecdn.com/untitledpresentation1-180815144247/85/Effective-Prioritization-Through-Exploit-Prediction-48-320.jpg)



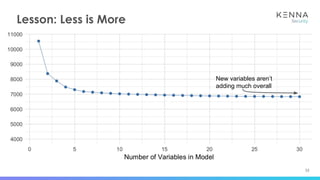
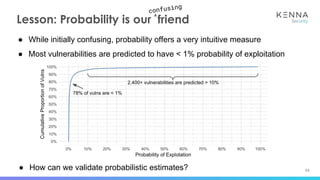
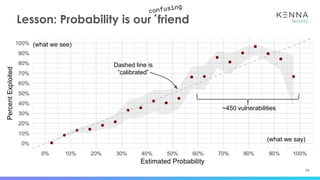
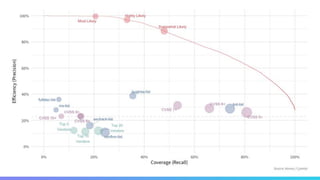


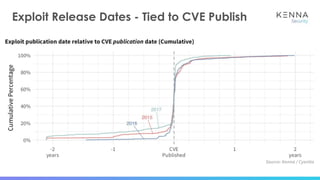
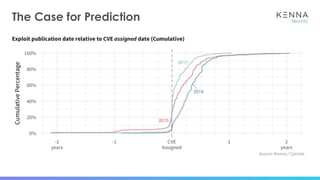
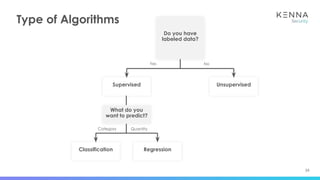
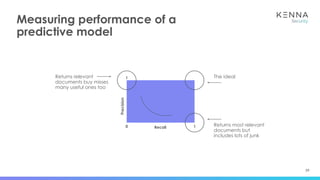
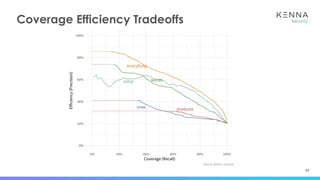
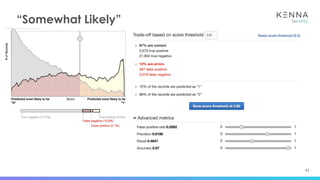
The document discusses using machine learning to predict which vulnerabilities are most likely to receive exploits in the future. It describes collecting data on vulnerabilities from CVE databases and observations of exploits and breaches. This data is then used to build a supervised classification model to predict the likelihood of future exploits. The model aims to help prioritize remediation of vulnerabilities that pose the greatest risks. Key challenges addressed include the increasing volume of vulnerabilities and shortening windows between disclosure and exploits.



































































