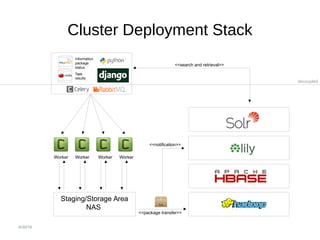
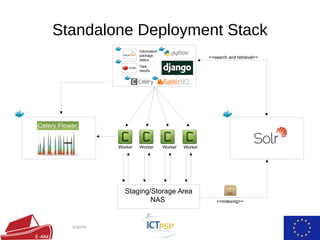
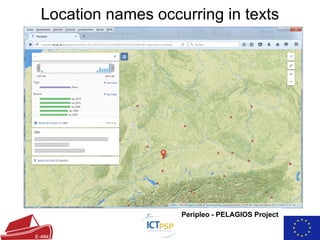
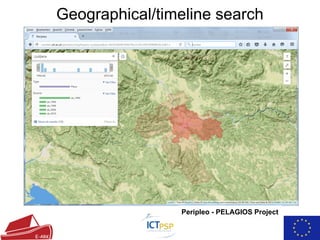
The document summarizes the European Archival Records and Knowledge (E-ARK) project, which developed an OAIS-compliant system for fast creation, search, and access of archival information packages. It describes the key components and functionality of the E-ARK reference implementation, including tools for ingest, archival storage, data management, access, and data mining of archived content. Current pilots of the E-ARK system are being used by several national archives for large-scale archiving and access of records.






![SIP
E-ARK Information Package (simplified)
representations
metadata
[schemas/documentation]
Structural metadata
Provenance metadata
Technical metadata
Descriptive metadata
SIP
DIP
DIP
Lifecycle
Metadata edits
Migrations
Add emulation info](https://image.slidesharecdn.com/3f75cccf-63b0-46e1-819b-0797d104740f-161005160201/85/E-ARK-iPRES2016-Bern-October-2016-6-320.jpg)































![Large Scale Image Forensics using Tika and Tensorflow [ICMR MFSec 2017]](https://cdn.slidesharecdn.com/ss_thumbnails/largescaleimageforensics-icmrmfsec2017-170608221906-thumbnail.jpg?width=640&height=640&fit=bounds)









































