Downloaded 11 times



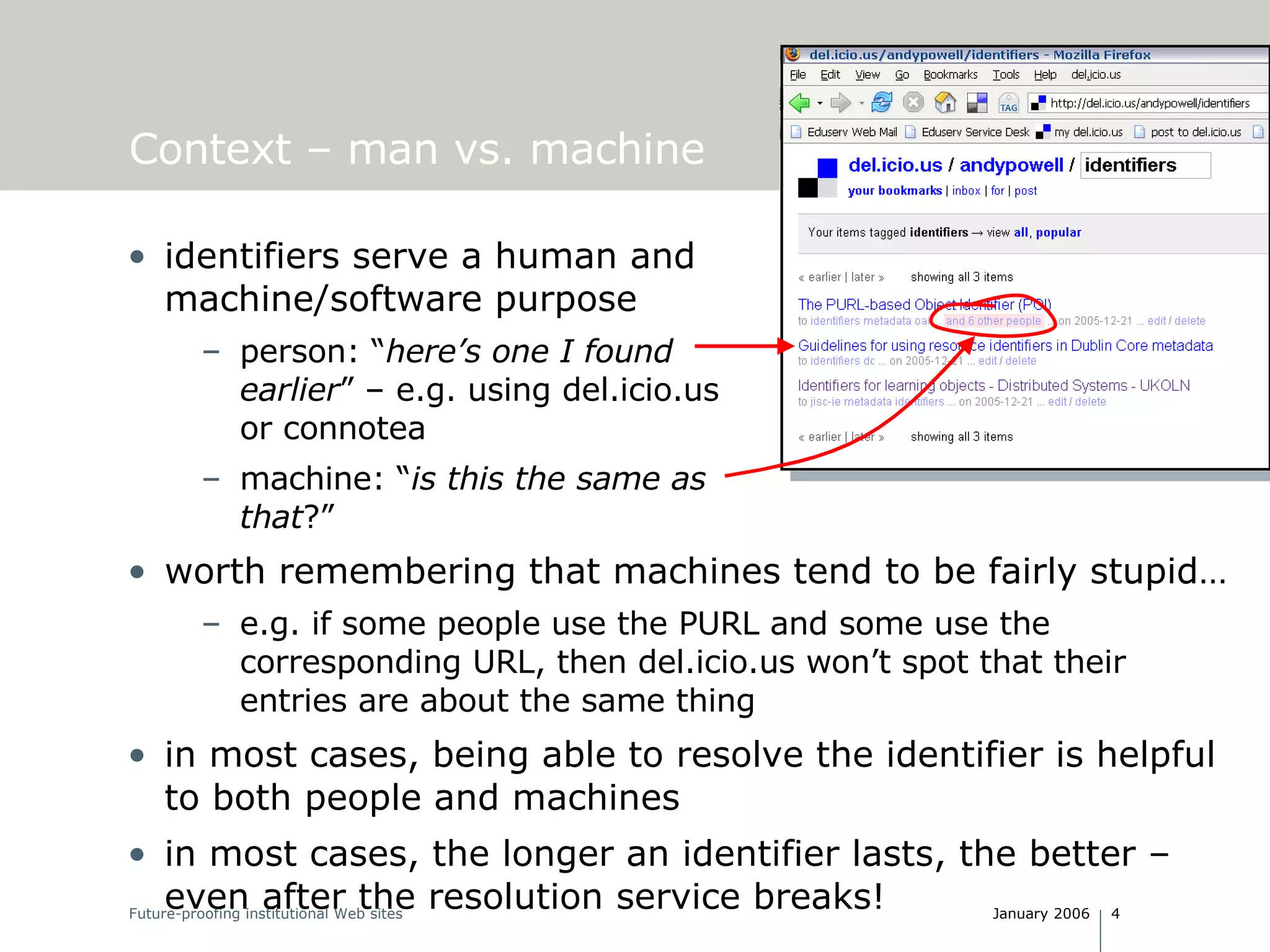










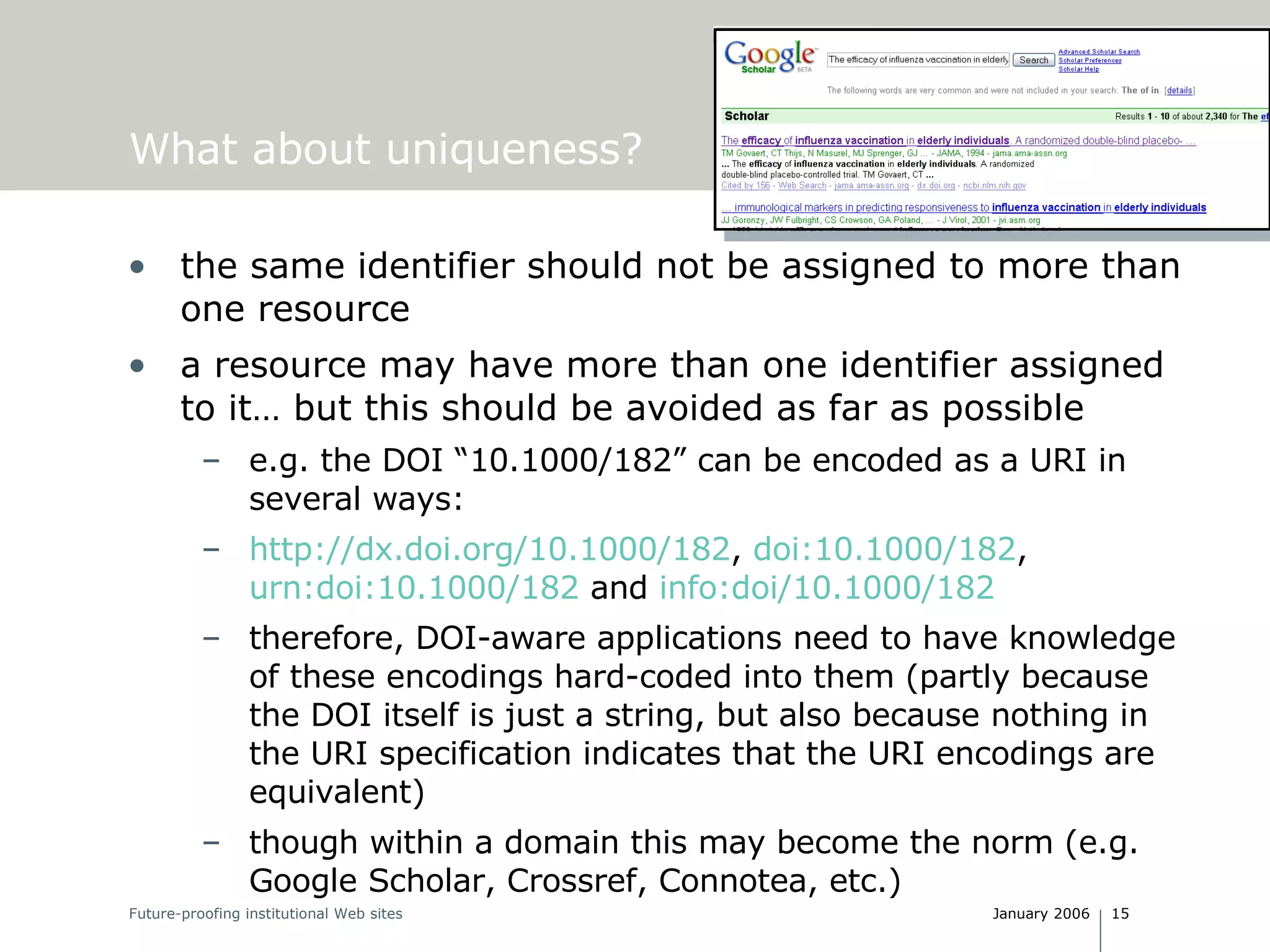






The document discusses the challenges and requirements of creating persistent identifiers for institutional web content, emphasizing the need for identifiers like URIs that remain reliable over time. It highlights the significance of resolution services and avoiding issues related to content accessibility amidst changing technologies and organizational structures. Recommendations include maintaining a commitment to identifier persistence and utilizing standardized systems while avoiding unnecessary complexity in URI structures.



































































