Downloaded 58 times









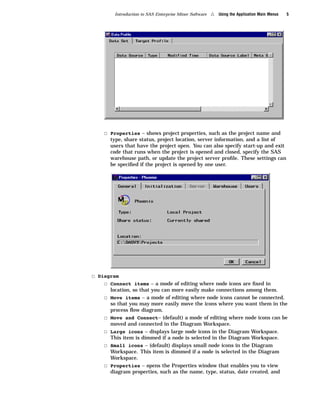








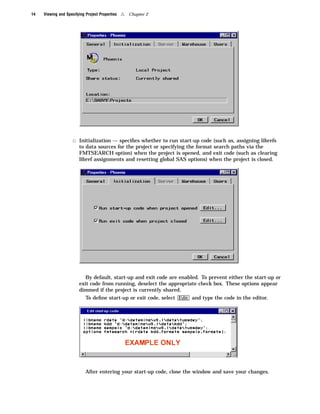
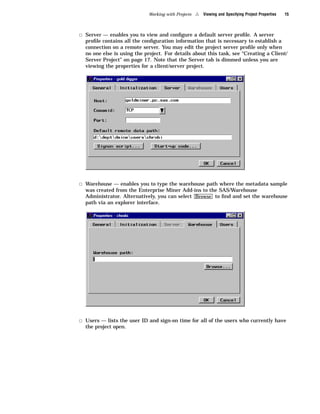
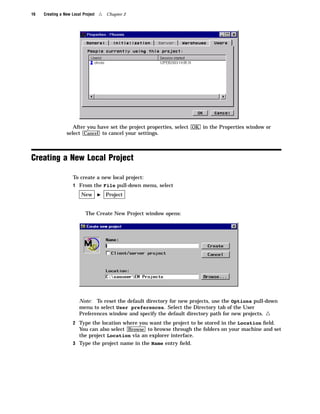

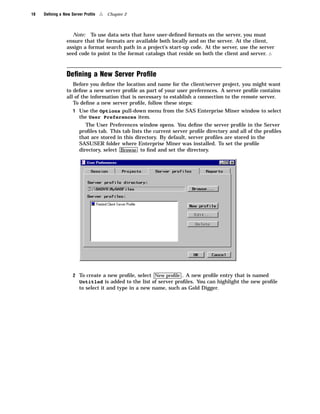
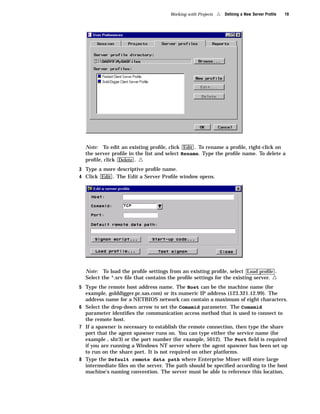
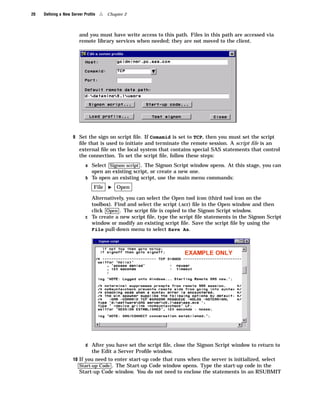
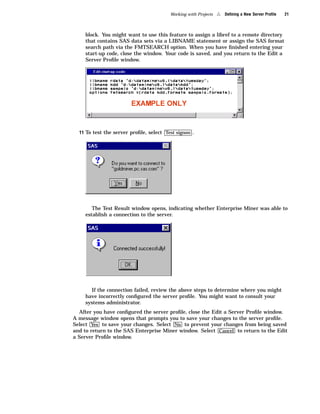

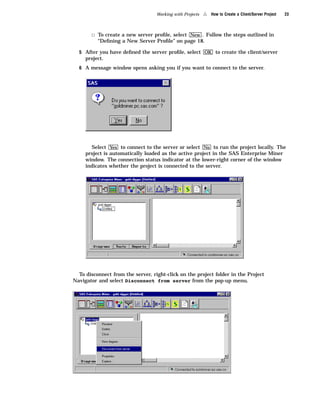

















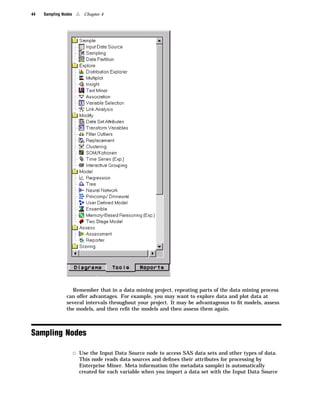














































































Here are the key points about the SAS Enterprise Miner application menus: - The File menu allows you to create, open, save, print, and delete projects and diagrams. It also contains options to exit Enterprise Miner. - The Edit menu contains options for copying, pasting, deleting, and cloning nodes. It also allows you to create subdiagrams and select all nodes. - The View menu lets you view messages, refresh the display, and change the level of a diagram. - The Options menu contains preferences and properties options to configure projects and diagrams. - The Diagram menu contains options to change the editing mode (connect, move, or both) and icon size. It also allows




























































