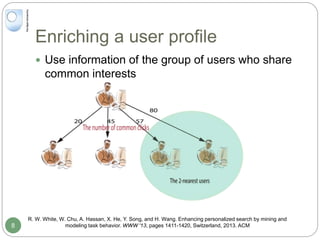
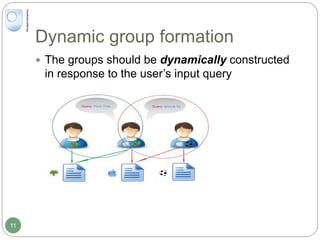
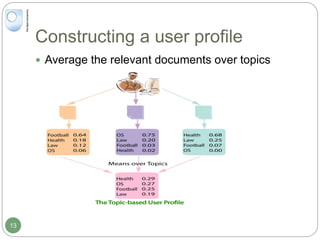
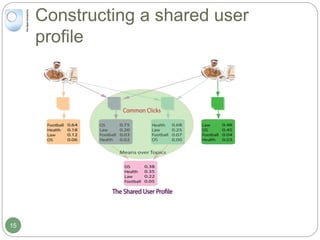
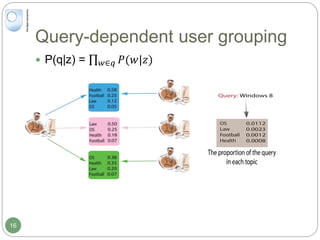
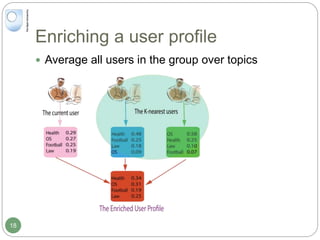
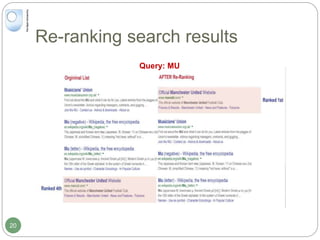
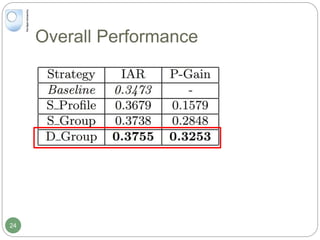
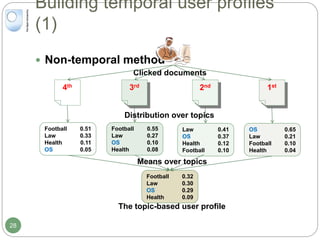
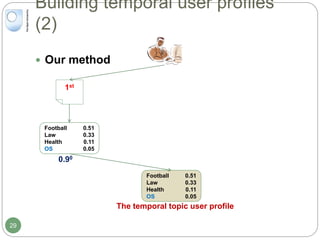
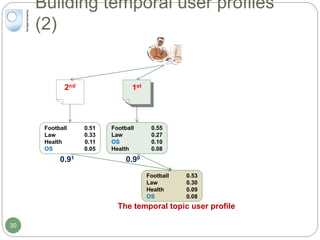
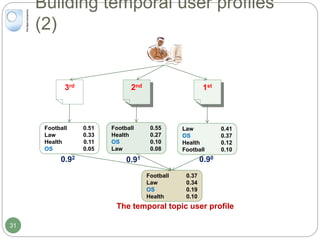
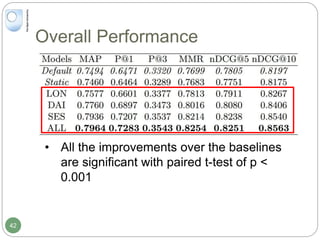
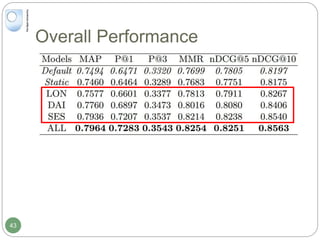
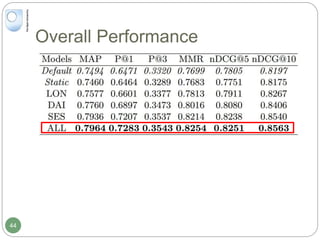
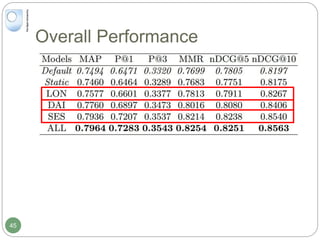
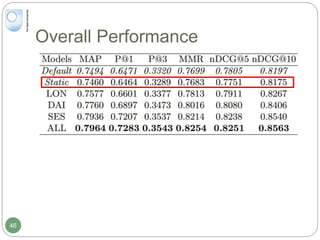
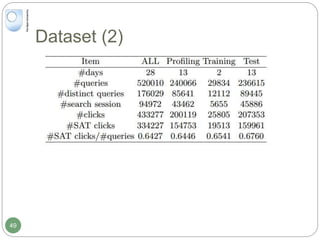
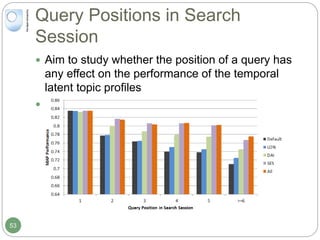
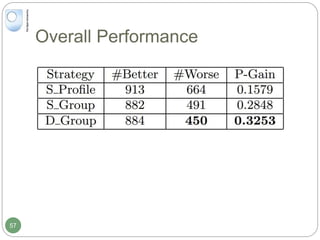
The document discusses dynamic user profiling for search personalization. It begins by describing classical search systems that return the same results for a given query regardless of individual user preferences. The research aims to enrich user profiles through dynamic group formation and temporal awareness to improve search personalization. For dynamic group formation, it constructs query-dependent user groups using latent Dirichlet allocation to model topic distributions. It then enriches individual user profiles by averaging over group profiles. For temporal profiles, it builds profiles that decay older document relevance over time to better reflect current interests. Evaluation on search logs shows the approaches outperform baselines by improving metrics like mean average precision.























![Re-ranking search results (2)
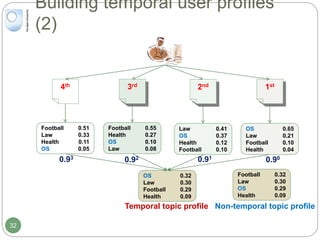
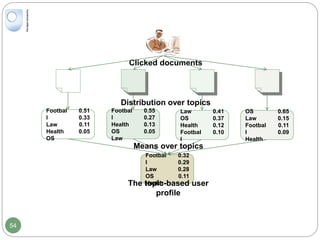
Personalised scores
Use Jensen-Shannon divergence (DJS[d||p] )
1 32
Health
Law
Football
OS
0.51
0.33
0.11
0.05
Football
Law
Health
OS
0.55
0.27
0.13
0.05
Football
OS
Health
Law
0.41
0.37
0.12
0.10
Football
Law
OS
Health
0.47
0.24
0.16
0.12
Returned documents (d)
The user profile (p)
36](https://image.slidesharecdn.com/20150408ucldynamicuserprofilingforsearchpersonalisation2-160702091011/85/Dynamic-User-Profiling-for-Search-Personalisation-36-320.jpg)
![Re-ranking search results (3)
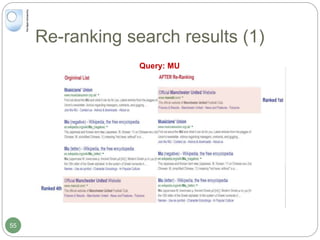
Re-ranking Features
Re-Ranking Algorithm: LambdaMART[1]
1. C. J. Burges, et al., Learning to rank with non-smooth cost functions. In NIPS’2007.
Feature Description
Personalised Features
LongTermScore Personalised score between document and long-term
profile
DailyScore Personalised score between document and daily profile
SessionScore Personalised score between document and session
profile
Non-personalised Features
DocRank Rank of document on original returned list
QuerySim Cosine similarity score between current and previous
queries
QueryNo Total number of queries that have been submitted in the
current search session (included the current query)
37](https://image.slidesharecdn.com/20150408ucldynamicuserprofilingforsearchpersonalisation2-160702091011/85/Dynamic-User-Profiling-for-Search-Personalisation-37-320.jpg)



















































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)





![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)






