Download to read offline





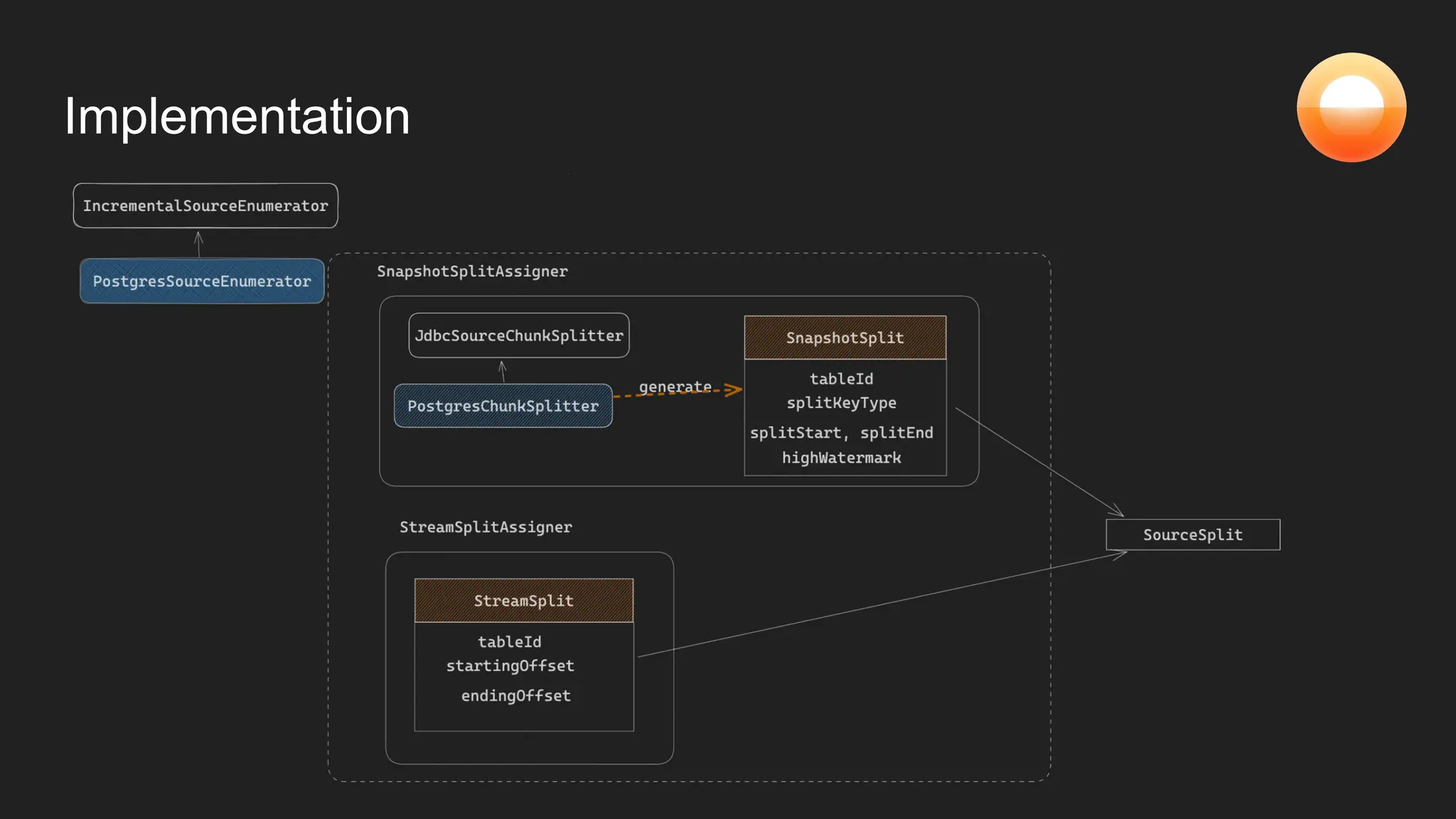







![Postgres
CDC source
[snapshot
mode]
Postgres
CDC source
[live mode]
Reconcile](https://image.slidesharecdn.com/bs73-20230927-cur23-mengxial-adv1final-231026162851-8ffb7676/75/Dynamic-Change-Data-Capture-with-Flink-CDC-and-Consistent-Hashing-24-2048.jpg)
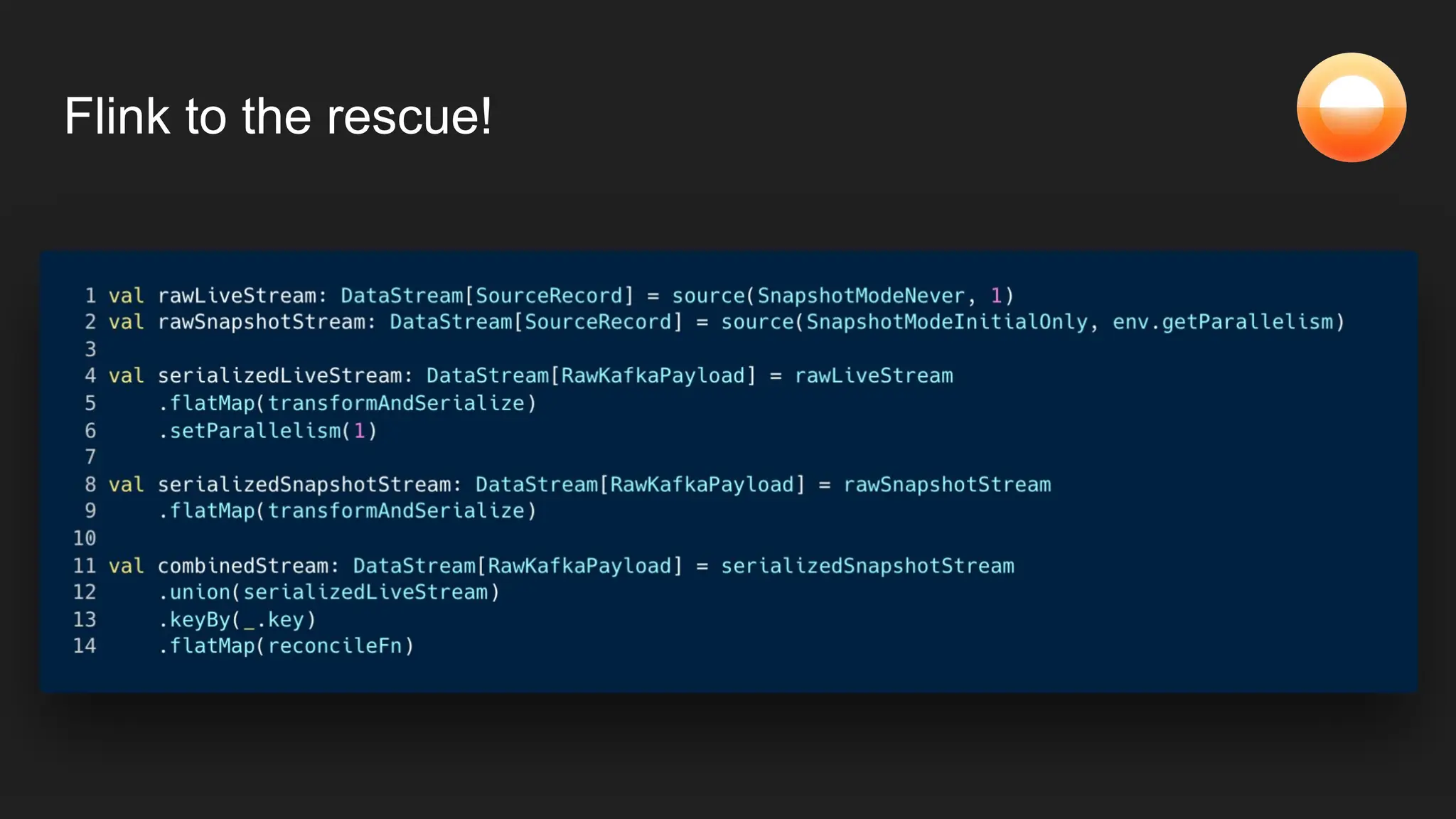
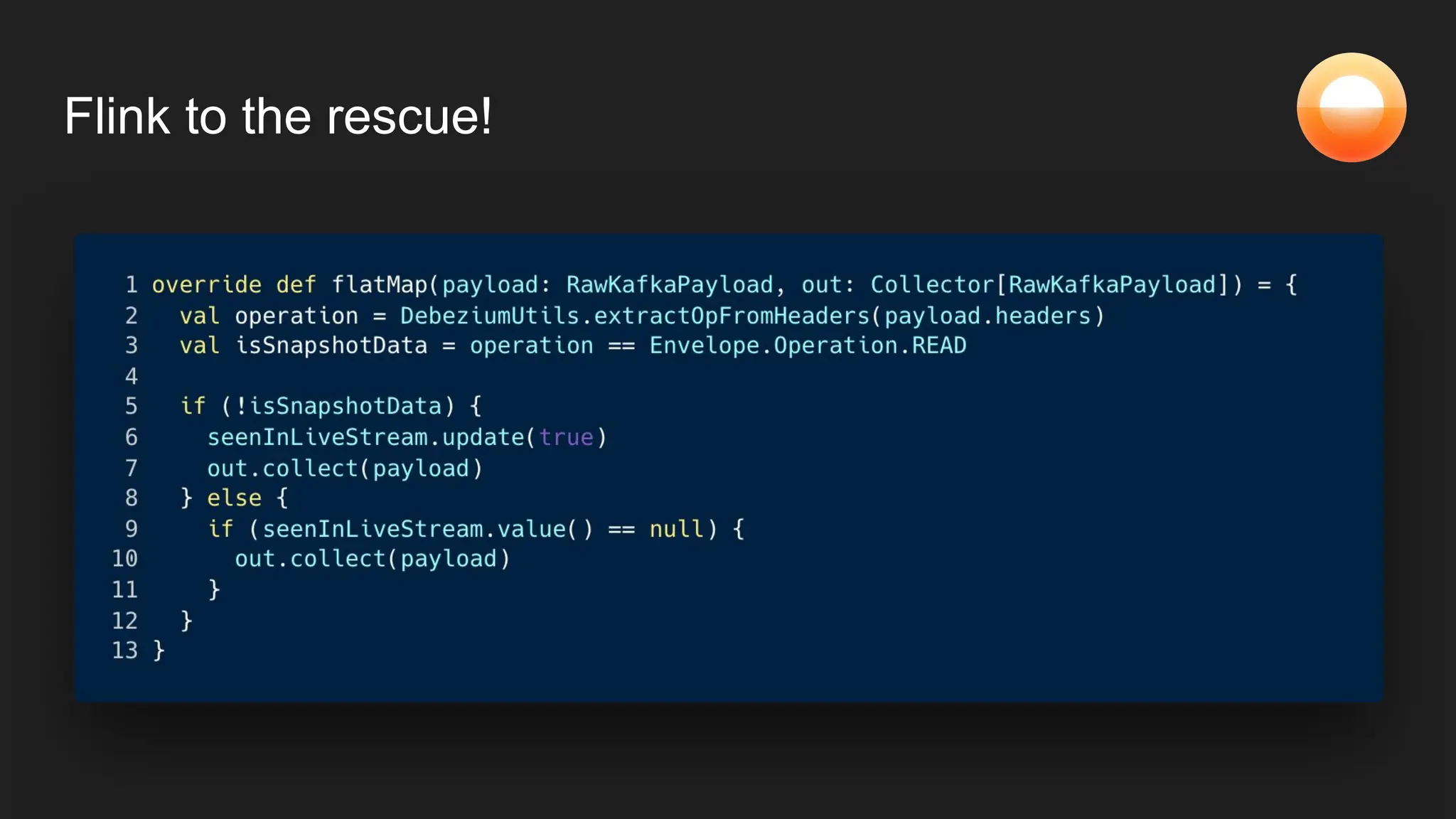

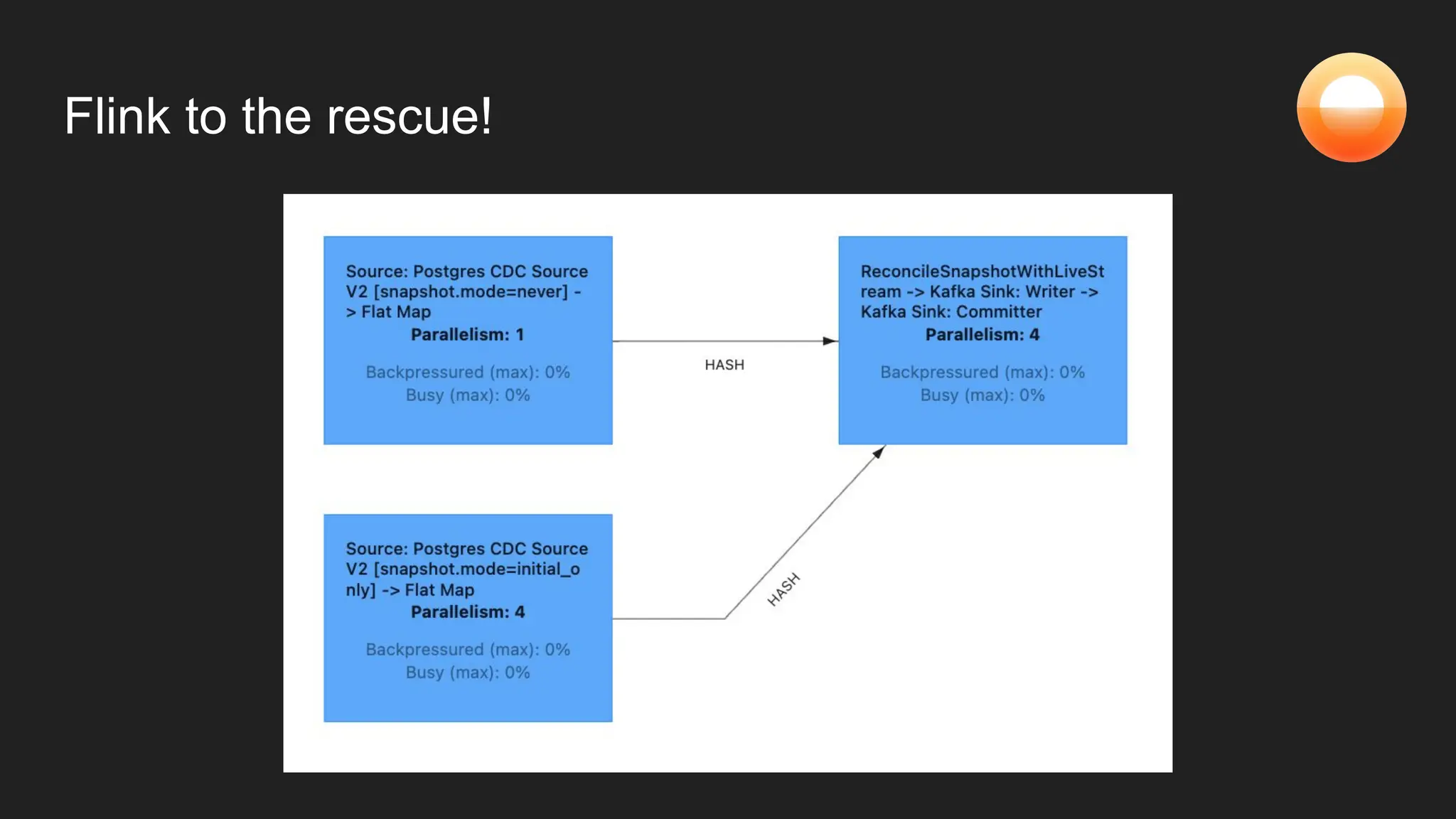






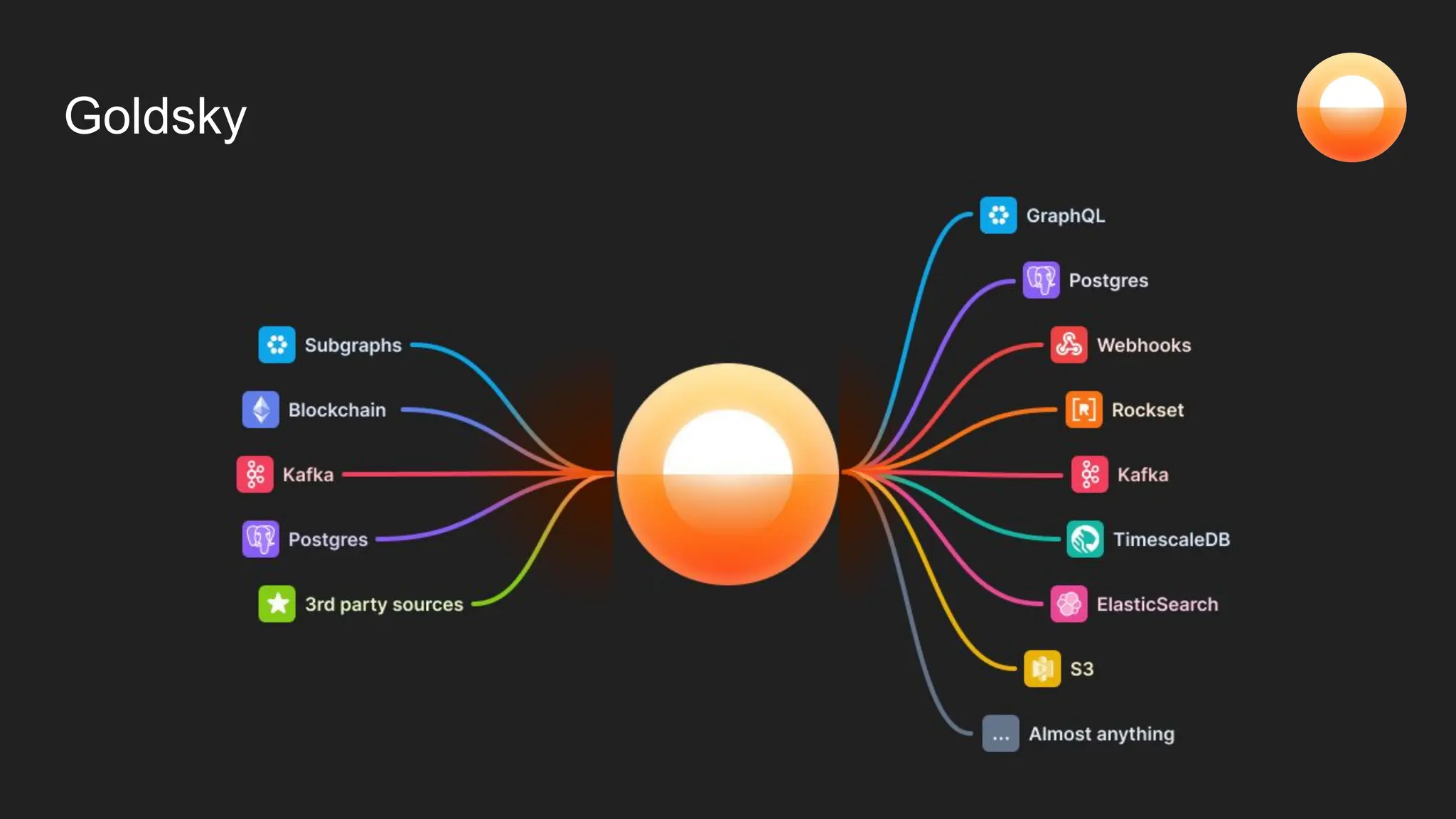
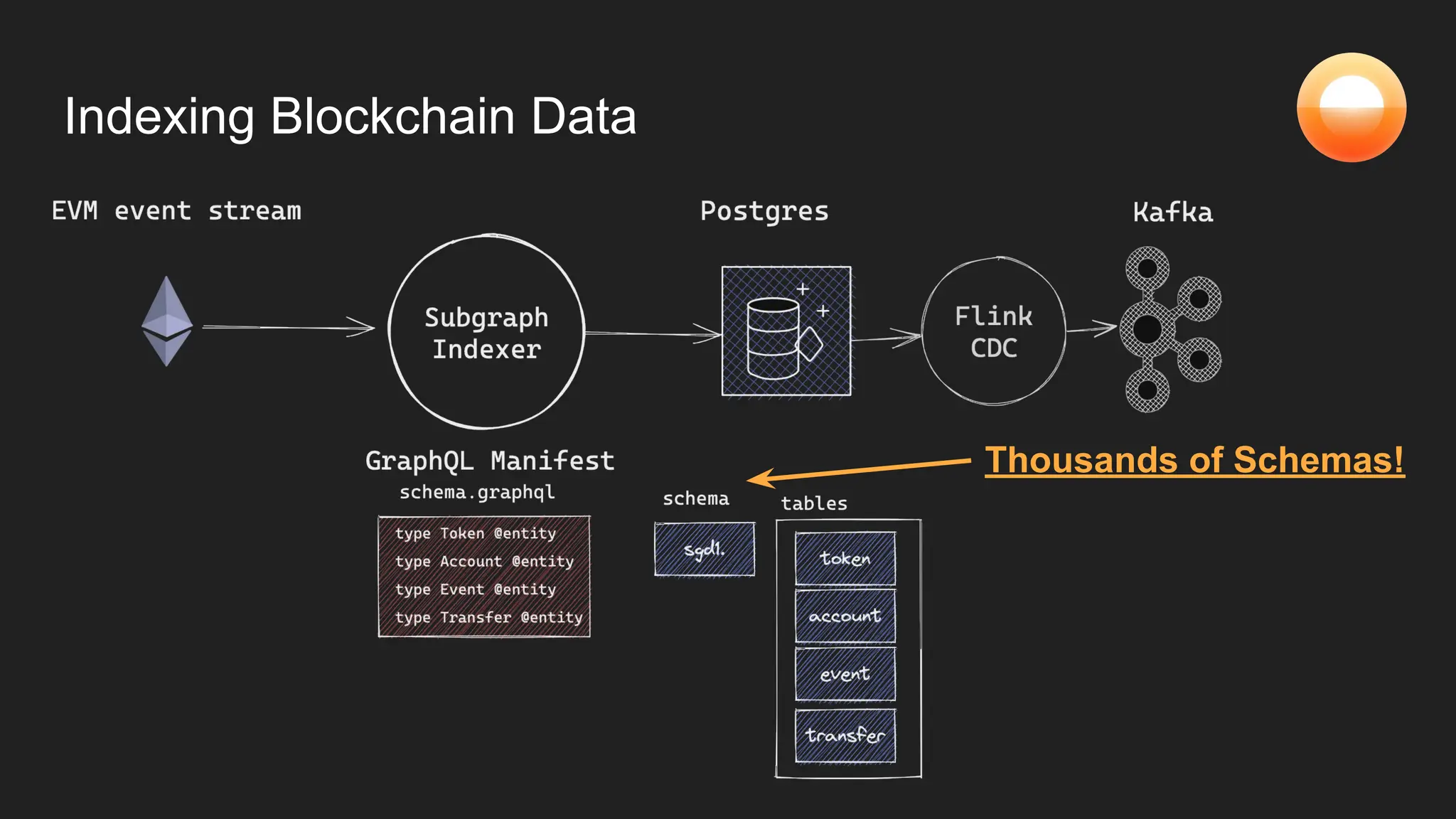
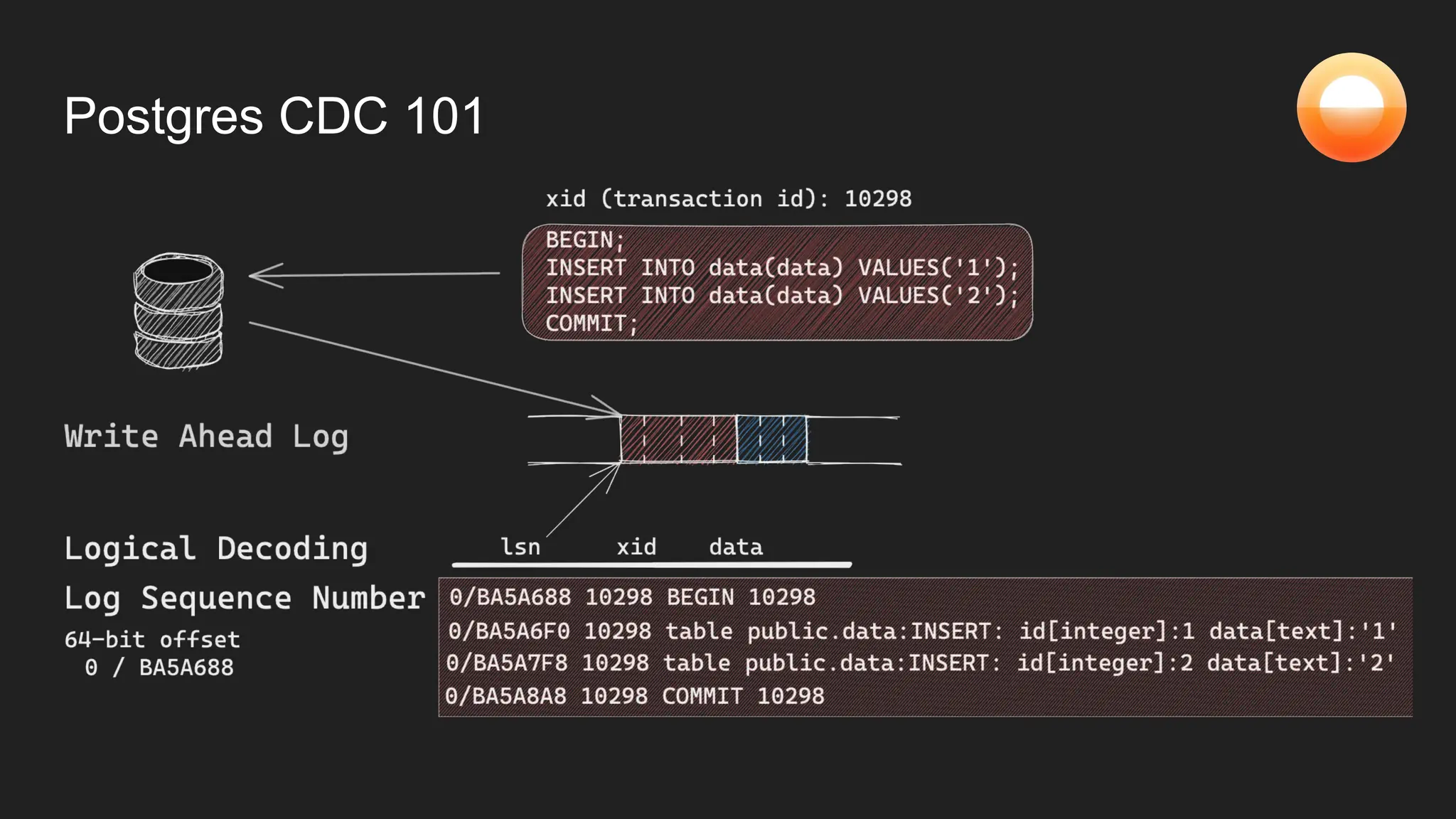
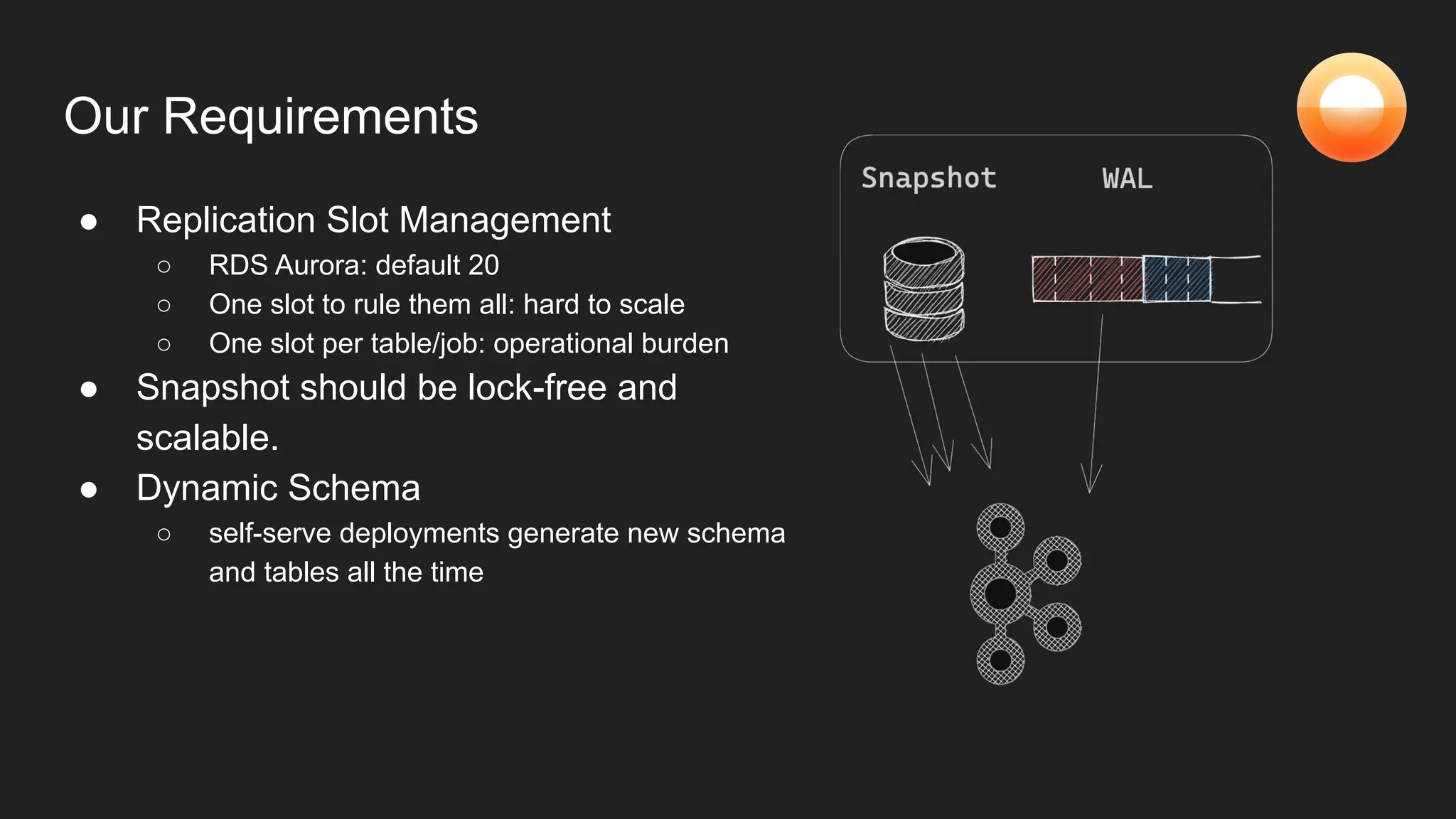
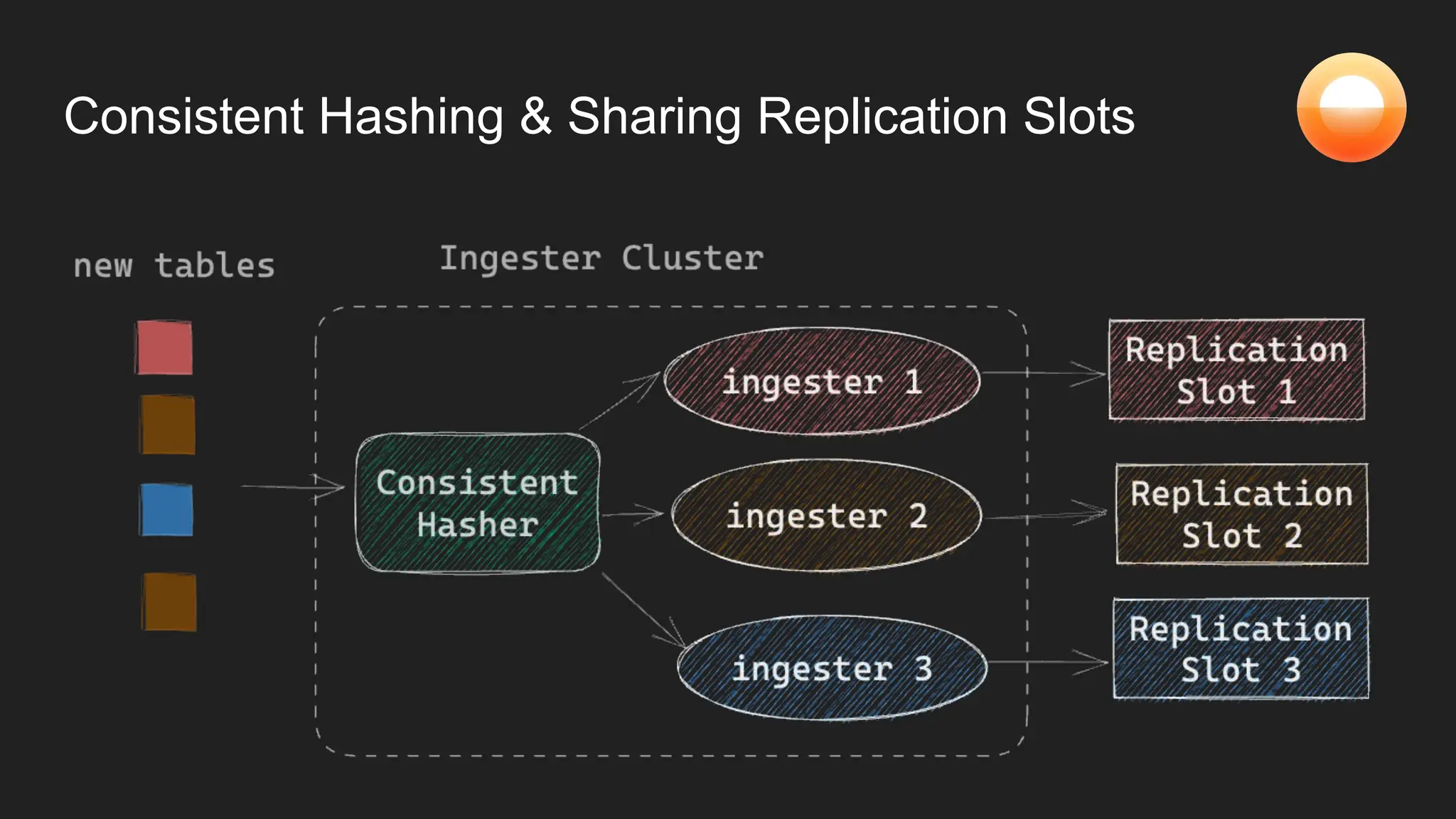
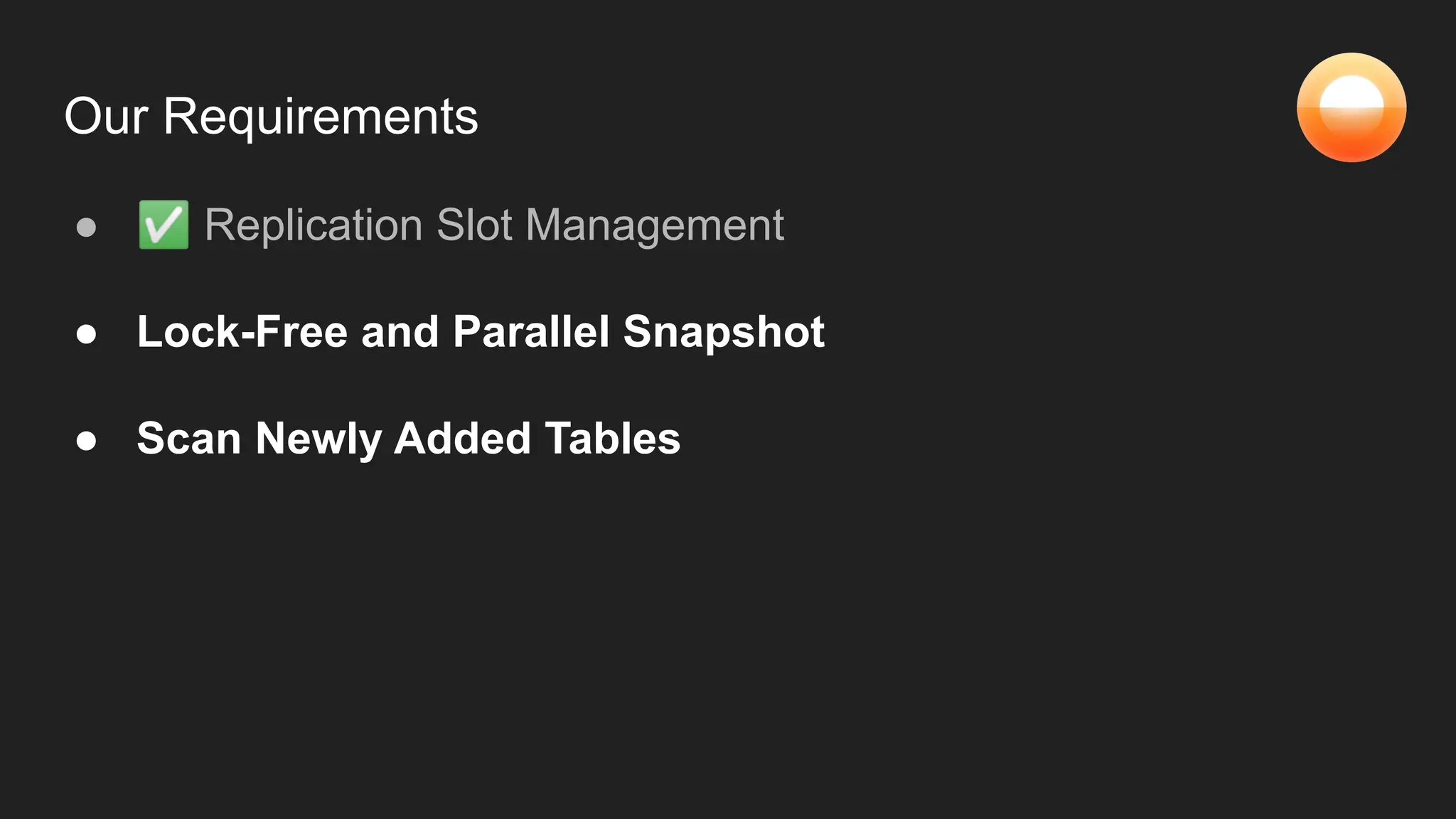
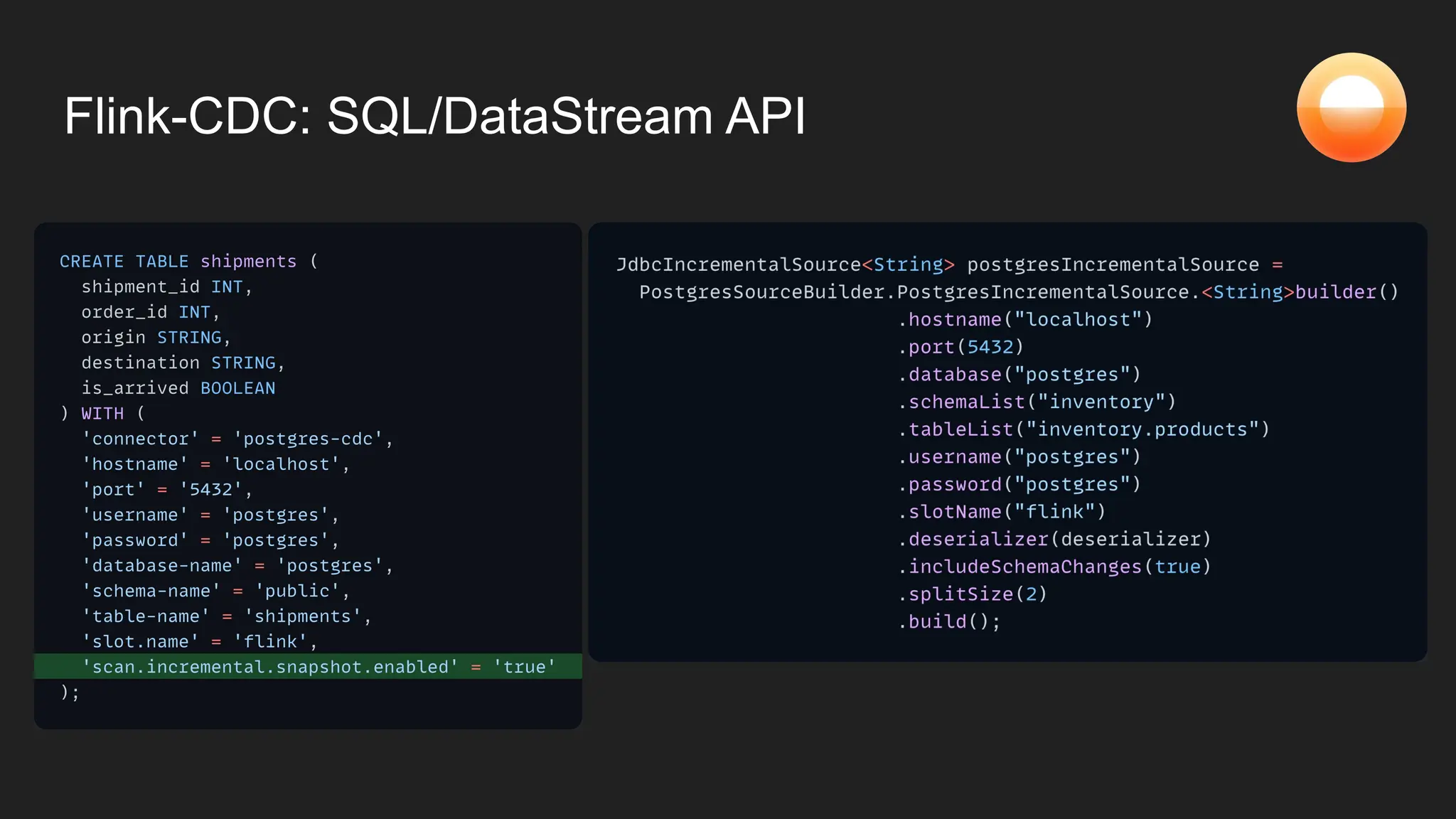
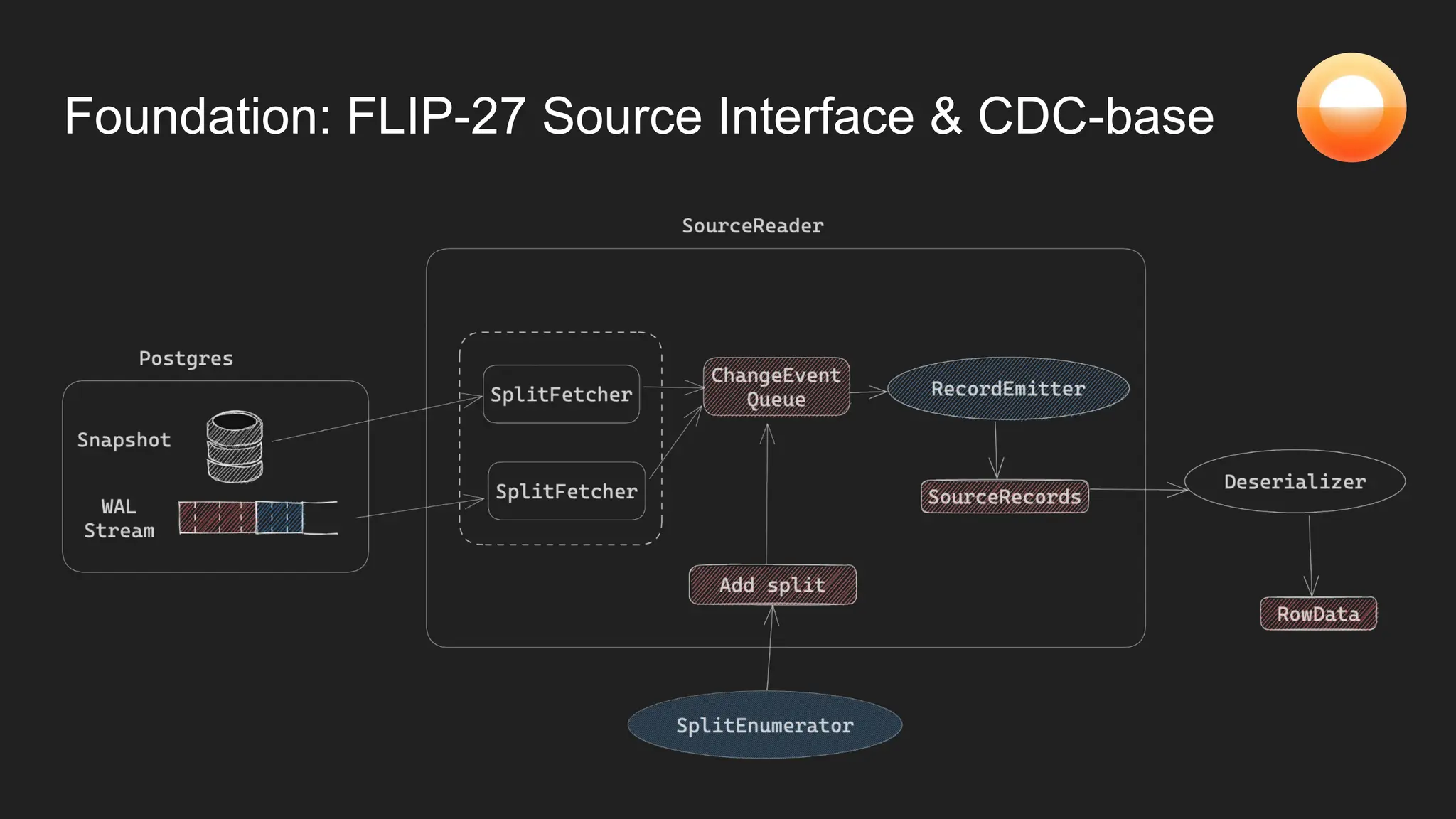
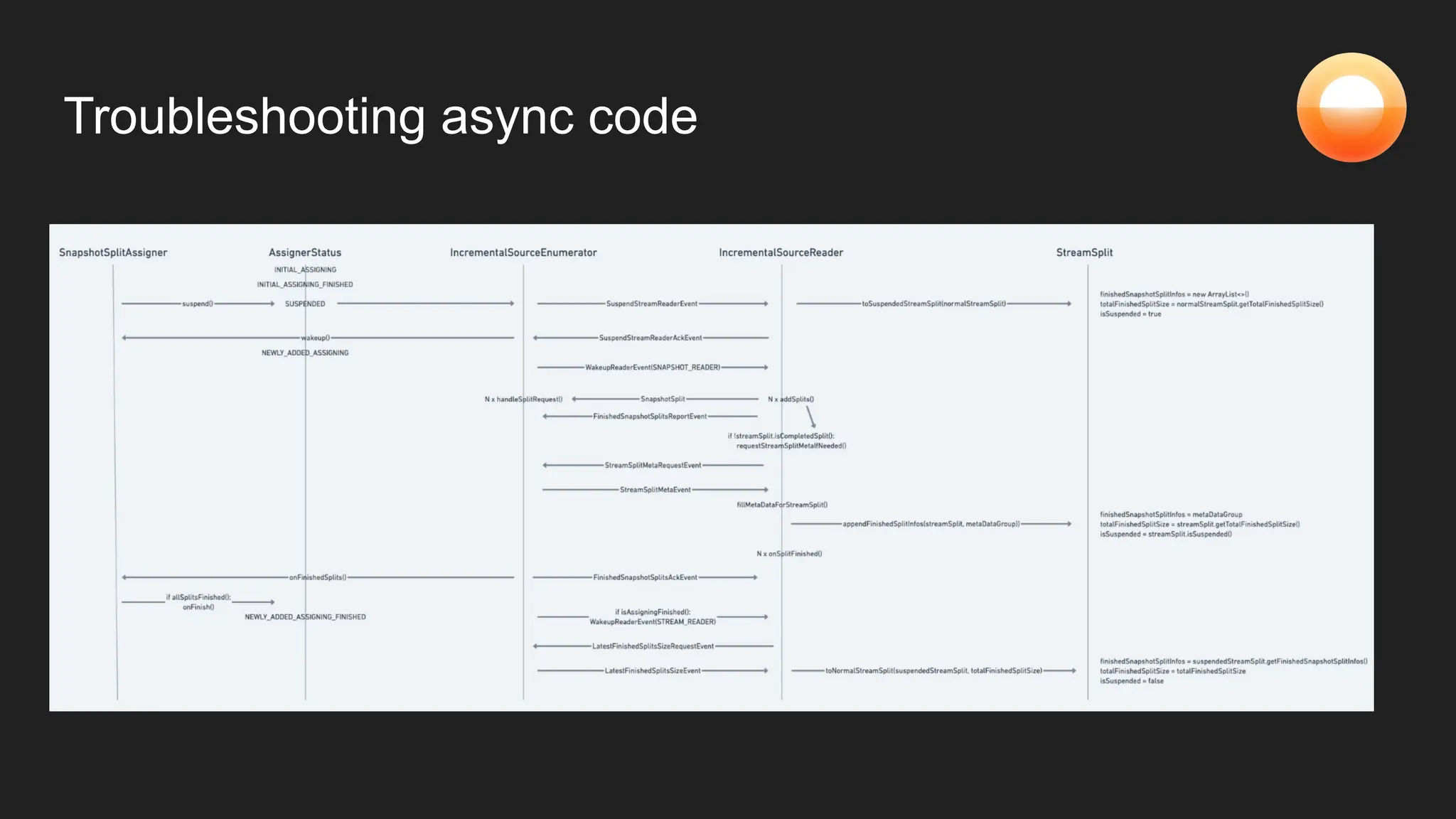
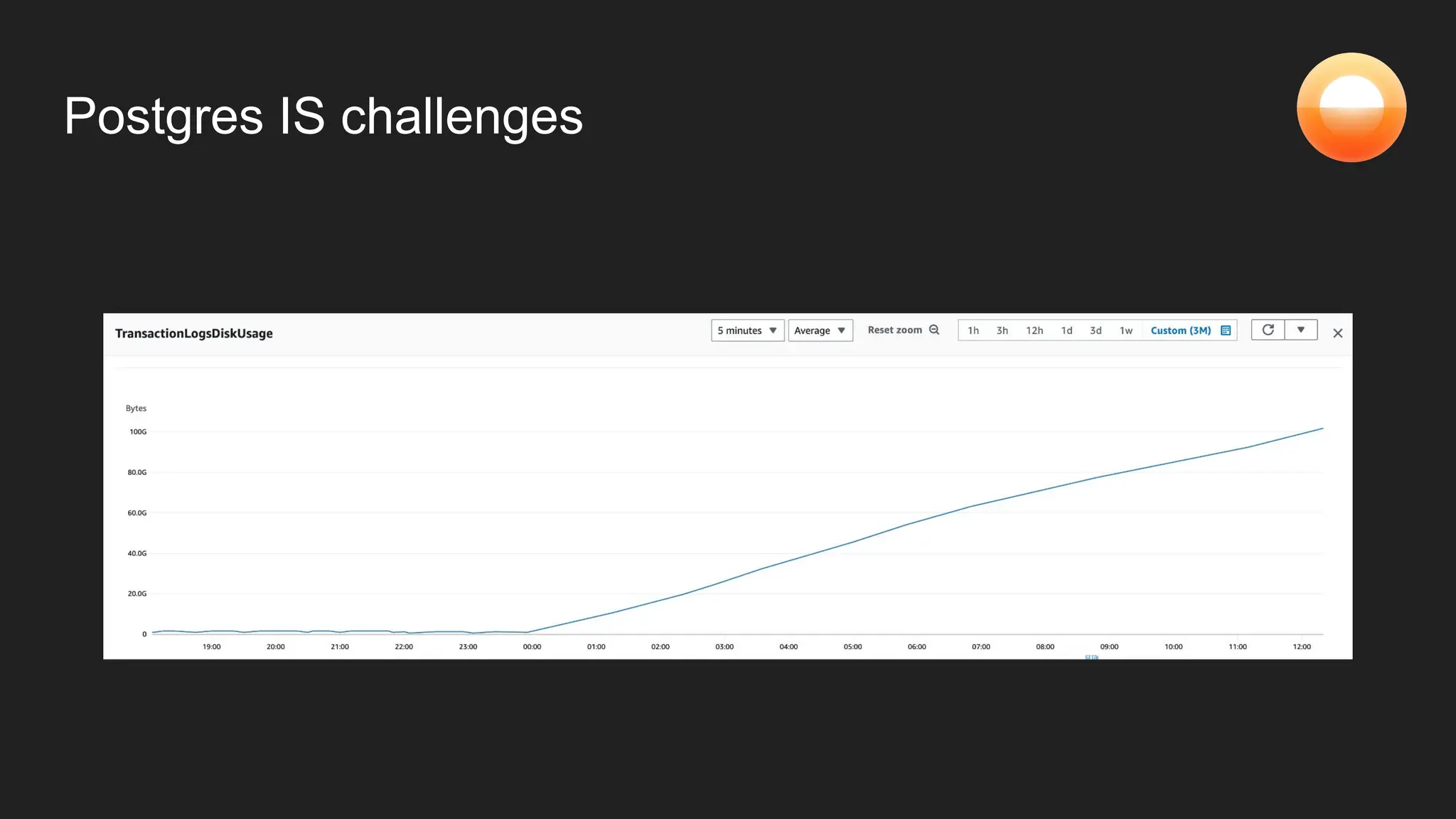
The document discusses Goldsky's implementation of dynamic change data capture using Flink CDC and consistent hashing to manage PostgreSQL replication slots effectively. It outlines the challenges associated with snapshot tasks and backfills, while presenting improved algorithms for incremental snapshotting with Flink. Key takeaways highlight the importance of proper monitoring, resource management through consistent hashing, and Flink's flexibility in building custom workflows.




































![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)


















































