Download to read offline


















![29
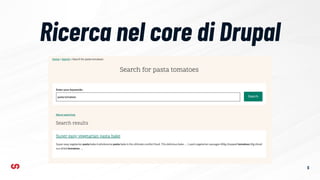
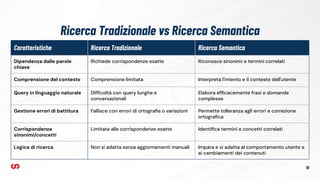
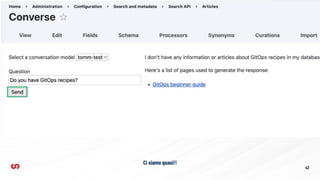
Configurazione dei campi
➔ Search API Typesense definisce un set di
nuovi tipi di campo, è obbligatorio utilizzarli
quando si indicizzano i dati su Typesense
➔ I tipi di campo supportati da Typesense sono:
◆ string
◆ string[]
◆ int32
◆ int32[]
◆ int64
◆ int64[]
◆ float
◆ float[]
◆ bool
◆ bool[]](https://image.slidesharecdn.com/tomm2024-aietypesensecomeintegrarelaricercasemanticaindrupal-241122090702-37d0d65f/85/Talks-on-my-machine-Drupal-AI-e-Typesense-come-integrare-la-ricerca-semantica-29-320.jpg)

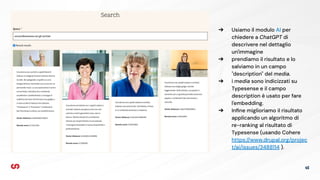
![➔ Gli Embeds vengono generati utilizzando un LLM (sia
localmente che con un provider remoto, come
OpenAI)
➔ Gli Embeds vengono salvati in un campo float[]
denominato embedding
➔ Il contenuto dei campi embedding viene
concatenato insieme e poi suddiviso in blocchi detti
chunks
➔ È possibile configurare la dimensione dei chunks e la
sovrapposizione tra chunks consecutivi
Abilitare la ricerca Semantica
31](https://image.slidesharecdn.com/tomm2024-aietypesensecomeintegrarelaricercasemanticaindrupal-241122090702-37d0d65f/85/Talks-on-my-machine-Drupal-AI-e-Typesense-come-integrare-la-ricerca-semantica-31-320.jpg)
![Ricerca Semantica
curl 'http://localhost:8108/multi_search'
-H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}"
-X POST
-d '{
"searches": [
{
"q": "device to type things on",
"query_by": "embedding",
"collection": "products",
"prefix": "false",
"exclude_fields": "embedding",
"per_page": 1
}
]
}'
32
➔ Typesense genererà l’embedding
per la chiave di ricerca e
utilizzerà la similarità del coseno
per trovare documenti simili
➔ Di solito vogliamo escludere il
campo di embedding dai risultati
perché è solo un enorme vettore
di numeri float](https://image.slidesharecdn.com/tomm2024-aietypesensecomeintegrarelaricercasemanticaindrupal-241122090702-37d0d65f/85/Talks-on-my-machine-Drupal-AI-e-Typesense-come-integrare-la-ricerca-semantica-32-320.jpg)


![➔ Il team di Typesense ha
sviluppato un adattatore per
rendere le chiamate API di
instantsearch compatibili con il
server Typesense
➔ Con Instantsearch, un client
(esempio un browser) comunica
direttamente con Typesense,
senza Drupal nel mezzo
➔ Importante: la chiave API deve
essere una che consenta solo
l'azione documents:search sulle
collections desiderate
instantsearch.js
import instantsearch from "instantsearch.js";
import { searchBox, hits } from "instantsearch.js/es/widgets";
import TypesenseInstantSearchAdapter from "typesense-instantsearch-adapter";
const typesenseInstantsearchAdapter = new TypesenseInstantSearchAdapter({
server: {
apiKey: "S6Af42wX9HmxF5Ar36ajNNawNywAYwGr",
nodes: [
{
host: "search-api-typesense.ddev.site",
port: "8108",
protocol: "https",
},
],
},
additionalSearchParameters: {
query_by: "body",
},
});
const searchClient = typesenseInstantsearchAdapter.searchClient;
37](https://image.slidesharecdn.com/tomm2024-aietypesensecomeintegrarelaricercasemanticaindrupal-241122090702-37d0d65f/85/Talks-on-my-machine-Drupal-AI-e-Typesense-come-integrare-la-ricerca-semantica-37-320.jpg)

![LLPhant
foreach ($attachments as $attachment) {
$file = $this->getPdfFileEntity
(
$field_storage
,
$attachment['target_id'],
);
if ($file === NULL) {
continue;
}
$reader = new FileDataReader(
DRUPAL_ROOT . $file->createFileUrl()
);
$documents = EmbeddingFormatter::formatEmbeddings(
$reader->getDocuments()
);
}
42
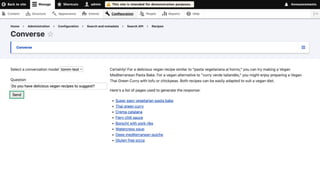
https://github.com/theodo-group/LLPhant
➔ FileDataReader, ci aiuta a
leggere il contenuto da file .pdf,
.docx e di testo.
➔ EmbeddingFormatter, ti
consente di aggiungere
informazioni preziose
nell'intestazione (come ad
esempio l'autore del documento,
la data del documento, ecc.)](https://image.slidesharecdn.com/tomm2024-aietypesensecomeintegrarelaricercasemanticaindrupal-241122090702-37d0d65f/85/Talks-on-my-machine-Drupal-AI-e-Typesense-come-integrare-la-ricerca-semantica-42-320.jpg)



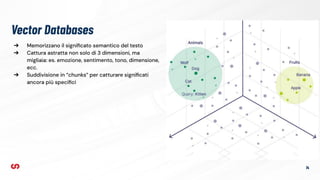
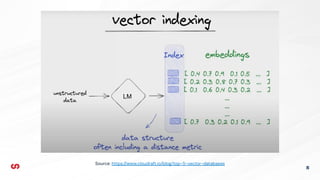
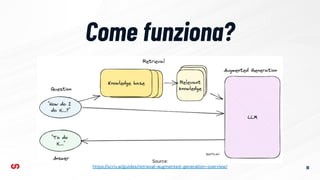
Il documento esplora come integrare la ricerca semantica in Drupal utilizzando Typesense, evidenziando le differenze tra ricerca tradizionale e semantica. Viene descritta l'importanza del retrieval-augmented generation (RAG) e il funzionamento dei database vettoriali per migliorare l'esperienza di ricerca. Infine, si presenta il modulo Search API Typesense per configurare la ricerca all'interno di Drupal.



















![[EH2023] SEO, AI e Machine Learning per l'eCommerce: la nuova SEO - Massimo F...](https://cdn.slidesharecdn.com/ss_thumbnails/5-231008181729-f79e7705-thumbnail.jpg?width=640&height=640&fit=bounds)



























