Downloaded 11 times






![Cosa “capisce” Google Cosa capiscono le macchine del Web attuale ”… blah blah blah blah blah blah blah blah blah blah <a href=“http://www.ex.org”> link </a> blah blah blah ...” Google ordina i risultati (in maniera sorprendente!) assumendo che il link abbia la seguente semantica [page] links [page] = popolarità conclusione: per “capire” non si intende il capire umano, ma solo l’elaborabilità da parte delle macchine Da Google technology: “The heart of our software is PageRank™ , a system for ranking web pages […] (that) relies on the uniquely democratic nature of the web by using its vast link structure as an indicator of an individual page's value .” http:// www.google.com /technology/](https://image.slidesharecdn.com/ic2008-introduzione-did-you-know-1204147073973941-5/85/IC2008-Introduzione-Did-You-Know-8-320.jpg)



![Esperienze di “ricerca” vissuta... Sto cercando un’immagine... Google Desktop: “lego escher” nessun risultato utile ...mi ricordo di averla trovata sul Web... Google Images: “lego escher” la trovo subito ...perchè non l’avevo trovata su Google Desktop? perchè l’immagine sul Web è un file con nome “relativity.jpg” Google Desktop: “relativity.jpg” eccola! [Soluzione: rinomino il file in “lego-escher-relativity.jpg”]](https://image.slidesharecdn.com/ic2008-introduzione-did-you-know-1204147073973941-5/85/IC2008-Introduzione-Did-You-Know-12-320.jpg)
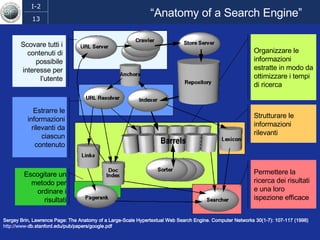
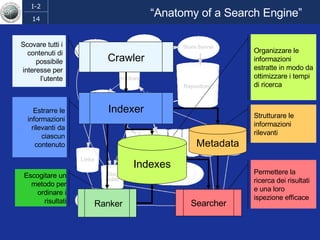
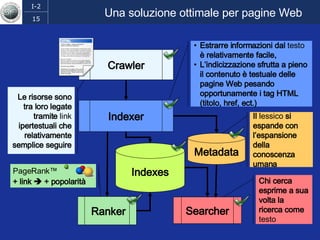
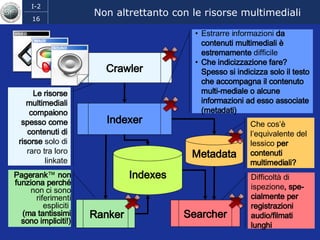
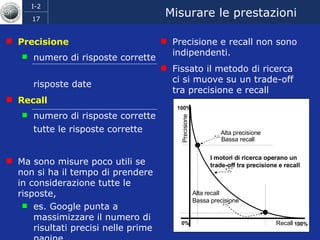







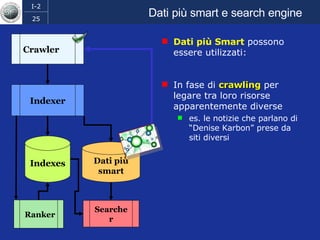
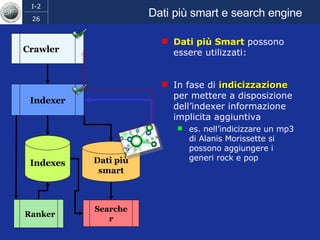
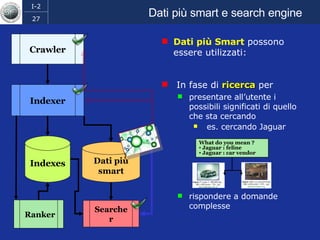

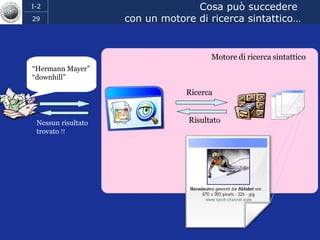
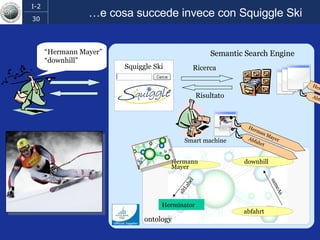
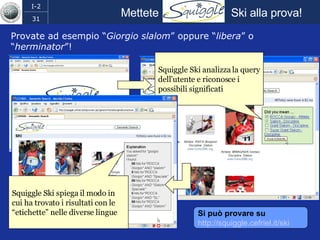



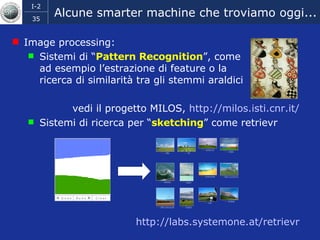
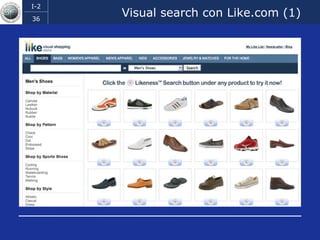
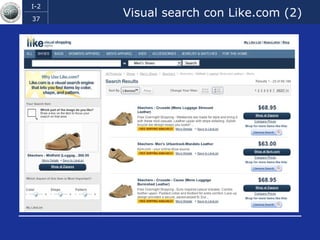

Il documento discute l'evoluzione del web semantico e dei motori di ricerca, evidenziando il divario tra il sistema educativo e il mondo del lavoro, nonché la crescente complessità della ricerca online. Viene presentata l'importanza di rendere i dati e le informazioni elaborabili dalle macchine attraverso tecnologie come il natural language processing e la riconoscimento delle immagini. È sottolineato come il miglioramento della precisione e della recall nei risultati di ricerca possa essere raggiunto tramite l'uso di metadati, gestione dell'ambiguità e aggregazione di informazioni frammentate.




























































