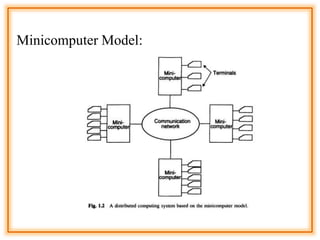
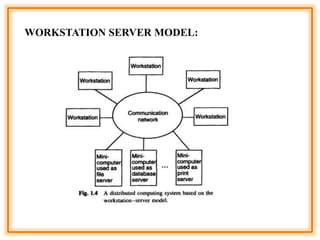
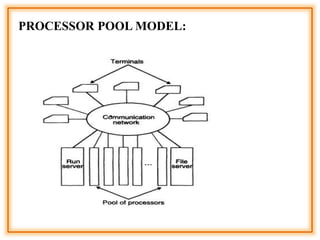
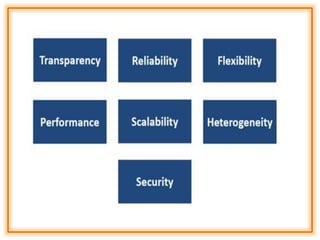
The document outlines the structure and models of distributed computing systems, classifying them into five main types: minicomputer, workstation, workstation-server, processor-pool, and hybrid models, each serving unique resource sharing and processing needs. It also discusses key concepts of transparency, reliability, flexibility, performance, scalability, security, and heterogeneity in distributed systems, emphasizing the importance of robust fault-handling mechanisms and ease of modification and enhancement. Additionally, it presents the components of Distributed Computing Environment (DCE), including thread packages, remote procedure calls, distributed time services, and various security measures.