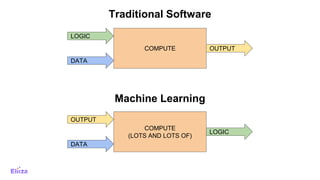
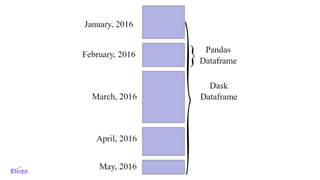
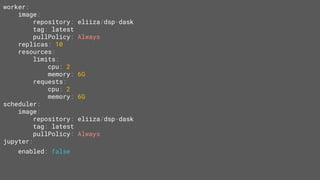
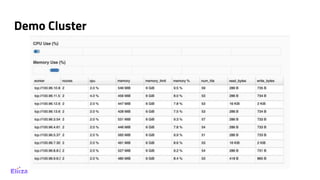
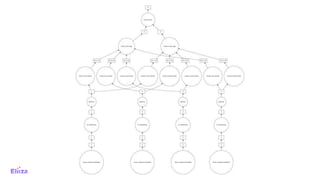
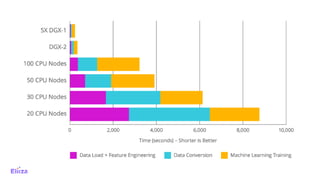
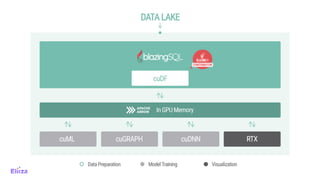
The document discusses the use of Dask with Kubernetes for distributed machine learning, highlighting Dask's compatibility with Python libraries and its efficiency in scaling data operations. It outlines architectural examples, deployment processes, and performance metrics, emphasizing the ease of orchestration with Kubernetes. Additionally, it touches on model architecture selection, hyperparameter searches, and future technologies like Rapids and TensorFlow integration.