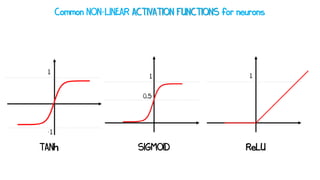
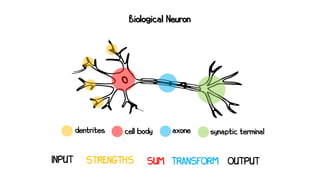
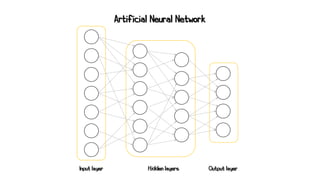
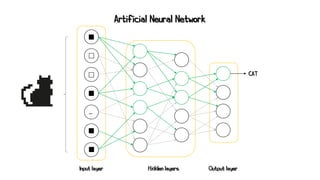
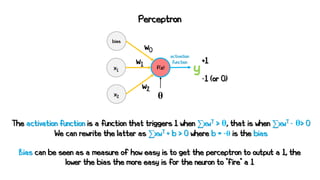
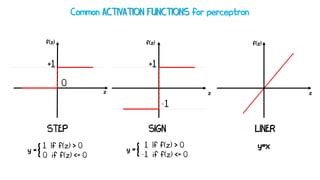
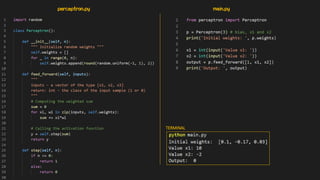
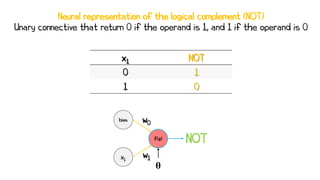
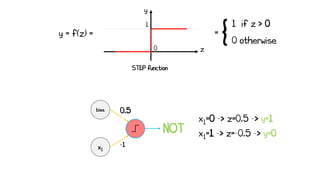
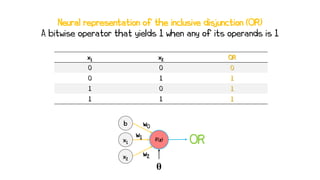
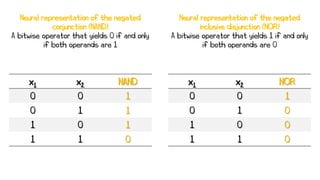
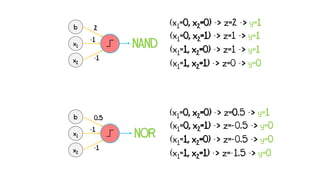
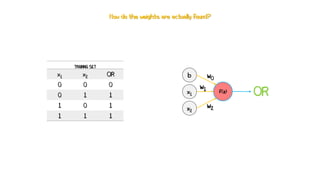
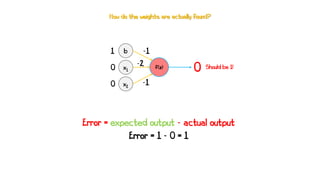
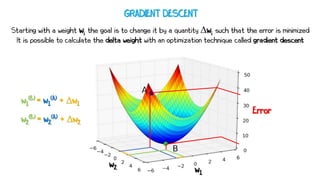
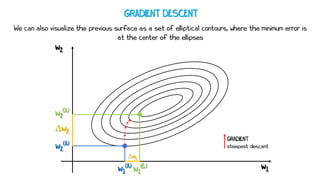
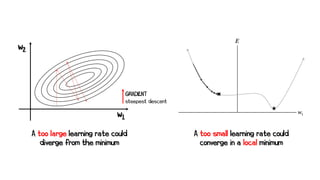
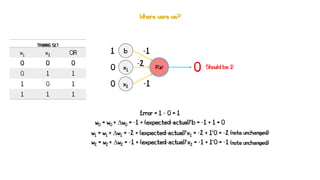
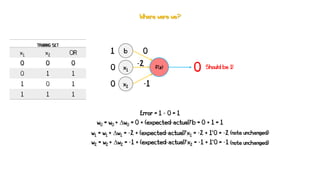
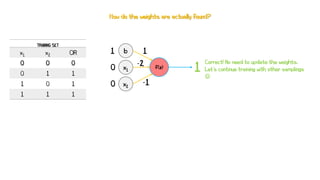
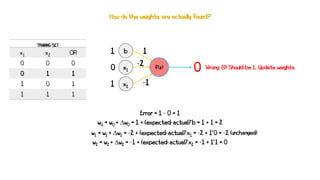
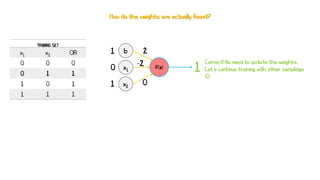
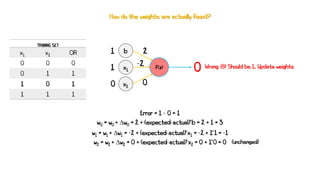
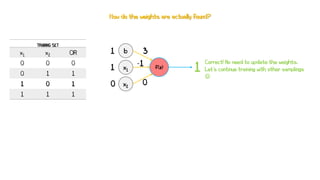
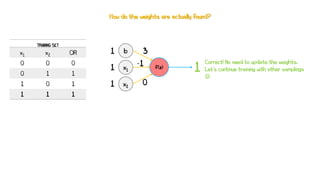
Artificial neural networks (ANNs) are a subset of machine learning algorithms inspired by the human brain. ANNs consist of interconnected artificial neurons that can learn complex patterns from data. The document introduces ANNs and perceptrons, the simplest type of ANN for binary classification. It discusses how perceptrons use weighted inputs and an activation function to make predictions. The perceptron learning rule is then explained, showing how weights are updated during training to minimize errors by calculating delta weights through gradient descent. This allows perceptrons to learn logical functions like AND, OR, and NOT from examples.



![Artificial Neuron
y = f(x·wT + b)
x = [x0, x1, …, x3] w = [w0, w1, …, wn]
If f(z) > θ then the neuron is activated and the signal is propagated
x0
f(z)
x1
xn
w0
w1
wn
…
θthreshold
activation
function
y
input
input
input
weights](https://image.slidesharecdn.com/artificialneuralnetworks-220819104231-2d3f30a4/85/Artificial-Neural-Networks-5-320.jpg)


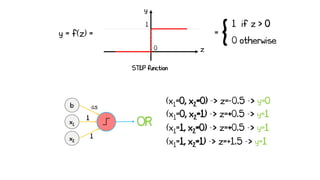









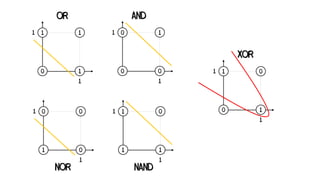
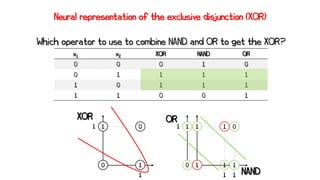
![x2
XOR
x1
1
b1
-0.5
1
-1
-1
2
y1 [OR]
1
1
b2
-1.5
y2 [NAND]
y3 [AND]](https://image.slidesharecdn.com/artificialneuralnetworks-220819104231-2d3f30a4/85/Artificial-Neural-Networks-54-320.jpg)
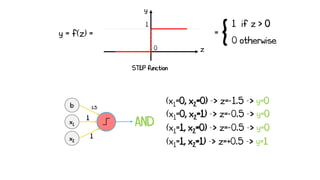
![x2
0
x1
1
b1
-0.5
1
-1
-1
2
y2 [NAND]
y1 [OR]
y3 [AND]
1
1
b2
-1.5
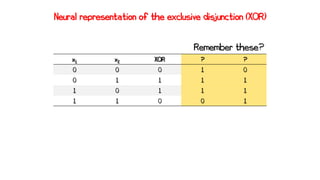
x1 = 0 x2 = 0
Neuron activated - “Fires” 1
Neuron not activated - “Fires” 0
z1 = -0.5 -> y1 = 0
z2 = 2 -> y2 = 1
z3 = -0.5 -> y3 = 0
x1 x2 XOR
0 0 0](https://image.slidesharecdn.com/artificialneuralnetworks-220819104231-2d3f30a4/85/Artificial-Neural-Networks-55-320.jpg)
![x2
1
x1
1
b1
-0.5
1
-1
-1
2
y2 [NAND]
y1 [OR]
y3 [AND]
1
1
b2
-1.5
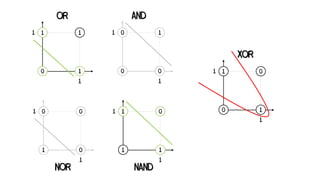
x1 = 0 x2 = 1
Neuron activated - “Fires” 1
Neuron not activated - “Fires” 0
z1 = 0.5 -> y1 = 1
z2 = 0.5 -> y2 = 1
z3 = 0.5 -> y3 = 1
x1 x2 XOR
0 0 0
0 1 1](https://image.slidesharecdn.com/artificialneuralnetworks-220819104231-2d3f30a4/85/Artificial-Neural-Networks-56-320.jpg)
![x2
1
x1
1
b1
-0.5
1
-1
-1
2
y2 [NAND]
y1 [OR]
y3 [AND]
1
1
b2
-1.5
x1 = 1 x2 = 0
Neuron activated - “Fires” 1
Neuron not activated - “Fires” 0
z1 = 0.5 -> y1 = 1
z2 = 1 -> y2 = 1
z3 = 0.5 -> y3 = 1
x1 x2 XOR
0 0 0
0 1 1
1 0 1](https://image.slidesharecdn.com/artificialneuralnetworks-220819104231-2d3f30a4/85/Artificial-Neural-Networks-57-320.jpg)
![x2
0
x1
1
b1
-0.5
1
-1
-1
2
y2 [NAND]
y1 [OR]
y3 [AND]
1
1
b2
-1.5
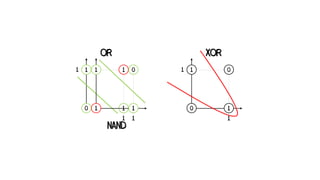
x1 = 1 x2 = 1
Neuron activated - “Fires” 1
Neuron not activated - “Fires” 0
z1 = 1.5 -> y1 = 1
z2 = 0 -> y2 = 0
z3 = -0.5 -> y3 = 0
x1 x2 XOR
0 0 0
0 1 1
1 0 1
1 1 0](https://image.slidesharecdn.com/artificialneuralnetworks-220819104231-2d3f30a4/85/Artificial-Neural-Networks-58-320.jpg)