Download to read offline














![© 2018 IBM Corporation
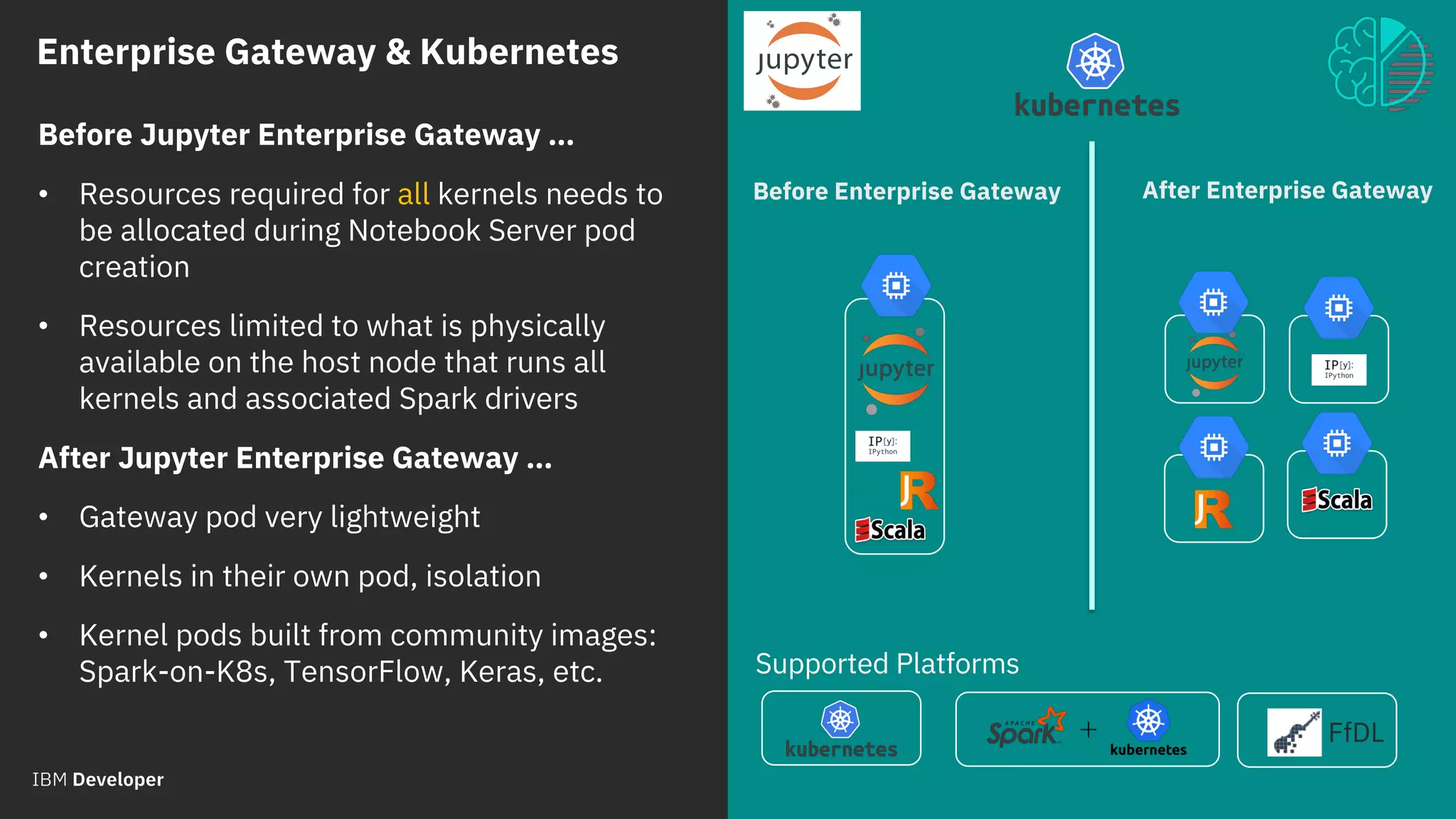
Process Proxy:
• Abstracts kernel process represented by Jupyter
framework
• Pluggable class definition identified in kernelspec
(kernel.json)
• Manages kernel lifecycle
Kernel Launcher:
• Embeds target kernel
• Listens on gateway communication port
• Conveys interrupt requests (via local signal)
• Could be extended for additional communications
{
"language": "python",
"display_name": "Spark - Python (Kubernetes Mode)",
"process_proxy": {
"class_name":
"enterprise_gateway.services.processproxies.k8s.KubernetesProcessP
roxy",
"config": {
"image_name": "elyra/kubernetes-kernel-py:dev",
"executor_image_name": "elyra/kubernetes-kernel-py:dev”,
"port_range" : "40000..42000"
}
},
"env": {
"SPARK_HOME": "/opt/spark",
"SPARK_OPTS": "--master k8s://https://${KUBERNETES_SERVICE_HOST
--deploy-mode cluster --name …",
…
},
"argv": [
"/usr/local/share/jupyter/kernels/spark_python_kubernetes/bin/run.
sh",
"{connection_file}",
"--RemoteProcessProxy.response-address",
"{response_address}",
"--RemoteProcessProxy.spark-context-initialization-mode",
"lazy"
]
}
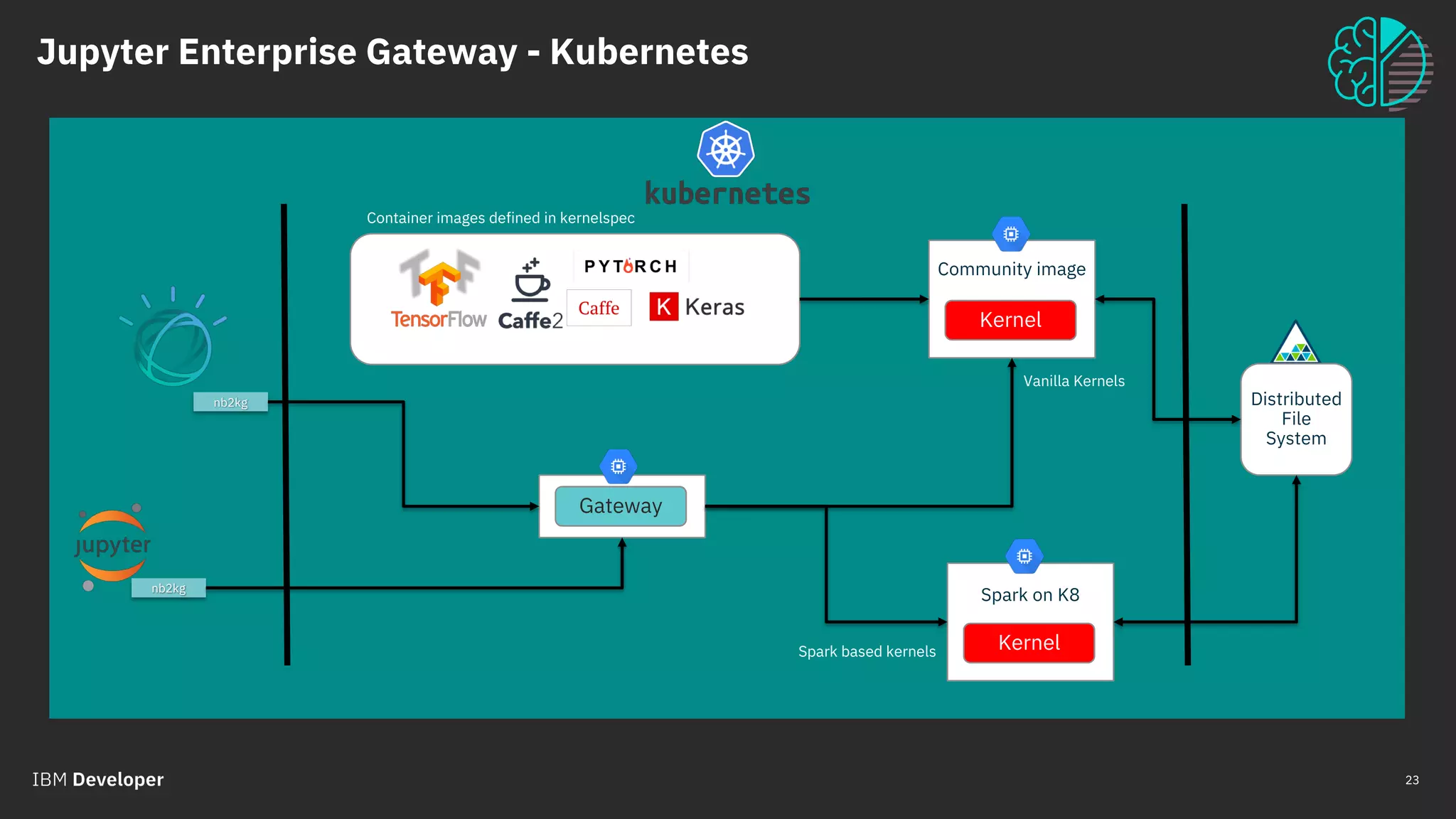
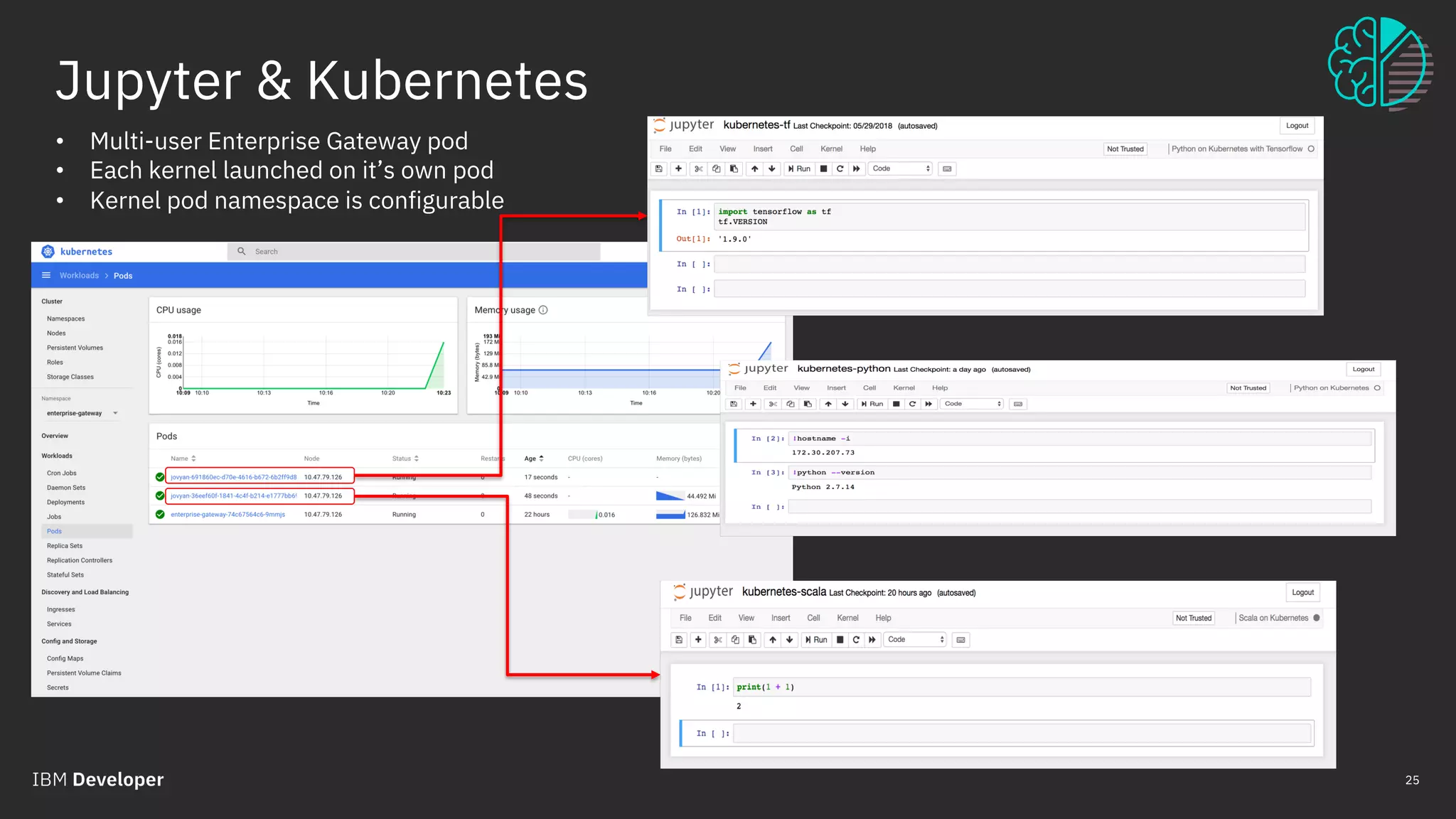
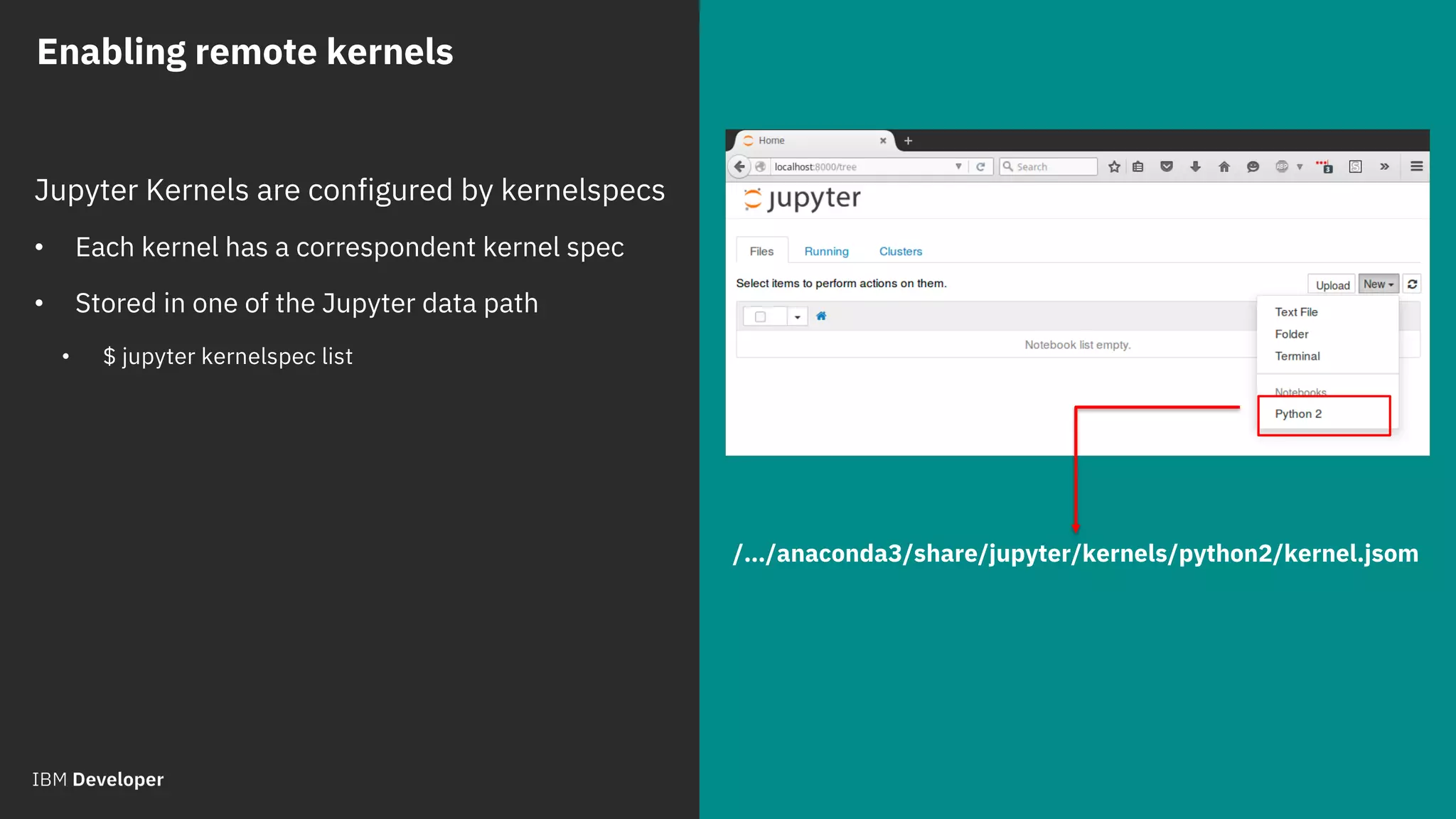
Enabling remote kernels
Process Proxies mixed with Kernel Launchers](https://image.slidesharecdn.com/scalingbigdatainteractiveworkloadsacrosskubernetesclusterberlin-190125212948/75/Luciano-Resende-Scaling-Big-Data-Interactive-Workloads-across-Kubernetes-Cluster-Codemotion-Berlin-2018-27-2048.jpg)
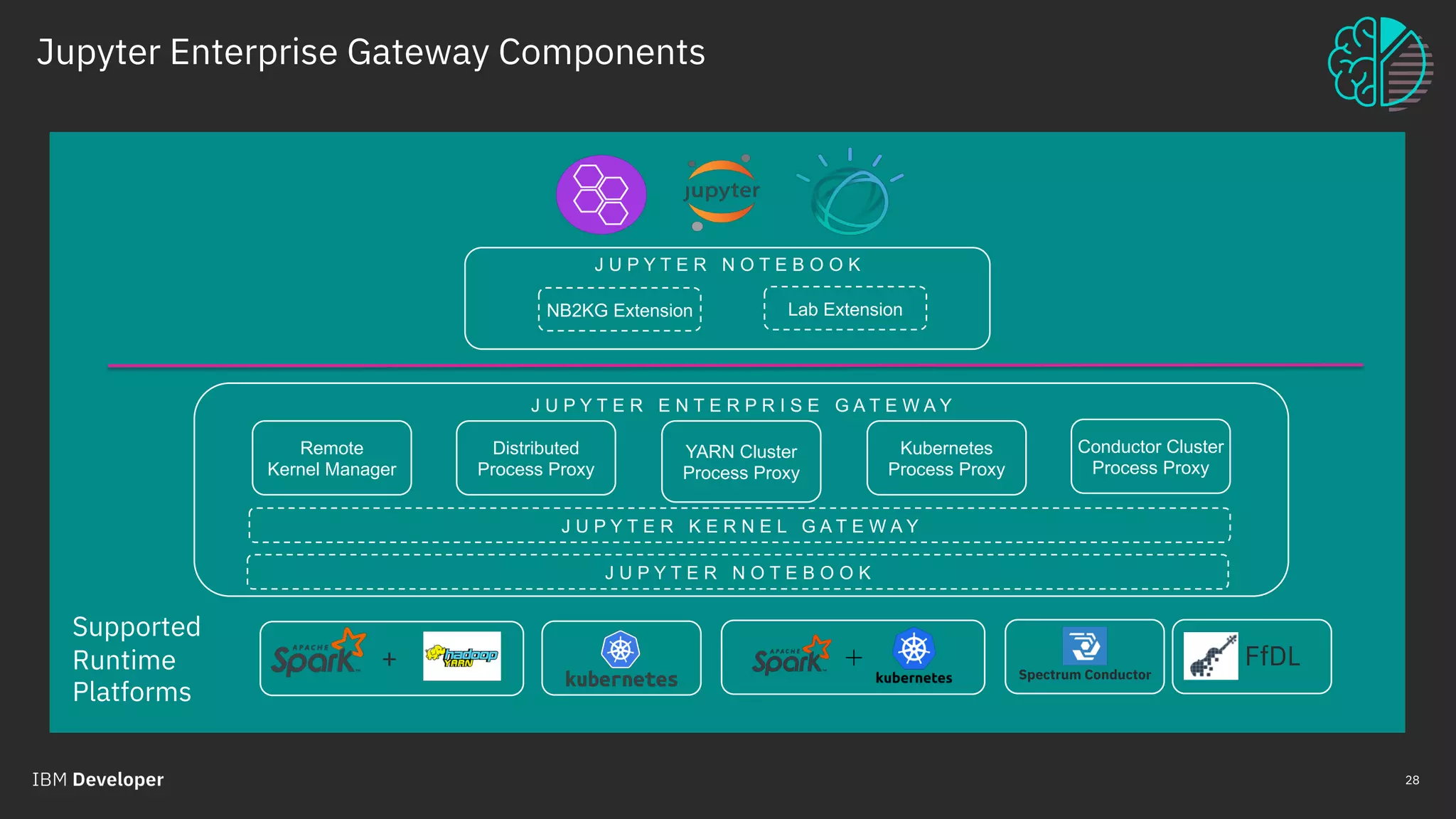

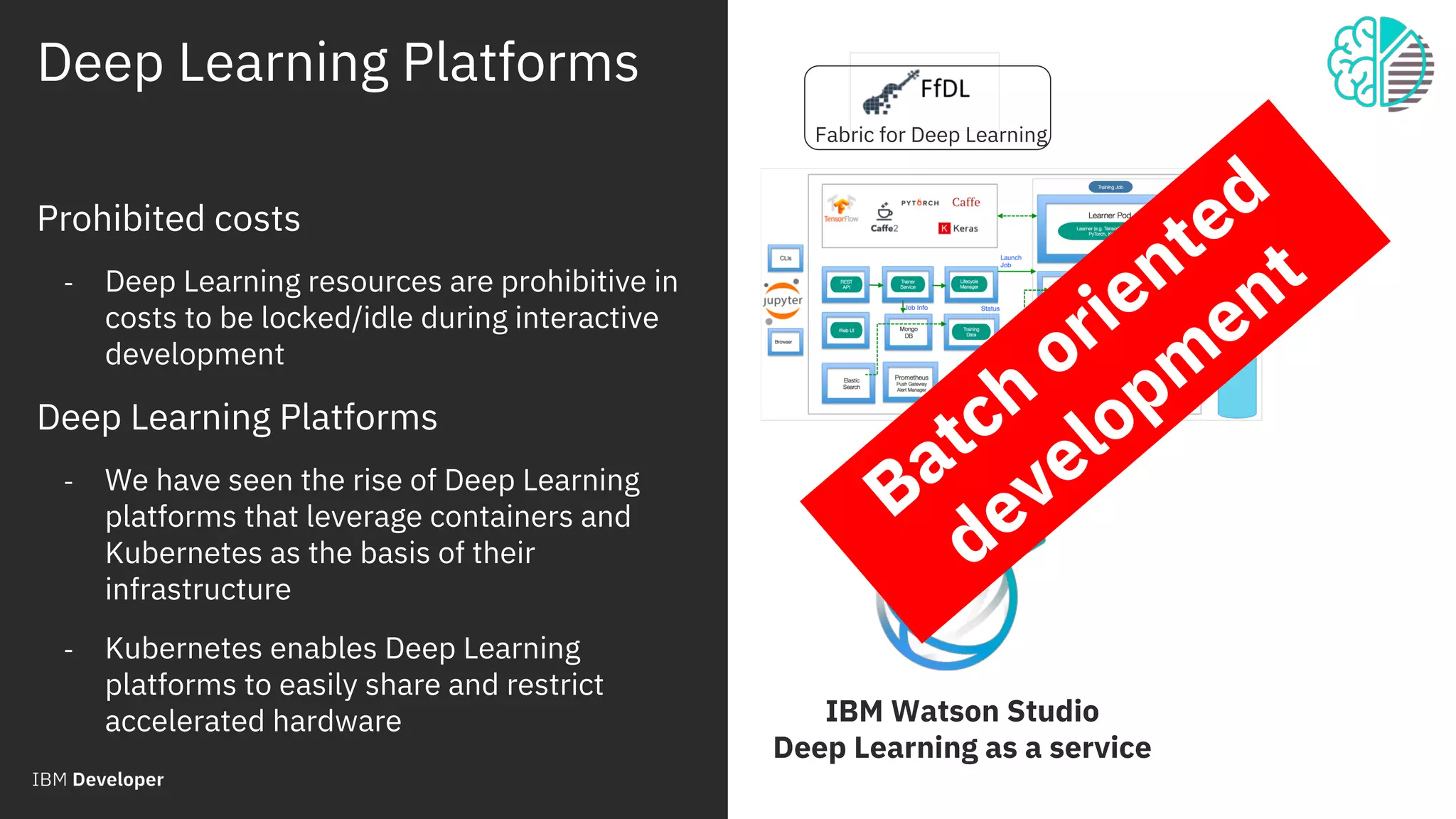
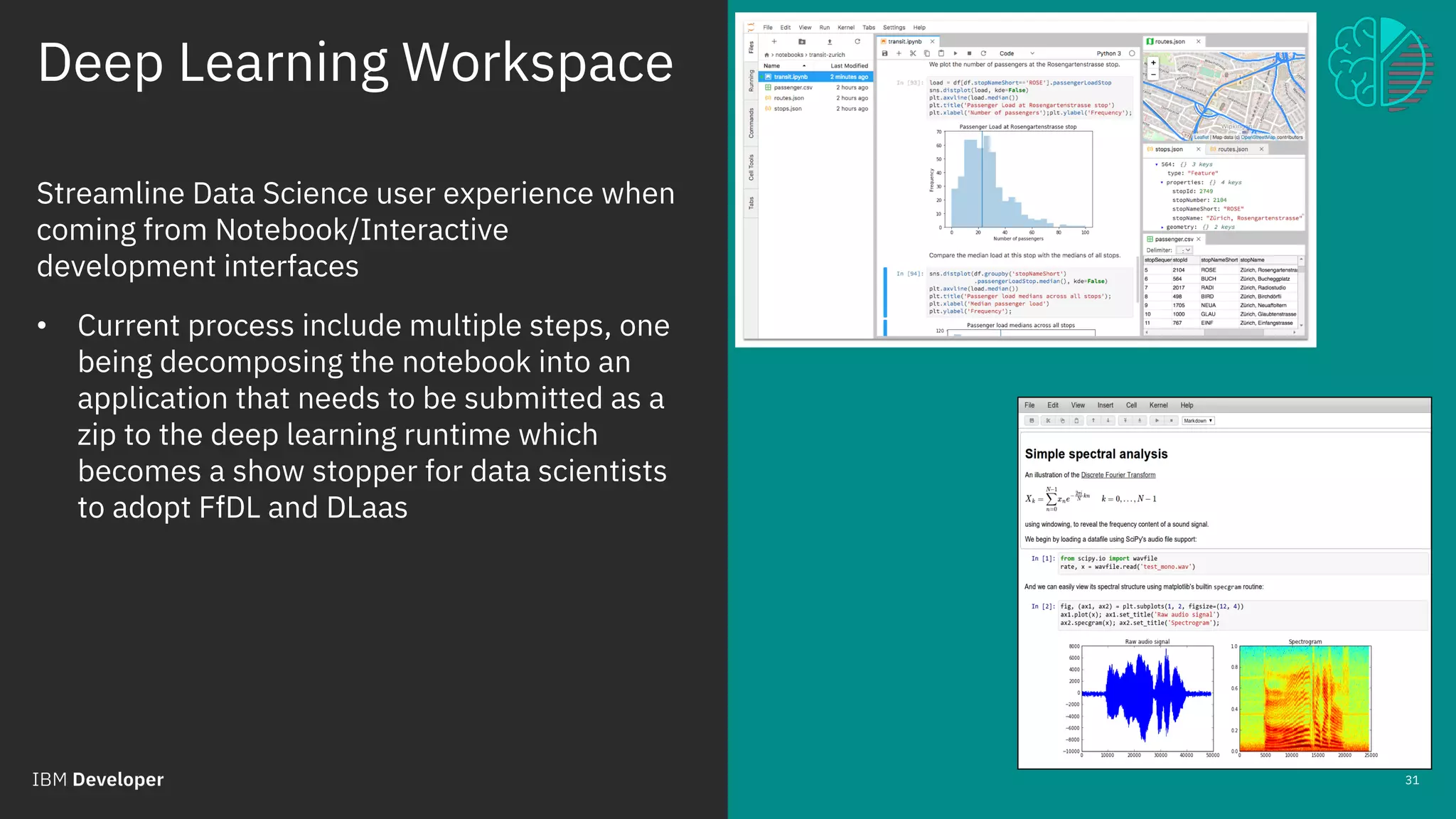
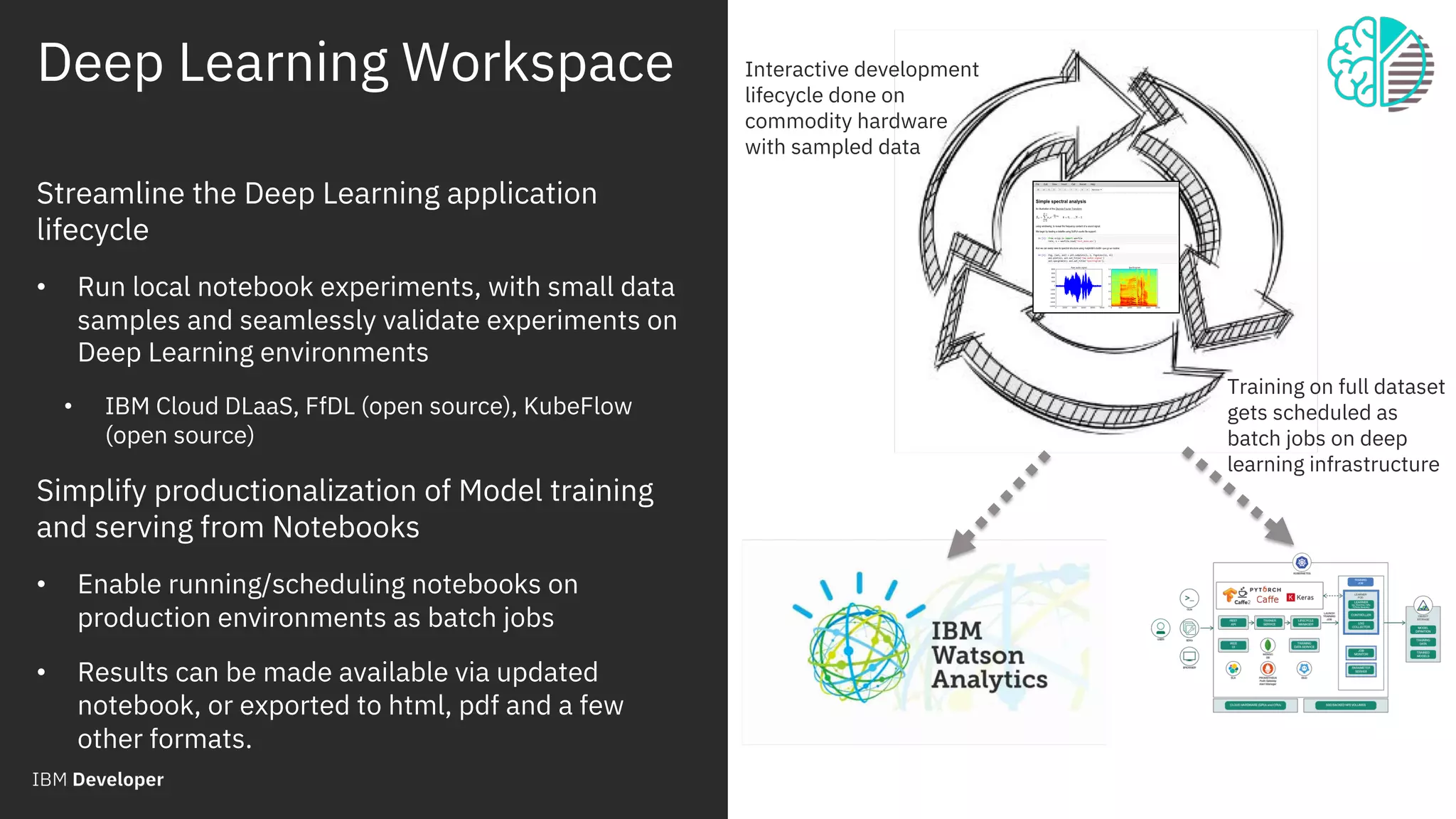

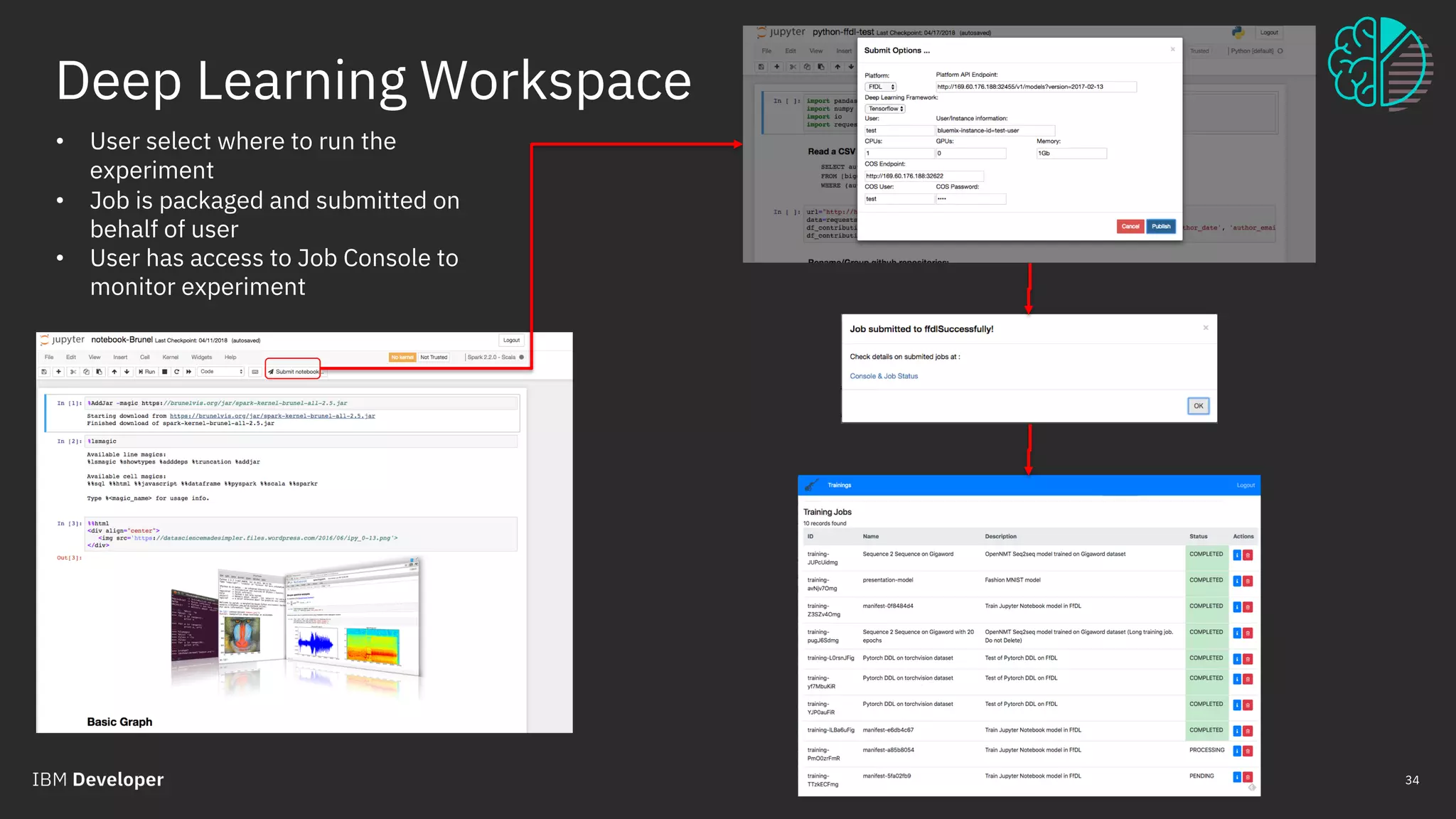



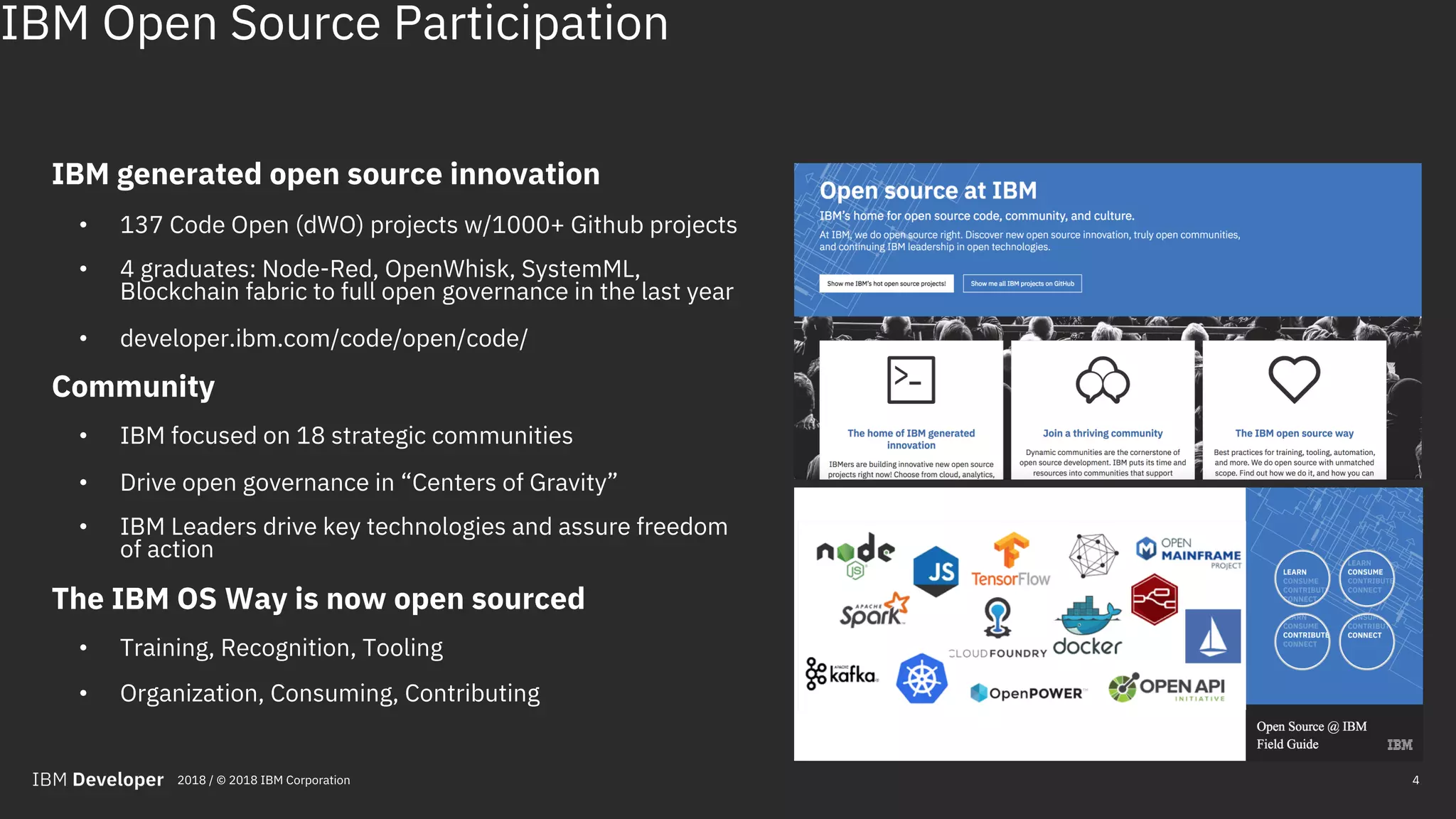
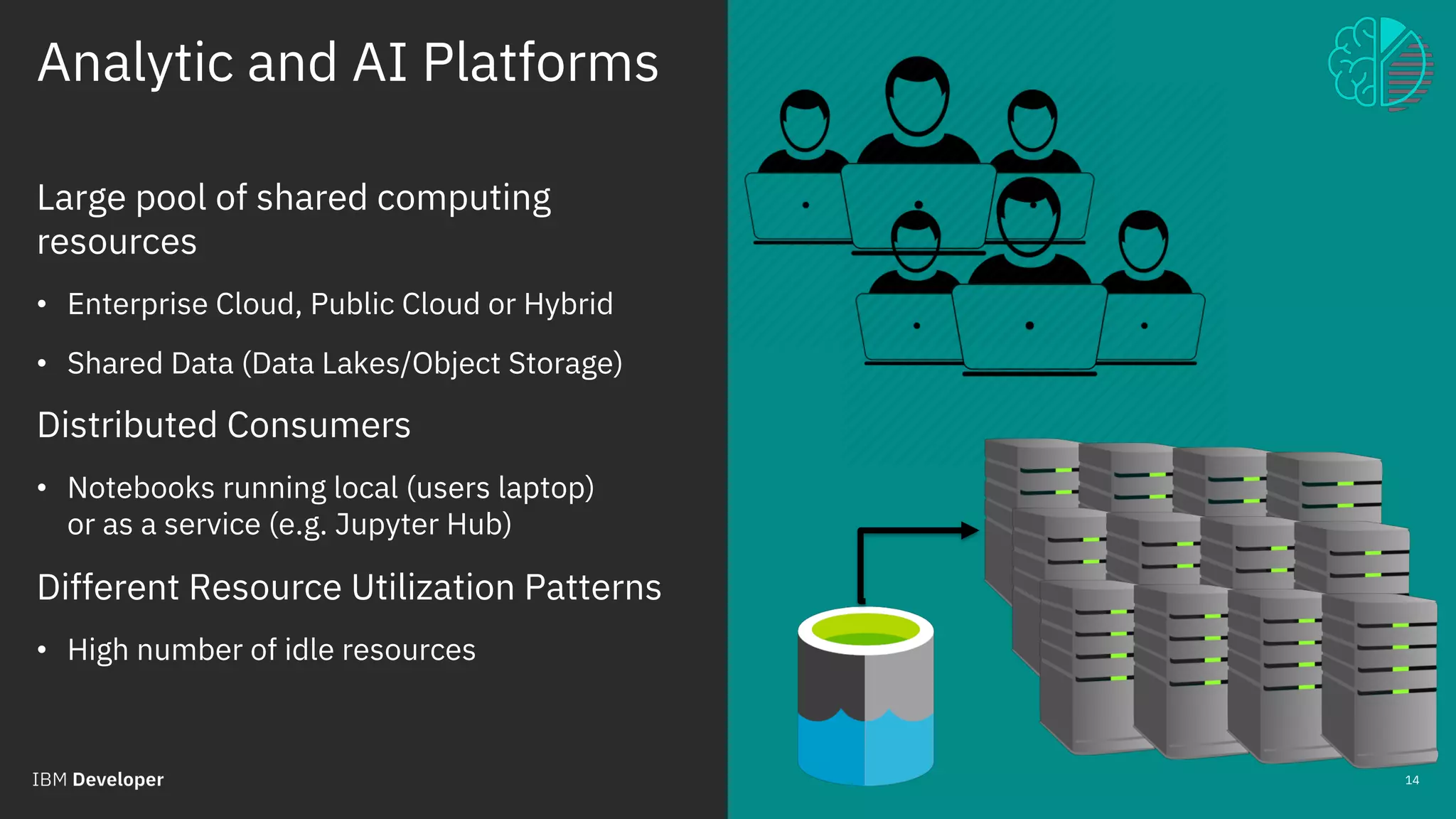
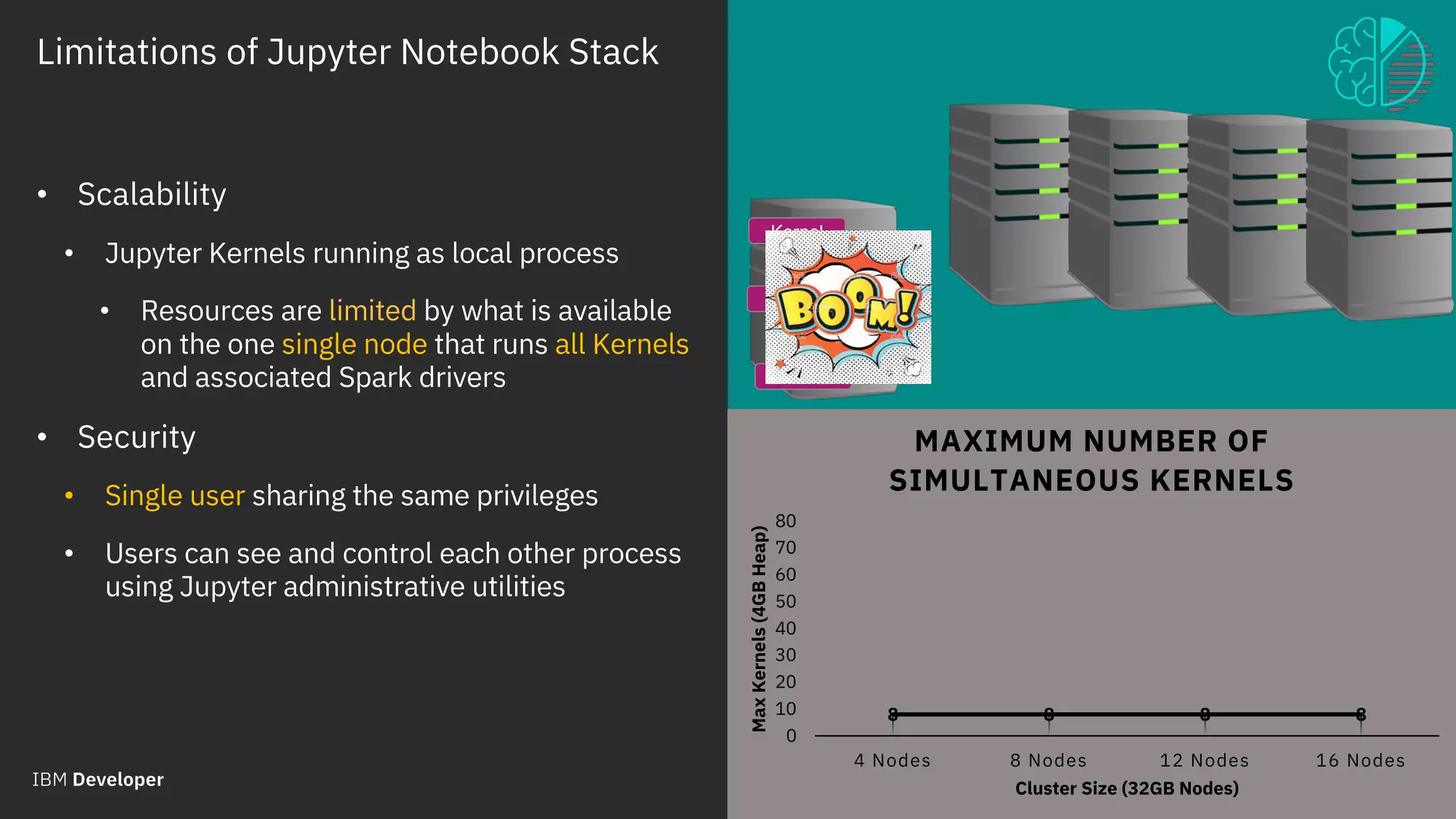
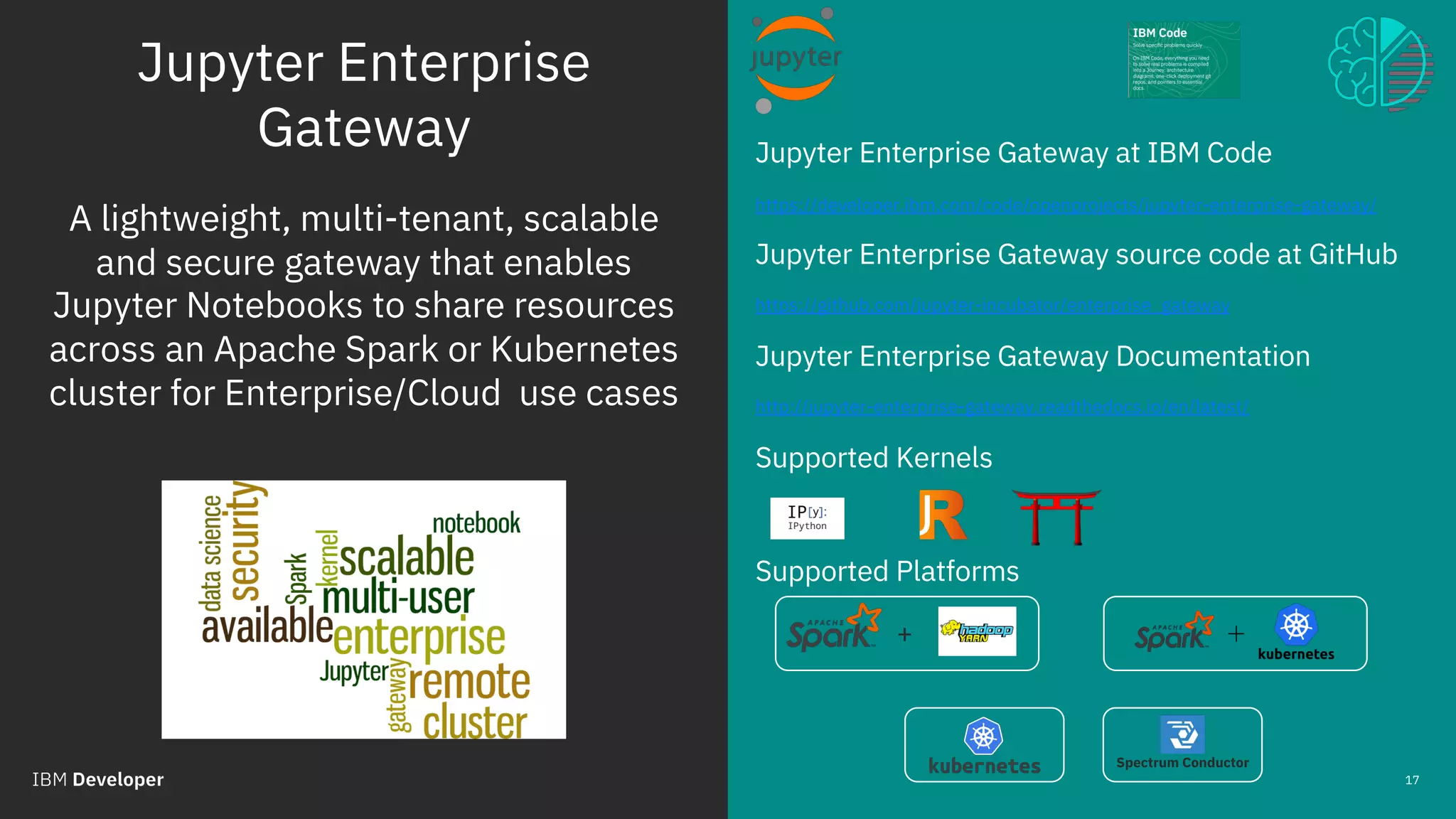
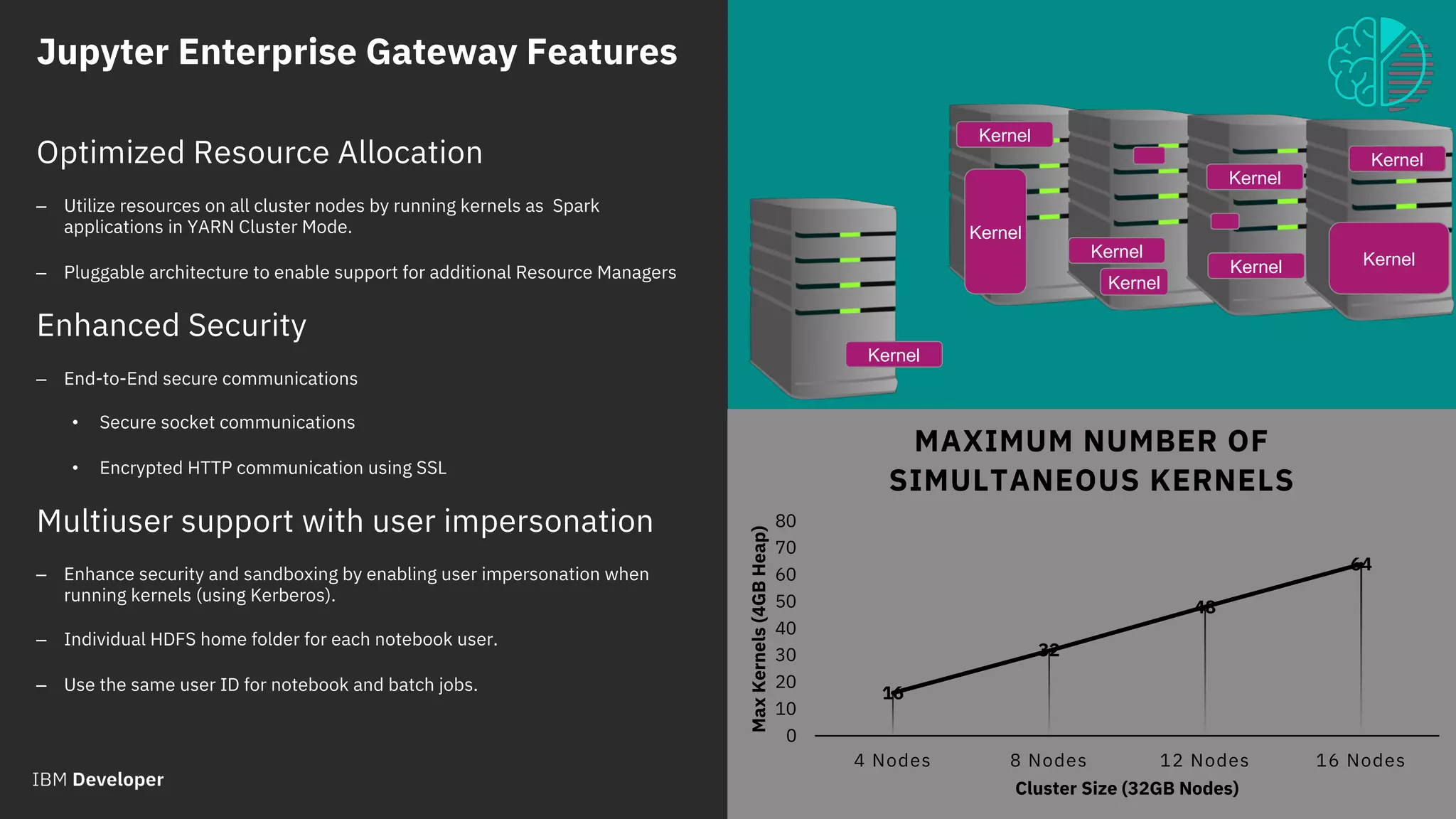
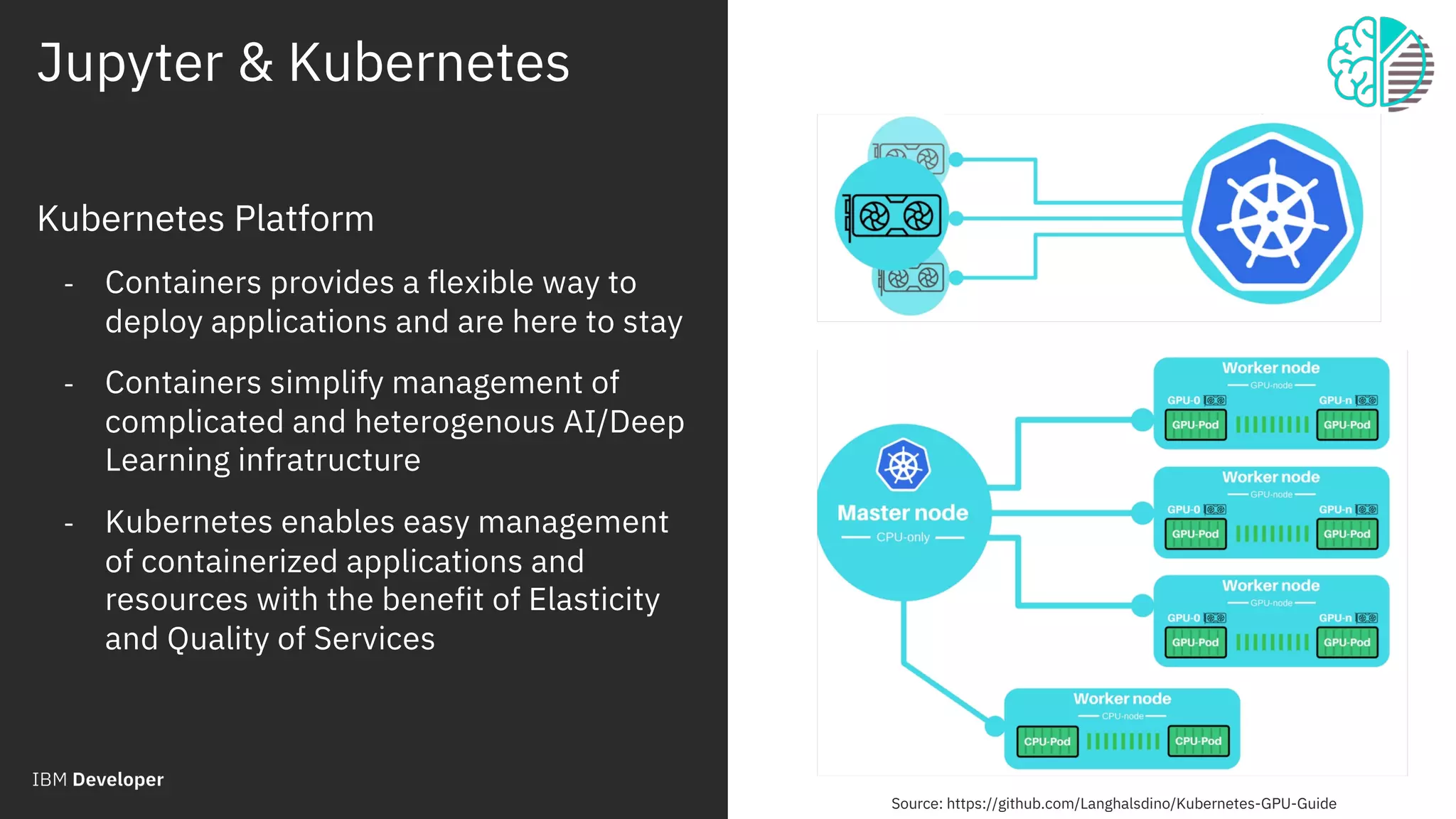
The document outlines the role of IBM in promoting open source technologies and contributions to big data and AI workloads utilizing Kubernetes and Jupyter Notebooks. It discusses the challenges faced in resource utilization, scalability, and security when running interactive workloads, and introduces the Jupyter Enterprise Gateway as a solution for managing kernels across clusters. IBM's commitment to streamline the development lifecycle for deep learning applications is emphasized through the integration of cloud services and innovative platforms.














































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







