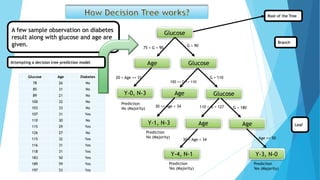
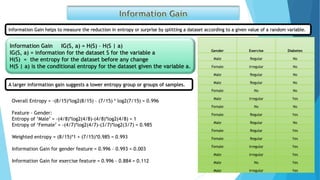
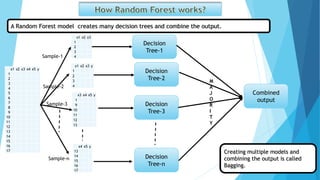
The document presents data on glucose levels, ages, and diabetes status for 15 individuals. It then shows how this data could be used to build a decision tree model to predict diabetes status based on glucose level and age ranges. The decision tree is split into branches and leaves based on thresholds for glucose and age. For example, one node examines individuals aged 30-34 and splits them based on glucose levels of 110-127 or greater than 180. The document also discusses concepts like information gain, entropy, and gini impurity that are used to determine the optimal splits in decision trees. It introduces the random forest technique of creating many decision trees and combining their predictions.