Downloaded 51 times












![furthermore; Activation
Bus daemon can be instructed to start clients automatically when needed.
To achieve that describe client in a service file.
Default path: /usr/share/dbus-1/services/*.service
For example: client program /usr/local/bin/bankcounter can be run to provide
well-known bus names com.bigmoneybank.Deposits and
com.bigmoneybank.Withdrawals.
# Sample bankcounter.service file
[D-BUS Service]
Names=com.bigmoneybank.Deposits;
com.bigmoneybank.Withdrawals
Exec=/usr/local/bin/bankcounter
13](https://image.slidesharecdn.com/xexlkb8suovrulil7jbq-signature-cdffdc803d94dd9e0a1953da48b8d389847d1ce8565643ae7f259f48f4efa413-poli-160203223456/85/D-bus-basics-13-320.jpg)







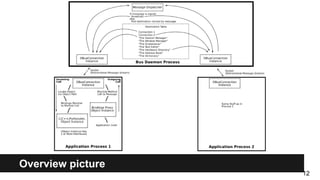
D-Bus is a message bus system that allows applications to communicate locally within a single machine. It provides inter-process communication (IPC) and allows services to publish data to applications via method calls, signals or properties. Key aspects include objects, proxies, methods, signals and interfaces that define how processes connect and exchange messages through the D-Bus daemon. It is commonly used on desktop systems but is not well-suited for internet or distributed applications.



































































