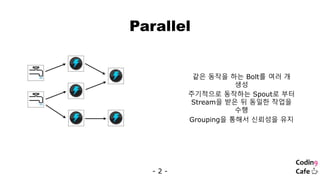
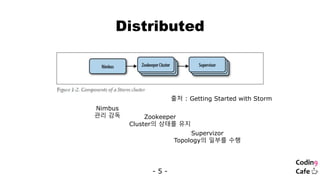
Distributed
- 5 -
출처: Getting Started with Storm
Nimbus
관리 감독 Zookeeper
Cluster의 상태를 유지
Supervizor
Topology의 일부를 수행
7.
Distributed
- 6 -
-How to make Storm Cluster?
>> Nimbus 설정
>> Zookeeper 설정
>> Supervisor 설정
- Remote Mode
>> StormSubmitter
- DRPC Topologies
>> Distributed Remote Procedure Calls
- Next Week
>> 분산 처리 환경 구축해보기






![[오픈소스컨설팅]Kafka message system 맛보기](https://cdn.slidesharecdn.com/ss_thumbnails/kafkamessagesystem-180730044904-thumbnail.jpg?width=640&height=640&fit=bounds)


![[넥슨] kubernetes 소개 (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/gcdkubernetes-190419130148-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[241] Storm과 Elasticsearch를 활용한 로깅 플랫폼의 실시간 알람 시스템 구현](https://cdn.slidesharecdn.com/ss_thumbnails/83713-150915040003-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




![[김태우] Simplechat using firebase](https://cdn.slidesharecdn.com/ss_thumbnails/simplechatusingfirebase-160726115004-thumbnail.jpg?width=640&height=640&fit=bounds)
![[김태우] 한국의 태초마을 유람기](https://cdn.slidesharecdn.com/ss_thumbnails/random-160720025234-thumbnail.jpg?width=640&height=640&fit=bounds)
![[김태우] Soscon 후기](https://cdn.slidesharecdn.com/ss_thumbnails/soscon-151103093927-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Taewoo Kim] Real-Time Analytics with Apache Storm](https://cdn.slidesharecdn.com/ss_thumbnails/storminudacity-150318040645-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




