Master Databricks with AccentFuture! Learn data engineering, machine learning, and analytics using Apache Spark. Gain hands-on experience with labs, real-world projects, and expert guidance to accelerate your journey to data mastery.
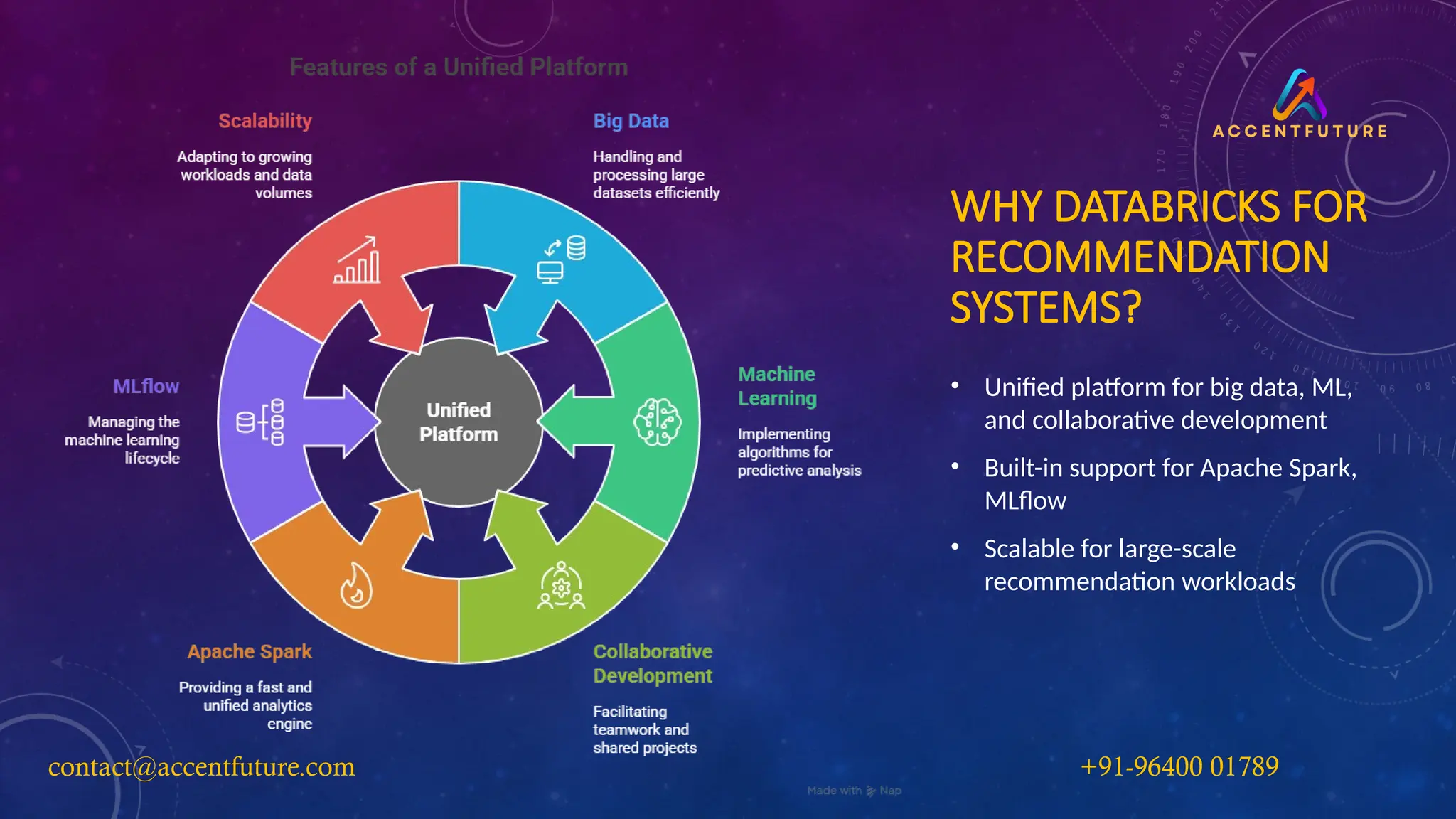
WHY DATABRICKS FOR
RECOMMENDATION
SYSTEMS?
•Unified platform for big data, ML,
and collaborative development
• Built-in support for Apache Spark,
MLflow
• Scalable for large-scale
recommendation workloads
contact@accentfuture.com
+91-96400 01789
4.
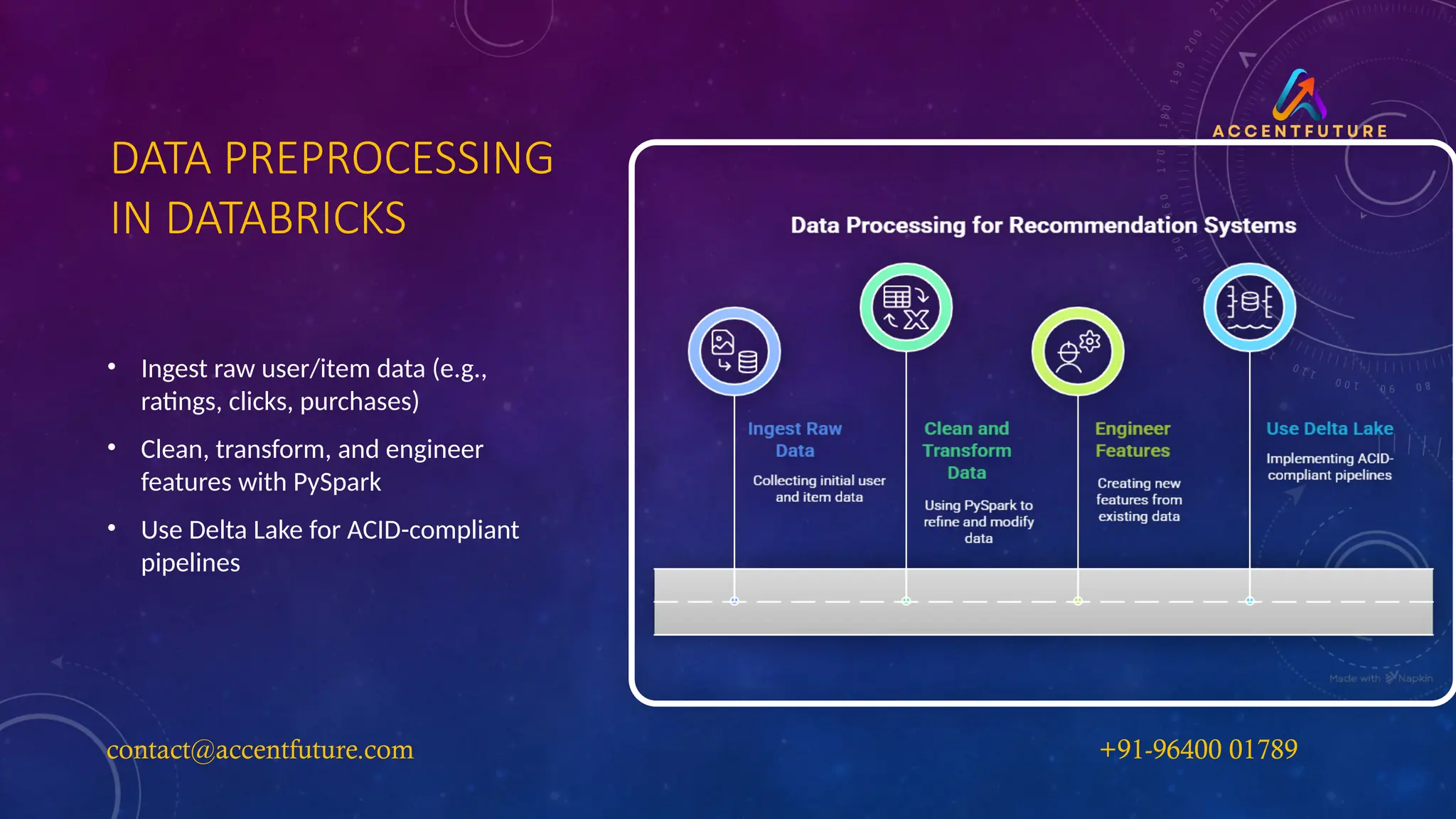
DATA PREPROCESSING
IN DATABRICKS
•Ingest raw user/item data (e.g.,
ratings, clicks, purchases)
• Clean, transform, and engineer
features with PySpark
• Use Delta Lake for ACID-compliant
pipelines
contact@accentfuture.com
+91-96400 01789
5.
COLLABORATIVE FILTERING WITHALS
• Matrix Factorization using Alternating Least Squares (ALS)
• ALS in PySpark MLlib
• Example: Movie recommendation model
contact@accentfuture.com
+91-96400 01789
6.
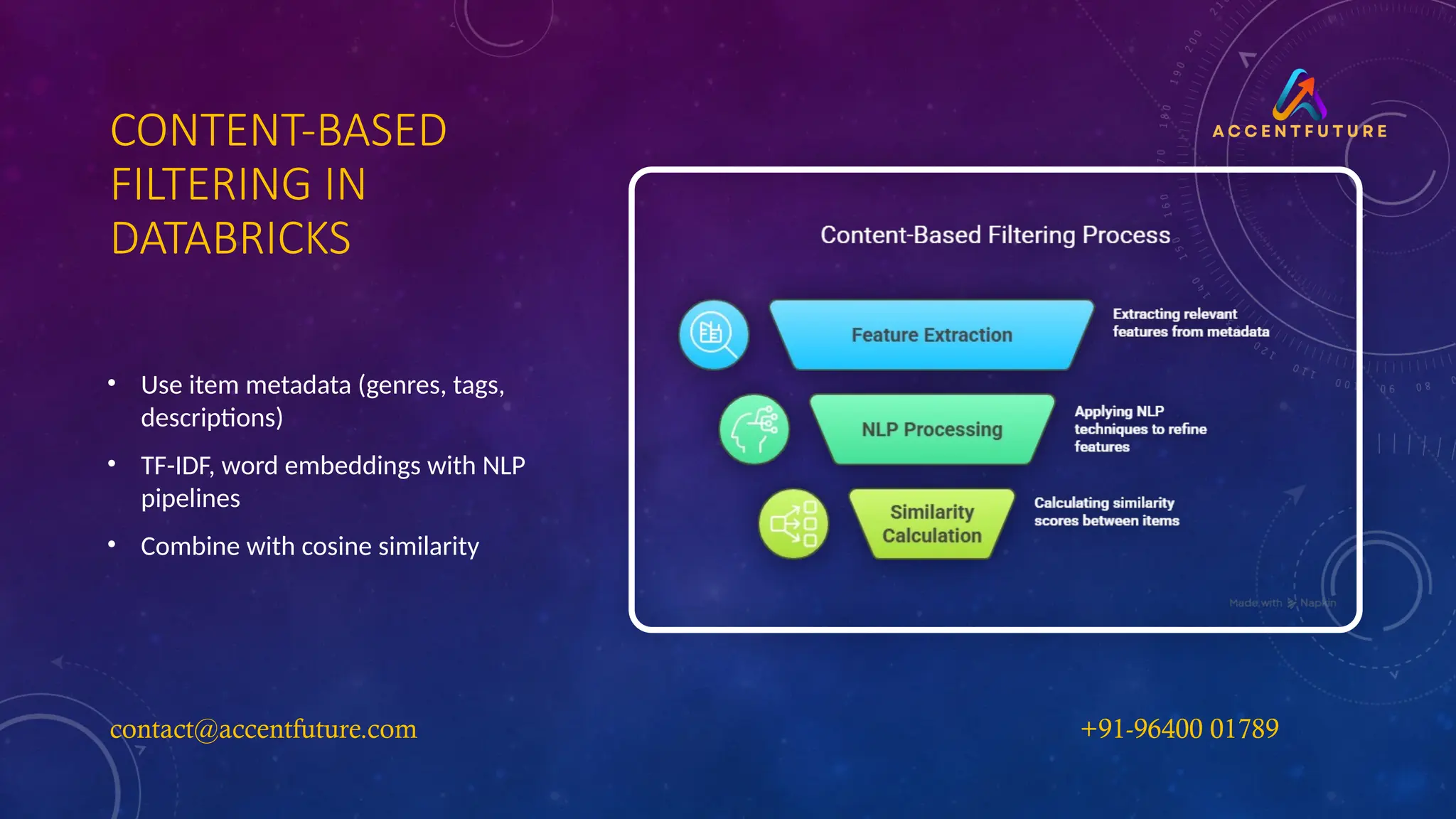
CONTENT-BASED
FILTERING IN
DATABRICKS
• Useitem metadata (genres, tags,
descriptions)
• TF-IDF, word embeddings with NLP
pipelines
• Combine with cosine similarity
contact@accentfuture.com
+91-96400 01789
7.
BUILDING A HYBRIDRECOMMENDATION SYSTEM
COMBINE COLLABORATIVE
AND CONTENT-BASED SCORES
WEIGHTED HYBRID OR
MODEL-BASED HYBRID
USE MLFLOW FOR
EXPERIMENT TRACKING
contact@accentfuture.com
+91-96400 01789
8.
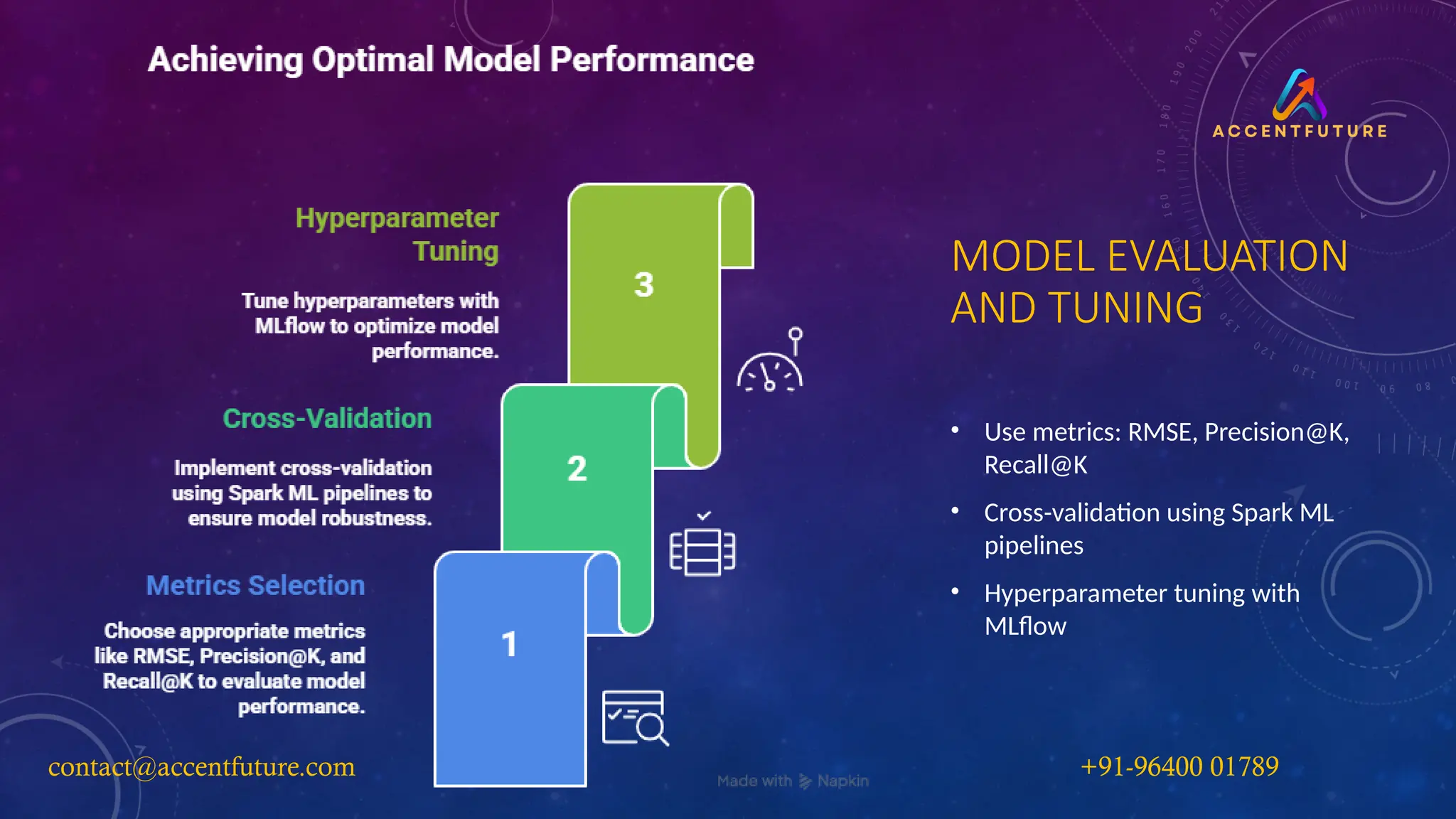
MODEL EVALUATION
AND TUNING
•Use metrics: RMSE, Precision@K,
Recall@K
• Cross-validation using Spark ML
pipelines
• Hyperparameter tuning with
MLflow
contact@accentfuture.com
+91-96400 01789
9.
LEARN DATABRICKS WITHACCENTFUTURE
• Join our Databricks Online Training Program
• Hands-on projects including recommendation engines
• Master PySpark, MLlib, Delta Lake, MLflow
• 📧 contact@accentfuture.com
• 🌐 AccentFuture
• 📞 +91-96400 01789