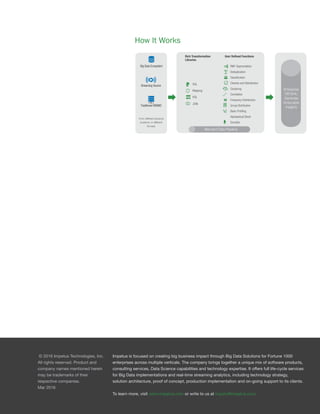
Data blending allows you to combine data from various sources and formats into a single data set for comprehensive analysis. It provides automated tools to access, integrate, cleanse, and analyze data faster and more accurately than traditional methods. The best data blending solutions offer interoperability, flexibility, and automated blending capabilities while delivering fast, secure data preparation.